
将非结构化文件(如文档、图像、视频、科学数据等)转化为AI就绪资产(AI-ready assets),是企业实现AI转型、解决“数据丰富但洞察贫乏”问题的关键步骤。这里对一些相关方案的整体设计思路、关键实施步骤及实际客户应用场景做一个简要分析。
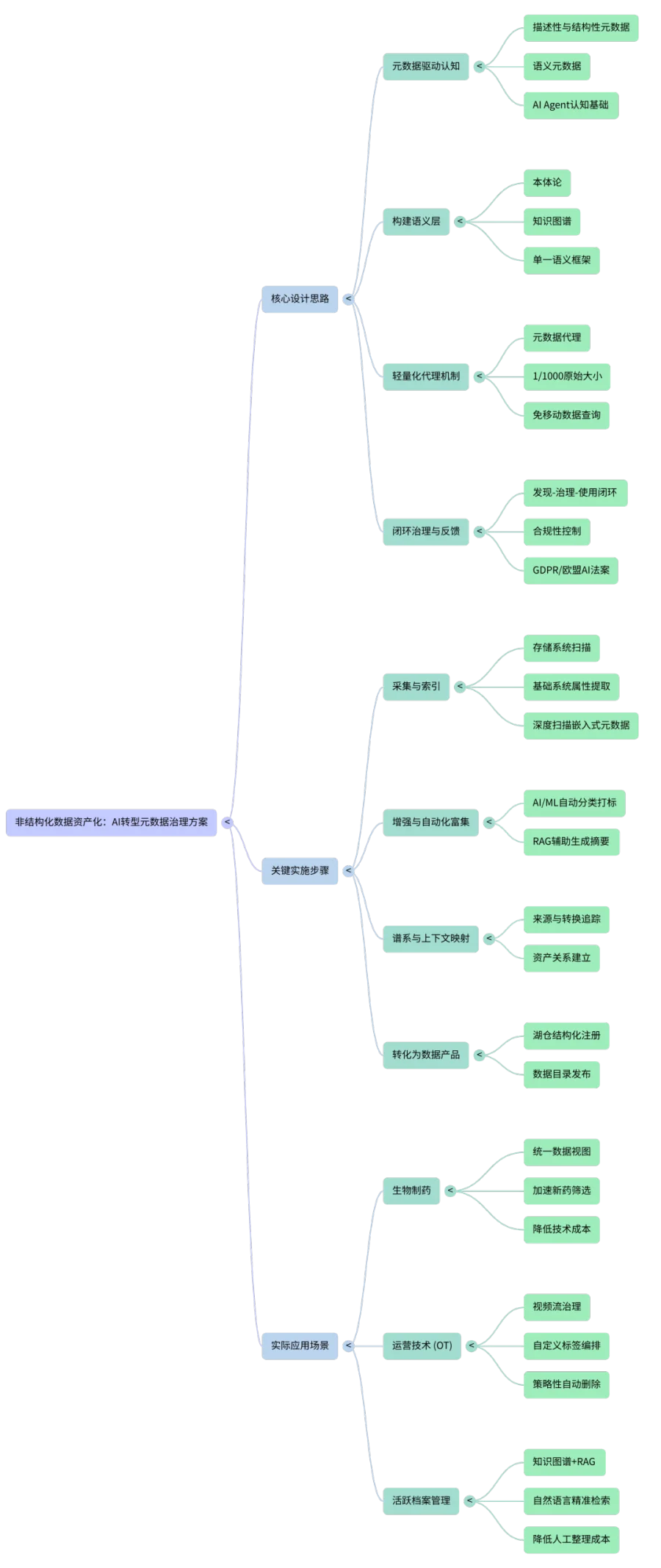
一、 整体设计思路:构建元数据驱动的认知基础
将非结构化文件转化为AI就绪资产的核心逻辑在于“元数据管理”。非结构化数据占企业数据的80%,但仅有1/3被有效利用,原因在于这些文件的内容对AI系统而言往往是不透明的。
1. 元数据作为认知基础:元数据不再仅仅是对数据的补充描述,而是AI Agent功能(推理、规划、记忆)的认知基础。通过整合描述性、结构性、管理性和语义元数据,AI可以理解数据的业务意义和背景关系。
2. 构建语义层(Semantic Layer):利用本体(Ontologies)和知识图谱(Knowledge Graphs)将各种元数据统一在语义框架内,为全组织数据创建一个单一的语义层。这使AI能区分“财务资产”与“物理资产”等概念差异。
3. “轻量化代理”机制:建立仅为原始文件大小约1/1000的元数据代理(Metadata Proxies)。这允许数据科学家在不移动海量原始文件的情况下,直接对数PB的非结构化数据进行查询和训练准备。
4. 闭环治理与反馈:建立“发现-治理-使用”的闭环,通过数据编排和合规性控制,确保数据在满足相关法规监管要求的前提下被安全使用。
二、 关键实施步骤
实施方案通常遵循从底层扫描到顶层知识化的过程:
1. 元数据采集与索引(Harvesting & Indexing):
◦ 通过连接器扫描SMB、NFS、S3等存储系统,提取文件的基础系统属性(如大小、创建日期、权限)。
◦ 深度扫描:打开文件以提取嵌入式元数据,例如医学影像的病患标识、CAD图纸的修订历史、科学数据的基因组注释等。
2. 元数据增强与自动化富集(Enrichment & Augmentation):
◦ 利用AI/ML技术自动对文件进行分类、打标签和情感分析。
◦ RAG辅助管理:利用检索增强生成(RAG)技术,在人工审查下为新注入的文档自动生成摘要、元数据标签和知识库条目。
3. 数据谱系与上下文映射(Lineage & Context Mapping):
◦ 追踪数据的来源、所有权和转换过程。
◦ 建立数据资产之间的关系,确保AI模型在推理时具备足够的上下文。
4. 转化为结构化“数据产品”(Data Products):
◦ 在数据湖仓(Data Lakehouse)中,将提取的非结构化元数据注册为结构化的表格数据集。
◦ 通过数据目录(Data Catalog)发布这些数据集,供数据科学家进行模型训练和分析。
三、 实际客户应用场景解析
1. 生物制药:加速药物研发
• 挑战:某跨国制药公司拥有150多个分散的数据模型,缺乏对数据来源和消费的可见性,导致合规挑战。
• 方案:通过集成元数据管理平台,构建统一准确的数据视图,支持将受监管的高质量数据交付给AI应用。
• 成效:实现了负责任的大规模AI部署,加速了新药筛选和产品组合优化,降低了技术成本。
2. 运营技术(OT):摄像头数据治理
• 应用场景:制造业、警务和公用事业中的摄像头视频流。
• 方案实施:
◦ 自动提取图像文件元数据并加载到元数据管理平台。
◦ 利用自定义标签(如摄像头型号、拍摄位置)进行数据编排。
◦ 合规性控制:设定基于策略的自动删除机制(如非法律保留数据在1年后删除),确保符合存储与法律要求。
3. 活跃档案管理:知识图谱驱动的探索
• 应用场景:不断增长的数字档案馆或图书馆收藏。
• 方案:将知识图谱与RAG结合。用户使用自然语言查询时,系统通过知识图谱扩展关键词,帮助非专业用户精准定位复杂档案中的信息。
• 成效:通过AI生成的摘要和标签降低了人工整理成本,同时提高了检索的精确度和事实一致性。
综上所述,将非结构化文件转化为AI就绪资产的过程,本质上是将不透明的“二进制黑盒”通过元数据手段转化为可解释、可治理且富含业务语义的“数字知识资产”。