背景
由于launch的先后顺序和GPU资源的占用情况,使得GPU中不同stream间并行成为机会主义,即使有高优先级的任务需要执行,依然需要等到释放足够的GPU资源才能响应高优先级任务,响应延迟很难稳定控制。为了解决这一问题,cuda13.1开始提出了green context(GC), 它在创建时就会关联到一组特定的 GPU 资源, 这样一来,提交到某个 green context 的 GPU 工作,就只能使用分配给它的那些 SM 和工作队列。这样做有助于减少,或者更好地控制,由共享资源使用带来的相互干扰。
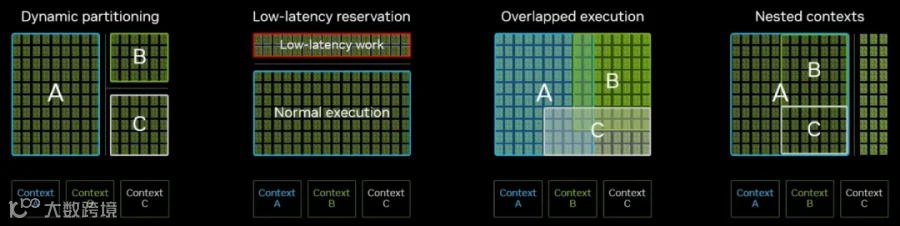
使用场景
-
Dynamic partitioning,根据流量变化动态分配SM;
-
Low-latency reservation,给关键低时延任务预留一块专用资源;
-
Overlapped execution,不同任务既有各自保底资源,又共享一部分资源,共享的资源会串行利用;
-
Nested contexts,先做大粒度划分,再在内部继续细分
使用Green Contexts
Device Resource and Resource Descriptor
struct cudaDevResource { enum cudaDevResourceType type; union { struct cudaDevSmResource sm; struct cudaDevWorkqueueConfigResource wqConfig; struct cudaDevWorkqueueResource wq; }; };
cudaDevResource是统一的资源管理句柄,由于union的存在,一个cudaDevResource句柄只能代表一类资源,这些资源只有三类,分别是SM、workqueue 配置资源和预先存在的 workqueue 资源。
Step 1: Get available GPU resources
创建 green context 的第一步,是获取可用的设备资源,并填充到 cudaDevResource 结构体中。当前有三种可能的起点,相关的 CUDA runtime API 函数签名如下:
cudaError_t cudaDeviceGetDevResource(int device, cudaDevResource* resource, cudaDevResourceType type)
cudaError_t cudaExecutionCtxGetDevResource(cudaExecutionContext_t ctx, cudaDevResource* resource, cudaDevResourceType type)
cudaError_t cudaStreamGetDevResource(cudaStream_t hStream, cudaDevResource* resource, cudaDevResourceType type)
通常情况下,起点会是一张 GPU device。下面这段代码展示了如何获取某个 GPU 设备上可用的 SM 资源。在cudaDeviceGetDevResource调用成功后,用户就可以查看该资源中可用的 SM 数量。
int current_device = 0; CUDA_CHECK(cudaSetDevice(current_device));cudaDevResource initial_SM_resources = {};CUDA_CHECK(cudaDeviceGetDevResource(current_device , &initial_SM_resources , cudaDevResourceTypeSm ));std::cout << "Initial SM resources: " << initial_SM_resources.sm.smCount << " SMs" << std::endl; std::cout << "Min. SM partition size: " << initial_SM_resources.sm.minSmPartitionSize << " SMs" << std::endl;std::cout << "SM co-scheduled alignment: " << initial_SM_resources.sm.smCoscheduledAlignment << " SMs" << std::endl;int current_device = 0; CUDA_CHECK(cudaSetDevice(current_device));cudaDevResource initial_WQ_config_resources = {};CUDA_CHECK(cudaDeviceGetDevResource(current_device , &initial_WQ_config_resources , cudaDevResourceTypeWorkqueueConfig ));std::cout << "Initial WQ config. resources: " << std::endl;std::cout << " - WQ concurrency limit: " << initial_WQ_config_resources.wqConfig.wqConcurrencyLimit << std::endl;std::cout << " - WQ sharing scope: " << initial_WQ_config_resources.wqConfig.sharingScope << std::endl;
Step 2: Partition SM resources
获得cudaDevResource后,进行切分,可以通过如下两个API完成。
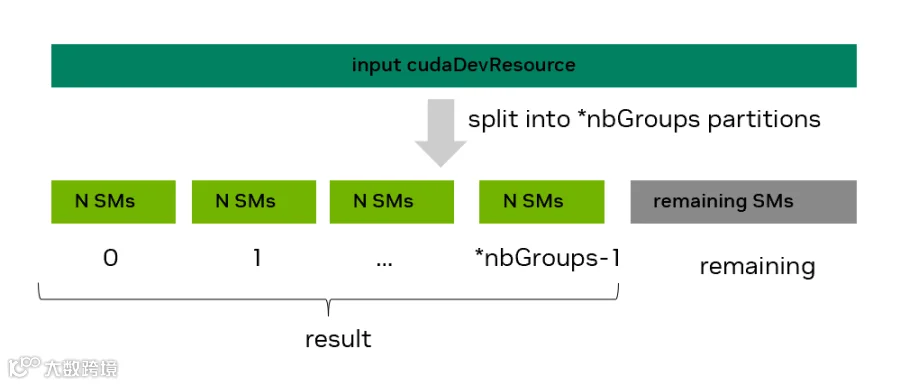
cudaError_t cudaDevSmResourceSplitByCount(cudaDevResource* result, unsigned int* nbGroups, const cudaDevResource* input, cudaDevResource* remaining, unsigned int useFlags, unsigned int minCount)
创建多个同构分区+一个剩余分区,用户请求把输入的 SM 类型 device resource 划分成 *nbGroups 个同构分组,并且每组至少包含 minCount 个 SM。但最终结果中,实际得到的是一个可能被更新过的*nbGroups 数量的同构分组,每组有 N 个 SM。效果如下图。
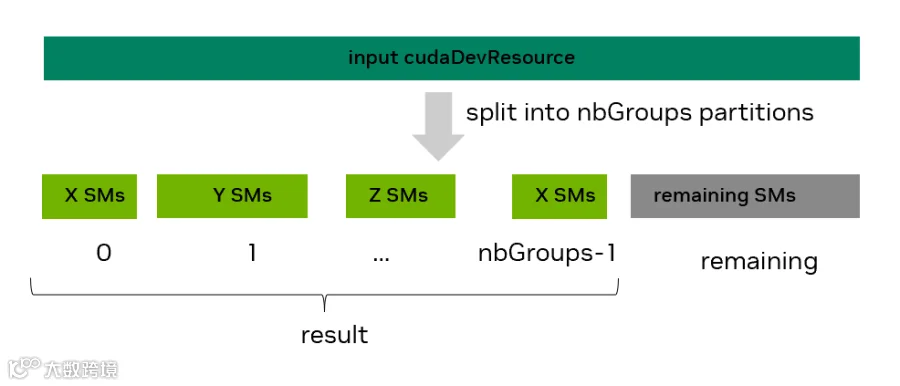
cudaError_t cudaDevSmResourceSplit(cudaDevResource* result, unsigned int nbGroups, const cudaDevResource* input, cudaDevResource* remainder, unsigned int flags, cudaDevSmResourceGroupParams* groupParams)
创建多个异构分区。这个 API 会尝试把输入的 SM 类型资源划分成 nbGroups 个有效的 device resource(分组),并把结果放到 result 数组中;每个分组的要求由 groupParams 数组中的对应项指定。还可以选择性地生成一个剩余分区。如果 split 成功,那么如下图所示。
int nbGroups = 2; unsigned int default_split_flags = 0;cudaDevResource remainder {}; cudaDevResource result_use_case[2] = {{}, {}}; cudaDevSmResourceGroupParams group_params_use_case[2] = { {.smCount = X, .coscheduledSmCount=0, .preferredCoscheduledSmCount = 0, .flags = 0}, {.smCount = Y, .coscheduledSmCount=0, .preferredCoscheduledSmCount = 0, .flags = 0}};CUDA_CHECK(cudaDevSmResourceSplit(&result_use_case[0], nbGroups, &initial_GPU_SM_resources, &remainder, default_split_flags, &group_params_use_case[0]));
Step 3(optional): Add workqueue resources
还可以继续为每个green context追加workqueue资源,这里需要手动设置config参数。
cudaDevResource split_result[2] = {{}, {}};split_result[1].type = cudaDevResourceTypeWorkqueueConfig;split_result[1].wqConfig.device = 0; split_result[1].wqConfig.sharingScope = cudaDevWorkqueueConfigScopeGreenCtxBalanced;split_result[1].wqConfig.wqConcurrencyLimit = 4;
Step 4. Create a Resource Descriptor
切分完资源后,就是为指定的资源生成资源描述符,API如下。
cudaError_t cudaDevResourceGenerateDesc(cudaDevResourceDesc_t *phDesc, cudaDevResource *resources, unsigned int nbResources)
Step 5. Create a Green Context
在创建完资源描述符后,使用cudaGreenCtxCreate来创建context对象,API如下。
cudaError_t cudaGreenCtxCreate(cudaExecutionContext_t *phCtx, cudaDevResourceDesc_t desc, int device, unsigned int flags)
Step 6. Launching work
要想让一个 kernel 运行在前面创建好的 green context 上,首先需要使用cudaExecutionCtxStreamCreateAPI 为该 green context 创建一个 stream。如果在这个 stream 上通过<<< ... >>> 或 cudaLaunchKernel API启动 kernel,就可以确保这个 kernel 只能使用该 stream 所属 execution context 可用的资源(例如 SM、work queue)。
cudaStream_t green_ctx_stream;int priority = 0;CUDA_CHECK(cudaExecutionCtxStreamCreate(&green_ctx_stream, green_ctx, cudaStreamDefault, priority));my_kernel<<<grid_dim, block_dim, 0, green_ctx_stream>>>();CUDA_CHECK(cudaGetLastError());
总结
Green Context 的核心价值,不是简单地“限制 kernel 能用多少个 SM”,而是给 CUDA 提供了一种更可控的资源管理方式。它把原本机会式的并行,进一步变成了可规划的并行。通过把 SM 和 workqueue 资源按 context 进行划分,应用可以在低时延、吞吐和隔离性之间做更灵活的权衡。对需要保障关键任务响应时间、减少多 stream 相互干扰、或验证不同资源配比效果的场景来说,Green Context 提供了一种几乎不需要修改 kernel、只需少量 host 侧改造就能落地的新手段。