
一、引言
最近在看下一代大规模 AI 数据中心的建设方案,比如 Vera Rubin NVL72/Ultra Rubin NVL144、LPX、CMX 等。在做建模和资源规划时,越来越强烈地感受到一个常被低估的变量:Agentic 应用的快速发展以及模型架构的持续演进,正在重新定义 KV-Cache 的规模、形态和传输方式,进而深刻影响 AI Infra 的设计边界。
训练阶段决定了模型的能力上限,推理阶段尤其是 KV-Cache 的存储、加载、共享与路由越来越直接地决定了系统的成本结构、吞吐上限以及最终的用户体验。这个变化不只发生在模型层,也在服务架构、内存/存储层级、网络互联和机房规划层面同时发生。
最近正好看到的一些和 KV-Cache 强相关的工作,本文中笔者从模型架构、应用场景和基础设施三个角度进行总结。本文除了讨论“KV-Cache 大不大”之外,也进一步讨论当 KV-Cache 的特性发生变化后,AI Infra 的服务形态和硬件选型会被如何重新改写。(PS:没想到本文发布不到两天时间 DeepSeek V4 就发布了,其核心的 KV Cache 压缩思路也和本文中的介绍不谋而合。)
相关工作可以参考笔者之前的文章:
-
全面解析 NVIDIA 最新硬件:Vera/Rubin/Rubin Ultra/NVL72/NVL144/LPX 等 -
NVIDIA GTC2026 详细解读和分析 -
DeepSeek DualPath 论文详细解读 -
2 万字总结:全面梳理大模型 Inference 相关技术 -
简单聊聊 NVIDIA 最新的 Vera Rubin NVL144 CPX 系统 -
分而治之:全面解析分布式分离 Inference 系统
二、不同模型架构
2.1 Attention 机制
2.1.1 Softmax Full Attention
如下图所示,Attention 中影响算术强度和 KV Cache 规模有两个关键因素:Attention 里 K 和 V 被多少个 Q 共享,以及 K 和 V 是否共享(假设 FP8 格式存储,Hidden Dim 为 H,n 个 Head,Head Dim 为 d=H/n,GQA 中有 g 个 Group):
MHA:Q 和 K/V 对应关系为 1:1,每个 Token 每层的 KV 大小为 2H。
GQA:Q 和 K/V 对应关系为 gq:1(每个 Group 里有 gq 个 Q, g=n/gq),每个 Token 每层的 KV 大小为 2H/gq=2gd。
MQA:Q 和 K/V 对应关系为 hq:1(有 hq 个 Query Head,hq>=gq),每个 Token 每层的 KV 大小为 2d。
MFA:等效于 MQA,每个 Token 每层的 KV 大小为 2C(C 是隐空间维度)。
MLA:K 和 V 共享,每个 Token 每层的 KV 大小为 C+dr(C 是隐空间维度,dr 表示 RoPE 编码维度)。
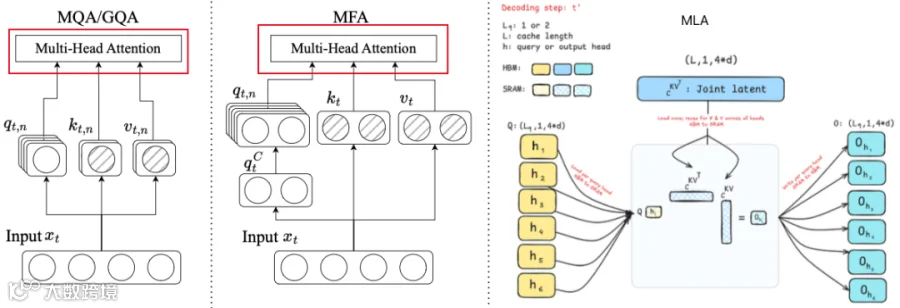
对于 Softmax 类型 Attention,总 KV Cache 大小与序列长度 S 和模型层数 L 成正比。也就是说, 在不做额外压缩或稀疏化的情况下,KV-Cache 大小可以写为(其中 B 表示数据类型字节数,FP16 为 2 Byte,FP8 为 1 Byte,FP4 为 0.5 Byte):
S * L * (单层单 Token 的 KV-Cache) * B
在 Softmax Attention 机制中,KV-Cache 的存储大小与 Decoding 阶段加载的 KV-Cache 大小相同。
2.1.2 Sparse Attention - SWA
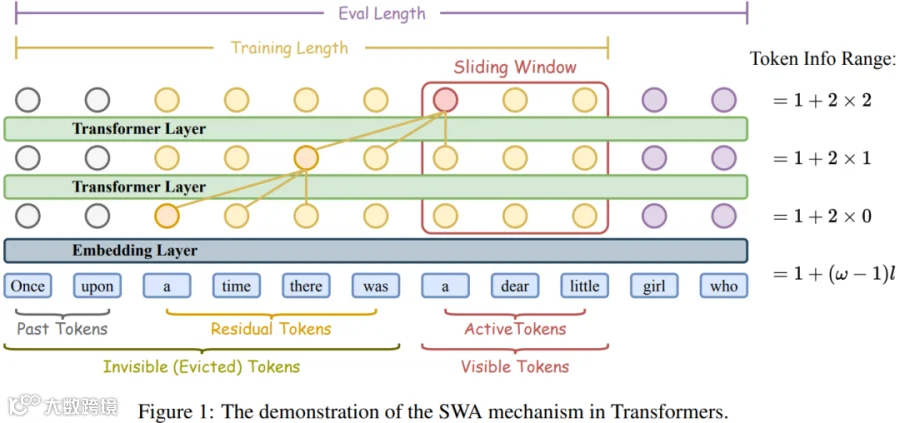
滑动窗口注意力(Sliding Window Attention,SWA)的核心思想是:在做 Attention 计算时,当前 Token 不再关注之前的全部 Token,而是只关注一个有限窗口内的 Token。除此之外,可能也会关注额外的 Sink Token([2309.17453] Efficient Streaming Language Models with Attention Sinks [1])。以最基本的 SWA 为例,假设窗口大小为 W,则不论底层是 MHA、GQA 还是 MLA,KV-Cache 的有效存储和加载规模都会被窗口大小 W 所限制(存储大小和加载大小):
S * W * (单层单 Token 的 KV-Cache) * B
2.1.3 Sparse Attention - DSA
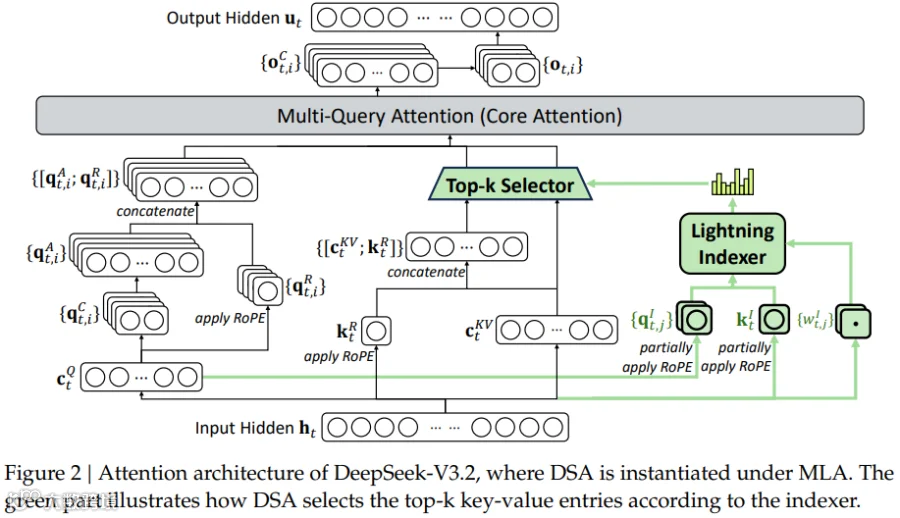
DeepSeek 在 [2512.02556] DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models [2] 中引入了 DSA 机制。其核心思路是在 MLA 的基础上进一步叠加 Sparse 机制,每次进行 Attention 之前,先通过 Lightning Indexer 从长序列中筛选出 Top-k Token,再只对这些候选 Token 执行后续的 Attention 计算。
Indexer 是一个 128 维向量,所以每个 Token 在每层还会有一个 128 维的 Indexer Cache(存储和加载)。这也意味着 DSA 并不是“零成本稀疏化”,索引阶段仍然会引入额外的计算和存储开销。
通过 Top-k(2048)Selector 后,只用加载 2048 个 Token 的 MLA Cache 进行 Attention 计算即可。
不管序列长度是多少(> 2048),每层都会加载固定的 2048 个 MLA Cache。
由于任何一个 Token 都可能被选中,所以还是要存储所有的 MLA Cache。
计算复杂度为 O(K*L),大幅降低。
PS:由于 MLA Cache 的维度为 576,因此当序列长度大于 576/128*2048=9K 时,Indexer Cache 的加载开销反而大于 MLA Cache。
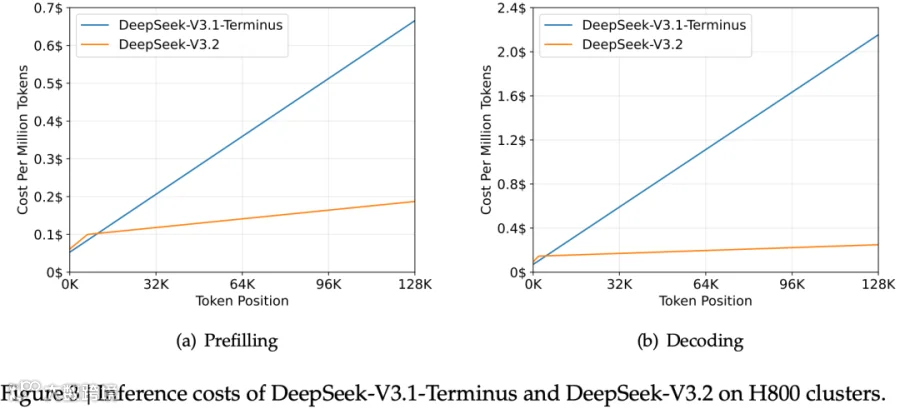
在序列较长的情况下,DSA 可以显著降低 MLA Cache 的加载量和 Attention 计算量,从而降低 Inference 成本。但同时也要意识到,它是用索引阶段的额外开销去换取后续 Attention 阶段的降本。
2.1.4 Linear Attention - GatedDeltaNet
阿里在 Qwen3.5 系列模型中引入 [2412.06464] Gated Delta Networks: Improving Mamba2 with Delta Rule [3],同样可以大幅降低对 KV Cache 的依赖。GatedDeltaNet 层维护两个固定大小的 State(不随序列长度增长),以 Qwen3.5-122B-A10B 为例:
Recurrent State(主状态,DeltaNet 核心记忆矩阵):
Shape: (linear_num_value_heads, linear_key_head_dim, linear_value_head_dim) = (64, 128, 128) 。
元素数:64 × 128 × 128 = 1,048,576。
一般以 Float32 格式存储。
每层的大小:1,048,576 × 4 bytes = 4 MB。
Conv State(卷积辅助状态,用于 gate/delta 计算前的 short conv):
Shape: (linear_num_value_heads × linear_value_head_dim, linear_conv_kernel_dim) = (8192, 4) 。
元素数:8192 × 4 = 32,768。
一般以 Float32 格式存储。
每层的大小:32,768 × 4 bytes ≈ 0.125 MB。
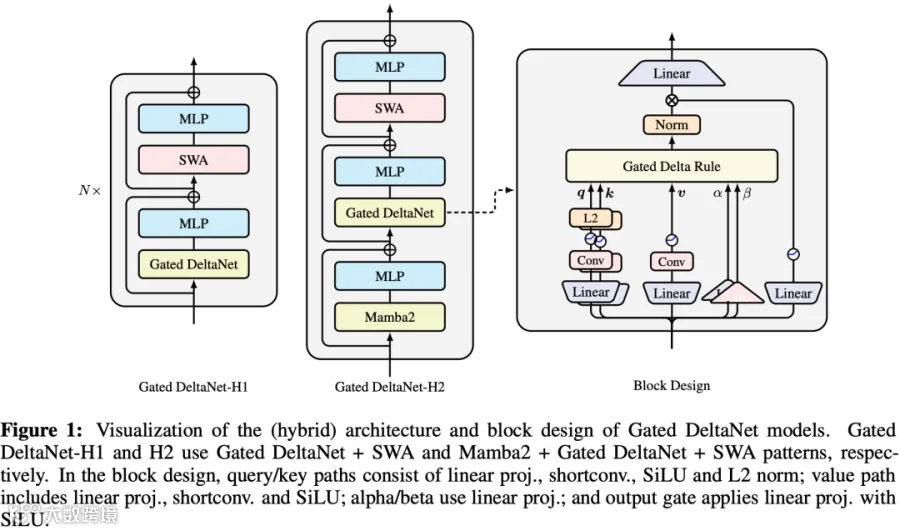
2.1.5 Linear Attention - Lightning Linear
蚂蚁在 Ling 系列模型中使用了 Lightning Linear Attention([2510.19338] Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning [4]),相比 GatedDeltaNet 更加简单,只用维护一个固定大小的 State(不随序列长度增长),以 Ring-2.5-1T 为例:
Recurrent State(主状态,核心记忆矩阵):
Shape:(num_kv_heads_for_linear_attn, head_dim, head_dim) = (64, 128, 128)
元素数:64 × 128 × 128 = 1,048,576 个元素。
一般以 Float32 格式存储。
每层的大小:1,048,576 × 4 bytes = 4 MB。
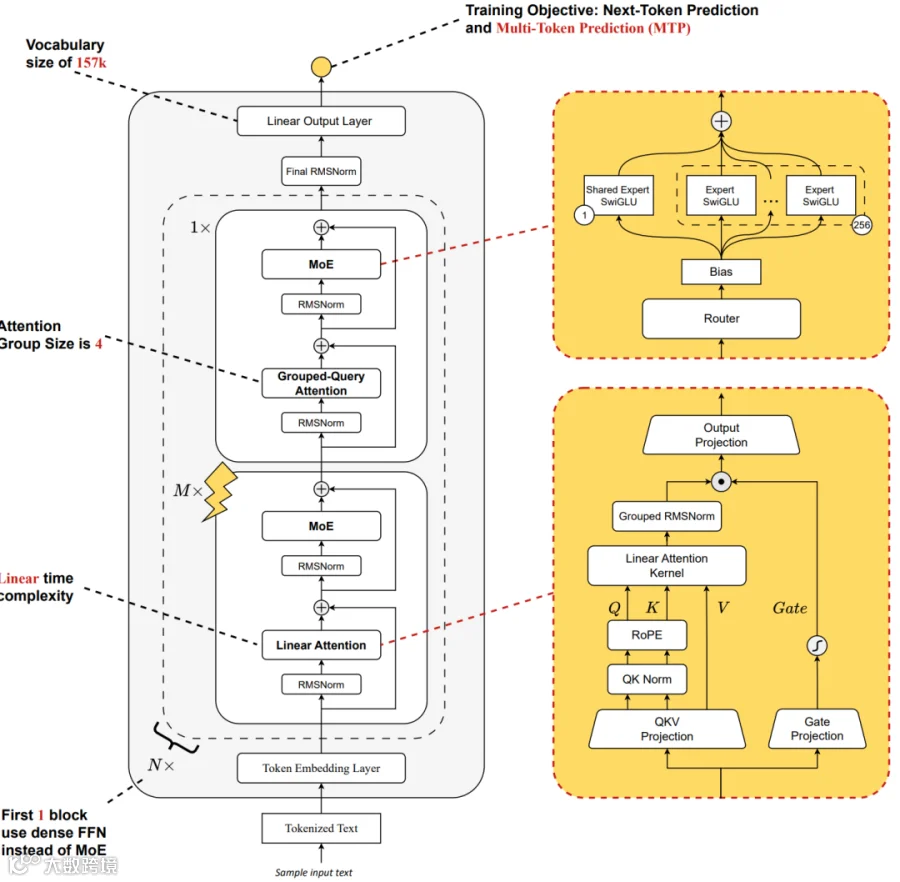
2.2 Cache 大小
基于上述分析,降低 KV-Cache 压力的思路基本可以归纳为以下几类:
MHA -> GQA:KV-Cache 规模会随 Group Size 增大而下降。MHA 可以理解为 Group Size 为 1 的特殊情况,MQA 可以理解为 Group Size = Head 数。
MLA:类似 MQA。
SWA:通过窗口限制,将有效 KV-Cache 的存储与加载规模控制在一个较小的范围内,可以忽略。
DSA:Indexer Cache 的维度更低,绝对规模更小,但依然无法忽略,并且并不会节约存储空间。
LinearAttention 系列:State 大小与序列长度基本无关,,Cache 很小,可以忽略。
Hybrid Attention 比例:Full Attention Layer 占比越低,整体 KV-Cache 压力通常也越小,比如 Ring2.5-1T 中,只有 1/8 层使用 MLA。
结合下图中常见模型的 Attention 配置和 KV-Cache 大小,可以看出相对比较有优势的架构是:
MLA + DSA:DeepSeek V3.2 和 GLM-5.1。
Hybrid Attention:GQA/MLA(层少) + SWA/Linear(层多),并且 GQA 中要使用较大的 Group Size。
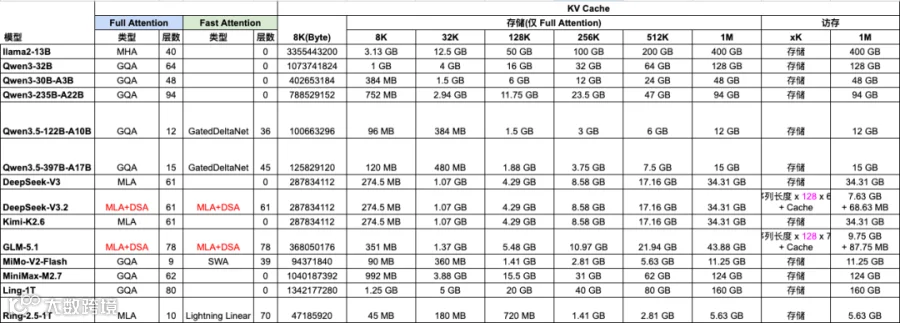
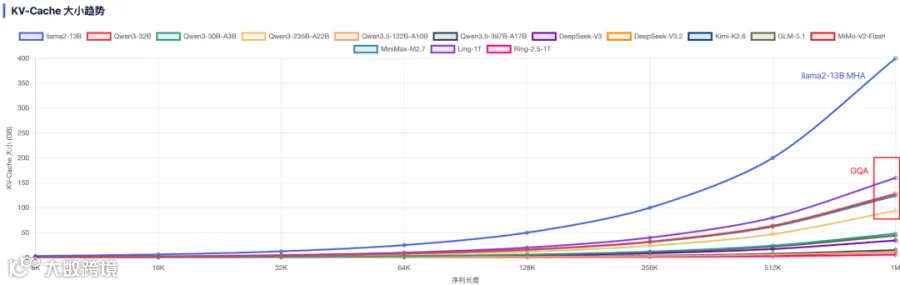
三、不同应用场景
3.1 应用场景分析
随着大模型能力的不断提升,其应用场景已经从简单的对话和 Offline Inference(Batch) 逐步演变为更复杂的 Agentic 工作流。不同场景对 TPS/User(Token 生成速度)的要求差异很大,而 TPS/User 又与并发度(Batch Size)密切相关。整体来看,TPS/User 要求越高,可承受的 Batch Size 越小,系统成本越高。
如下图所示为不同场景对 TPS/User 的需求:
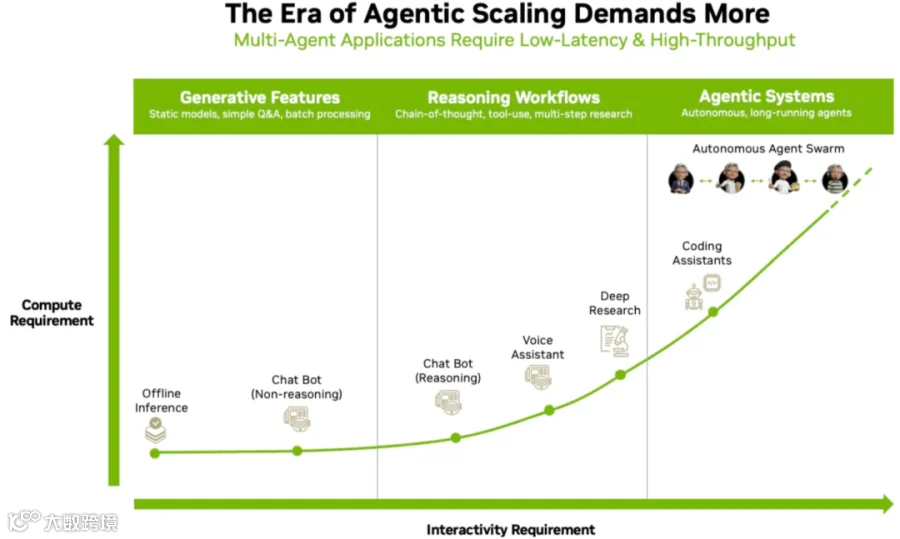
Offline Inference:无实时交互需求,可最大化 Batch Size 提升 GPU 利用率。调度策略应当以吞吐优先,可容忍高延迟换取高总吞吐。
TTFT:不重要。
TPS/User:小于 20 Token/s 也完全可以接受。
典型输出 Token 数量:和任务密切相关。
Chatbot(Non-reasoning):有一定的实时交互需求,但通常满足人眼的阅读速度即可。
TTFT:可接受(<2s);体验良好(<1s);体验非常好(<0.5s)。
TPS/User:可接受(15-20 Token/s);体验良好(20-50 Token/s);体验非常好(> 50 Token/s)。
典型输出 Token 数量:100-500 Token。
Chatbot(Reasoning):增加了 Reasoning,输出 Token 数明显增加,不过用户往往对“深度思考”有更高的容忍度。通常来说,Thinking 部分需要适当快些,以便降低 E2E 时间,有效 Output 满足人眼阅读体验即可。
TPS/User:
Thinking 部分:50-100 Token/s。
Output 部分(用户可见):20-50 Token/s。
典型输出 Token 数量:1,000 - 10,000 Token。
Voice Assistant:人听词的速度比阅读速度慢,但是端到端的链路比较长,包括 ASR -> LLM TTFT + 首句生成 -> TTS 合成 -> 播放。因为起始阶段需要快速填充 TTS Buffer,对 TTFT 和 TPS/User 要求较高,随后并不需要较高的 TPS/User。
TPS/User:
起始突发阶段:50-100 Token/s。
稳定输出阶段:15-20 Token/s。
典型输出 Token 数量:50-200。
Deep Research:多步 Agent 任务,需要多轮 LLM 调用 + 工具调用。用户通常预期会有较长的等待时间,对单次调用的 TPS 不敏感,但是也会期望总时间不要太长。
总 Token 数量:10,000 - 100,000 Token。
TPS/User:50-200 Token/s
200 Token/s 可以满足绝大部分需求,体验很好。
100 Token/s 基本也都可以满足需求,体验不会太差。
50 Token/s 极端场景下体验较差。
Coding Assistant:和用户会有频繁的交互,对时延比较敏感,通常要求较高的 TPS/User。不过 Coding Assistant 也可以分为不同的子场景分别优化,比如行内补全可以采用较小的模型获得较高的 TPS/User;对话模式会有较多的有效输出 Token 数,TPS/User 要求也不会特别高;而 Agentic Coding 场景自会有非常高的要求,通常要求分钟级的输出,不过这种场景也可以将任务拆分,进而控制整体输出长度,将单任务 Token 总数控制在 10,000 - 100,000 Token。
典型输出 Token 数量:10,000 - 100,000 Token
TPS/User:100-400 Token/s
400 Token/s 可以满足绝大部分需求,体验很好。
200 Token/s 基本也都可以满足需求,体验不会太差。
100 Token/s 极端场景下体验较差。
大型 Coding 项目:对于一些中大型项目,代码行数甚至可达 50,000 行,假设每行平均 10 个 Token,则需要 500,000 Token,也基本达到当前常见模型的上限。即便不是这么大型的项目,也可能因为需要反复编写代码 -> 编译/测试 -> 修复异常循环,从而导致总 Token 数达到 128K - 512K。当然,该场景也可以通过子任务划分、压缩等发生降低单任务 Token 总数。
典型输出 Token 数量:100,000 - 500,000 Token
TPS/User:
1000 Token/s 可以满足绝大部分需求,体验很好。
400 Token/s 基本也都可以满足需求,体验不会太差。
200 Token/s 极端场景下体验较差。
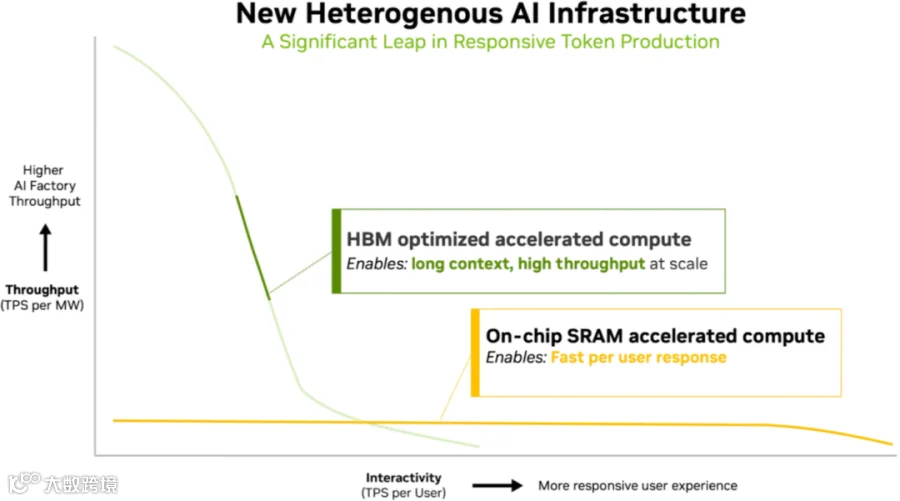
3.2 NVIDIA Rubin NVL72 + LPX 分析
如下图所示,为 Vera Rubin NVL72 和 LPX 的各种适用场景:
Rubin GPU 采用 HBM,非常适合长上下文,高吞吐的场景,随着 TPS/User 要求的提升,TPS/MW 逐渐下降。
LPX 主要使用 SRAM,带宽非常高,很适合对 TPS/User 要求极高的场景。当然,由于 SRAM 容量有限,无法充分容纳高并发下的 KV Cache 和激活,导致即使 TPS/User 要求不高,其 TPS/MW 也不会特别高。
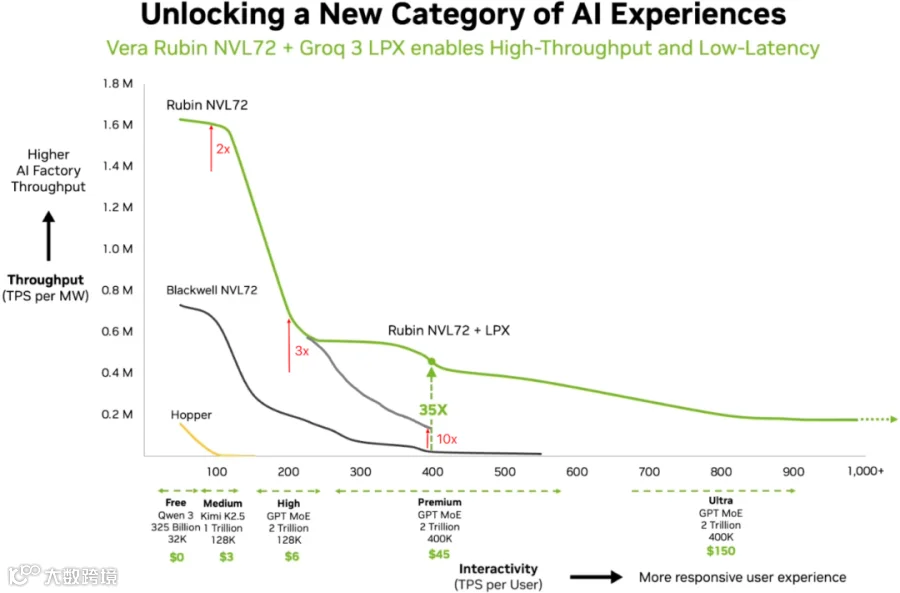
如下图所示为 NVIDIA 提供的 Vera Rubin NVL72 + Groq 3 LPX 在不同场景下的吞吐:
TPS/User <= 100:Rubin NVL72 和 Blackwell NVL72 还能达到比较高的 Batch Size,TPS/MW 基本与算力呈正比。
100 <= TPS/User <= 200:Blackwell NVL72 中 Batch Size 下降的更多,TPS/MW 下降的更快,Rubin NVL72 的优势开始凸显。
200 <= TPS/User <= 400:TPS/User 要求非常高,Rubin NVL72 的优势非常明显,甚至 TPS/MW 达到 Blackwell NVL72 的 10x。Rubin NVL72 + LPX 的优势更加明显,甚至在 400 TPS/User 处达到 Blackwell NVL72 的 35x,是单独使用 Rubin NVL72 的 3.5x。
TPS/User >= 400:Rubin NVL72 + LPX 的优势非常明显。
四、NVIDIA CMX
4.1 概述
NVIDIA 在 GTC 上也发布了其准备针对 Context Memory(KV Cache)的 NVIDIA CMX Context Memory Storage Platform [5],可以在 Rubin NVL72 Rack 的基础上额外扩展 CMX 存储 Rack。其定位可以理解为:在传统 GPU/HBM/SSD 层级之外,为 Context Memory 引入一层更明确的共享存储能力。主要解决以下问题:
跨 Rack 共享上下文。
减少重复 Prefill 和历史重算。
支撑 SuperPod 级的 KV-Aware 路由。
为长上下文与多轮场景提供更可控的共享 Warm Tier。
将共享 KV 从传统共享存储中剥离出来,避免用远端存储承载活跃 Context。

4.2 KV-Cache 存储层级
如下表所示,CMX 相当于在本地 SSD(G3)和远端共享存储(G4)之间额外增加了专门针对 KV-Cache 的共享存储:
整个 SuperPod 共享(比如 1152 GPU),空间远大于本地 SSD,小于 G4 共享存储。
相比访问远端 SSD 的链路更短,时延更低。

4.3 CMX 优劣势
Agentic 和多轮对话场景确实大幅推高了 KV-Cache 的存储需求,但是正如前文的分析,当前一些旗舰模型也在架构设计上充分考虑了 KV-Cache 的存储压力,通过 GQA/MLA、Sparse Attention、Hybrid Attention 等方式显著降低了这一压力。
对于真实的复合场景(序列分布不同、TPS 要求也不通)来说,长上下文需求本身未必一直占据很高的比重,更可能是一类长尾需求。
既然可以通过 Superpod 感知路由来避免跨 Superpod 的 CMX KV-Cache 加载,那么同样也可以考虑通过 Server/Rack 感知路由来尽量避免 SSD 中的 KV Cache 在 Server/Rack 之外额外迁移,以更充分地发挥本地 SSD 缓存 KV-Cache 的价值。
在需求尚未明确之前就额外采购 CMX,可能会造成采购预算的浪费。在一些情况下,把预算用于扩充更多 SSD 或 GPU Rack,反而可能更直接地提升系统整体能力。
CMX 也会对机房建设带来额外挑战,如果提前购买,可能会出现预算浪费;如果后续再补建,又可能带来机房改造风险,比如供电、机架容量或布线方案不再满足要求。更稳妥的方式,往往是在机房初期规划时预留对应的扩展空间和条件。
五、Moonshot Prefill-as-a-Service
5.1 概述
Moonshot 最近发布的 [2604.15039] Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter [6] 引起了不少讨论。它的价值并不在于模型结构或算法层面带来了巨大创新,而在于捕捉到了一个重要趋势:随着 Hybrid Attention 等方案让 KV-Cache 规模明显下降,异构 PD 分离在跨集群场景下开始变得真正可行。基于这个前提, 论文提出 Prefill-as-a-Service(PrfaaS)的思路:将长上下文 Prefill 选择性地卸载到独立的高算力集群,再把生成的 KV-Cache 通过普通以太网(前端网络)传回 Local PD 集群完成 Decoding。这样可以在一定条件下实现跨集群、跨机房、异构硬件解耦的 LLM Serving 架构。
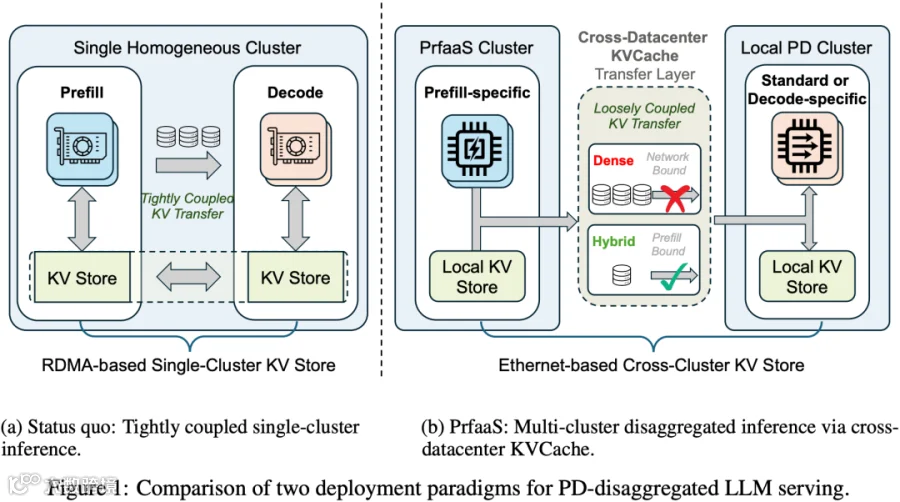
5.2 异构集群
虽然 PD 分离刚出来时,很多人都鼓吹“异构 PD 分离”,但一旦进入到集群如何建设、如何互联、如何调度等具体问问时往往又哑口无言。核心难点在于,有几个问题并没有那么容易被真正解决:
在 DC 建设时,通常不同类型的 GPU 是不同的集群,比如 A100、H100、B300、H20。
一方面,因为它们的算力不同、后端网络不同、采购时间不同,在 PD 之前并没有太多混合调度的需求。
另一方面,后端网络互联也会有挑战,A100 是 200Gb/s 网络为主,H100 是 400Gb/s 为主,而 B300 是 800Gb/s 为主。
此外,后期搬迁重建也相对比较麻烦。
不同设备的比例难以确定。
Workload 高度动态化,并且随时间和技术发展快速演进,比如短短半年时间,由于 Agent 的发展导致序列长度明显增加。
模型结构的变种也很多,资源采购、机房建设的周期往往无法适应当前模型的快速演进。
5.3 跨集群、机房
跨集群的前端网络带宽通常比后端网络低得多。以 A100、H100 平台为例,前端网络带宽常见是 100Gb/s、200Gb/s 或 400 Gb/s,往往只有后端网络的 1/8 甚至 1/16。此外,前端网络通常会采用有收敛网络,导致核心链路更容易出现瓶颈。
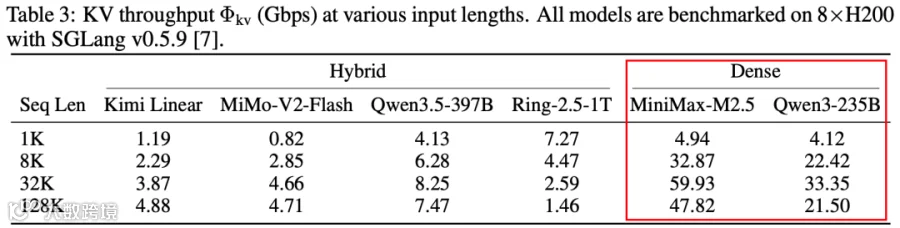
当前的 Hybrid Attention + GQA/MLA 等机制已显著降低 KV Cache 规模,也让 Prefill 和 Decoding 之间的 KV-Cache 传输量明显下降。如下图 Table 3 所示,更大规模的 Hybrid Attention 模型的 KV-Cache 反而比更小的 Dense Attention(GQA)模型小得多,甚至达到 10x 差距。这与我们前面的分析类似,也就为跨集群的 KV-Cache 传输提供了可行性。
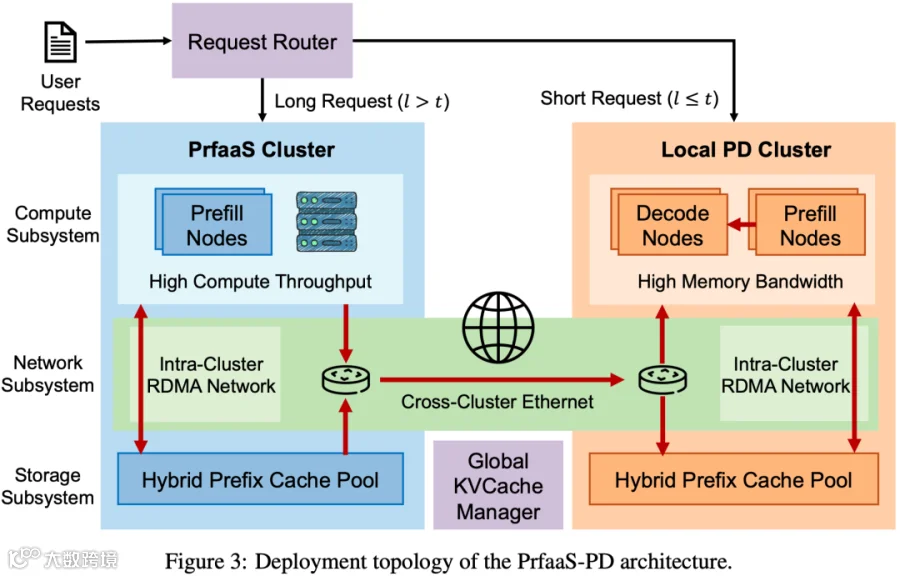
此外,也不是简单地把所有 Prefill 都放到高性能 GPU(比如 H100) 的 Prefill 节点上就可以。对于一些比较短的 Request,使用高性能 GPU 可能并不划算,再叠加跨集群传输延迟后,效果甚至可能不如直接由本地高带宽 GPU(比如 H20)节点处理。因此 Prfaas 的方案是将部分 Long Request 路由到 PrfaaS Cluster,而将 Short Request 和 Decoding 调度到 Local PD Cluster。如下图 Figure 3 所示:
5.4 局限性和挑战
PrfaaS 同样会面临一些现实挑战。如果把它放到真实生产环境中,前端网络除了承载 KV-Cache 传输外,还需要承载镜像下发、模型下发、用户 Request/Response 流量以及其他服务流量等。这些流量规模往往并不稳定,要么难以预测,要么需要做 QoS 隔离。如果处理不好,就可能污染 KV-Cache 传输路径,从而把压力传导到第二 Token 甚至后续 Token 的生成时延上。
六、其他工作
6.1 Google TurboQuant
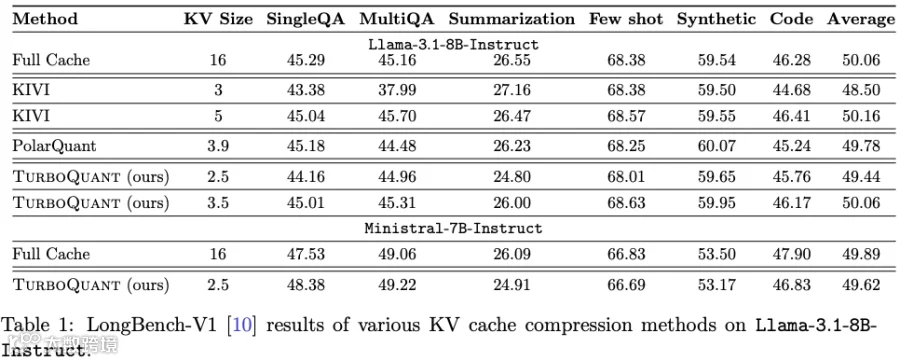
前段时间 Google 的 [2504.19874] TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate [7] 也在社区中引起广泛讨论,甚至被炒作为“可以大幅降低存储需求”,引起存储厂商大跌。
实际上,TurboQuant 确实提供了进一步降低 KV-Cache 的可能,但其可带来的降幅并没有想像中那么大。在尽量保障精度的前提下,比较理性的压缩比例为 2x(8 bit -> 4 bit),远小于模型结构优化带来的提升幅度。
6.2 MSA: Memory Sparse Attention
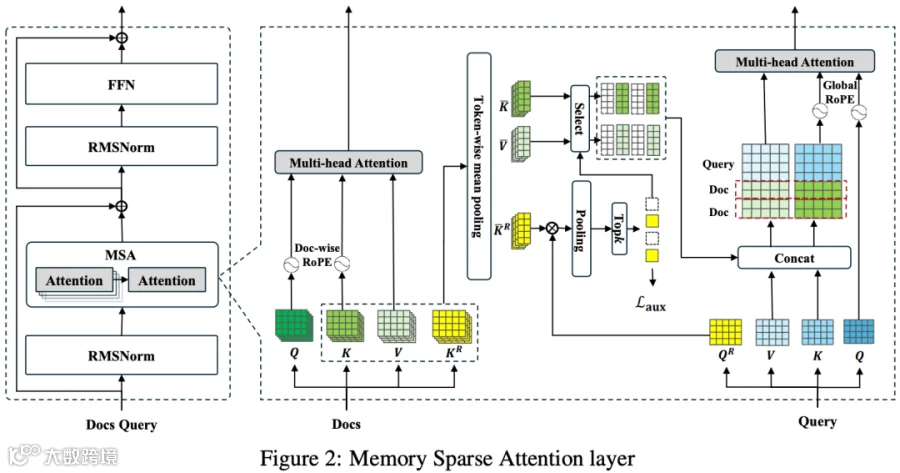
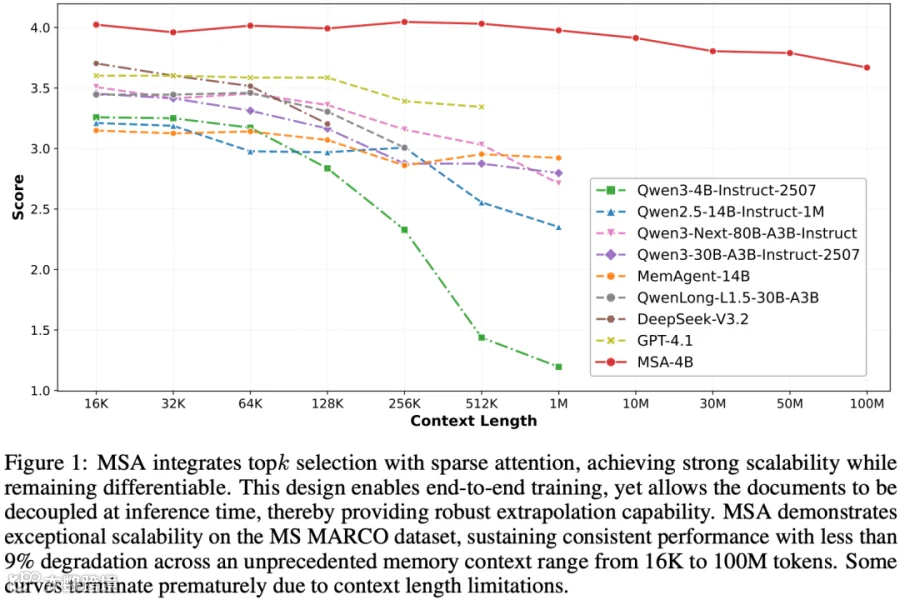
在 [2603.23516] MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens [8] 中,作者提出 Memory Sparse Attention(MSA),一种端到端可训练、兼顾效率与大规模可扩展性的 Memory 模型框架。通过可扩展稀疏注意力架构、文档级 RoPE 等核心创新,MSA 在训练和推理阶段均实现线性复杂度,同时保持精度稳定性。
论文结果表明,当 Token 从 16K 扩展至 100M 时,性能衰减幅度低于 9%;此外,结合 KV Cache 压缩与推理阶段的 Memory 并行机制后,可在 2 张 A800 GPU 上完成 100M Token 的推理任务。
然而,该方案也有相应的局限性。一方面,它需要对模型做额外训练或至少做较多架构级适配;另一方面,它的适用场景也更偏向文档问答、长文总结等 memory-centric 任务。
七、总结与判断
KV-Cache 已经不再是一个单纯的模型实现细节,而是正在成为连接 “模型架构” 与 “Inference Infra” 的关键中间变量。模型层对 KV-Cache 的重构方式,会直接决定 Inference 系统对 HBM、DRAM、SSD、前后端网络以及路由调度能力的需求结构。
模型越是能在架构上降低 KV-Cache 的存储与搬运成本,AI Infra 层的约束就越少,系统设计的自由度也越高。这也就意味着,未来的竞争重点不只是 “更大的 GPU” 或 “更高的带宽”,而是 “模型结构优化 + Serving 系统设计 + 硬件层级协同” 的联合优化。
从模型趋势看,GQA/MLA、Sparse Attention、Linear Attention 和 Hybrid Attention 都在把 KV-Cache 从“必须累积增长”变成“可被结构性控制”的对象。
从系统角度看,KV-Cache 规模下降并不只意味着存储成本下降,更意味着 Prefill/Decoding 分离、跨集群传输、异构调度等方案开始具备更强的落地可能性。
从应用角度看,不同场景的核心矛盾并不相同:有些场景要吞吐,有些场景要 TPS/User,还有一些场景要的是总任务完成时间。因此,不应该使用单一指标去说明所有 AI Infra 的价值。
从硬件选型看,HBM GPU、DRAM、本地 SSD 以及类似 CMX 的中间层,未来更可能是长期共存而不是单一方案 “通杀” 所有场景。
短期内最值得关注的,依然是 “模型端先把 KV-Cache 做小”。这会比 “在 Infra 层直接为大 KV-Cache 堆资源” 更具有普遍性,也更容易在多种场景下复用。
从中长期看,真正的差异化优势可能来自 “KV-aware 的系统设计能力”:谁能在模型、调度、网络、存储和机房层面同时做联合优化,谁就更容易在下一轮 AI Infra 竞争中占据优势。
AI Infra 演进中的不确定性是最大的确定性,不说前提条件的结论大概率是忽悠。
八、参考链接
https://arxiv.org/abs/2309.17453
https://arxiv.org/abs/2512.02556
https://arxiv.org/abs/2412.06464
https://arxiv.org/abs/2510.19338
https://www.nvidia.com/en-us/data-center/ai-storage/cmx/
https://arxiv.org/abs/2604.15039
https://arxiv.org/abs/2504.19874
https://arxiv.org/abs/2603.23516