
在法律AI应用领域,Harvey无疑是最耀眼的明星公司之一
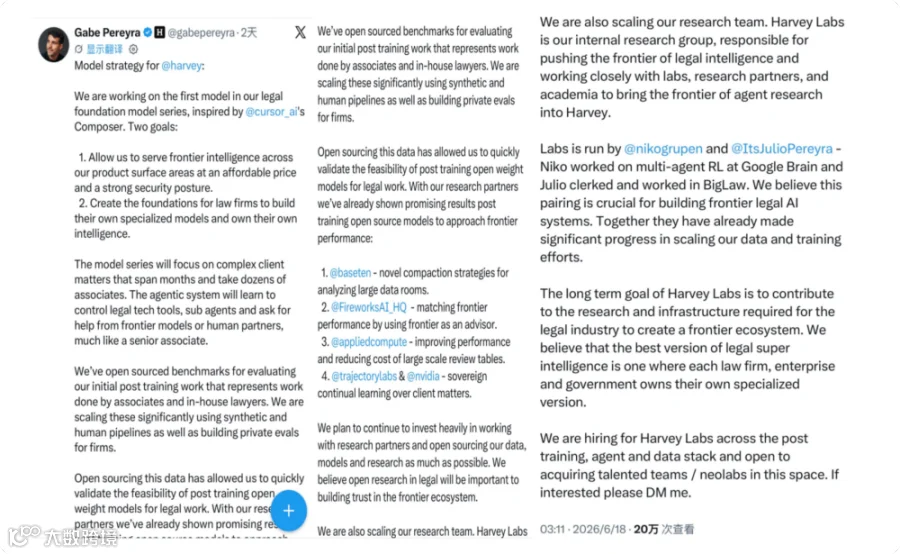
Gabriel为这个项目设定了两个目标。
第一个目标,是以更可承受的成本、更强的安全性,把接近前沿水平的智能部署到Harvey的各个产品之中。
第二个目标,则更值得关注:为律所建立基础,使其能够训练自己的专业模型,进而“拥有自己的智能”。
这句话可能比“Harvey开始训练模型”本身更加重要。
因为它意味着,Harvey正在重新定义法律AI公司与律所之间的关系。未来的律所购买的,可能不再只是一个外部AI工具,而是一套能够承载自身知识、流程、经验和客户关系的专业智能系统。
Harvey也因此开始从一家法律AI应用公司,转向一家法律智能基础设施公司。
Harvey训练自己的模型,并不意味着它准备放弃GPT、Claude或者其他前沿模型。在可以预见的未来,最强的通用模型仍然会在复杂推理、开放性研究和疑难问题处理中发挥不可替代的作用。
但并不是每一项法律任务,都需要调用最昂贵、最强大的模型。
法律工作中存在大量高频、重复和相对确定的环节,例如文件分类、条款提取、事实整理、信息核验、格式转换、初步检索和标准文本生成。如果这些任务全部调用前沿模型,随着用户数量和Agent运行次数增加,模型成本会迅速成为Harvey商业模式的约束。
因此,Harvey更可能建立一套分层模型体系:
•普通任务交给成本更低的模型
•专业法律任务交给自有法律模型
•最复杂的推理和判断再升级到GPT、Claude等前沿模型
Harvey真正需要掌握的,不一定是世界上参数最多的模型,而是判断什么任务应当交给什么模型。
自建模型不是对多模型战略的否定,而是多模型战略走向成熟的标志。
Gabriel在发言中提出,Harvey的模型将重点处理持续数月、需要数十名律师共同完成的复杂客户事项。这与过去的法律AI产品有本质区别。
过去,人们衡量法律AI的能力,通常会问:
它能不能回答一个法律问题?
能不能写一份合同?
能不能总结一批文件?
但一个真实的重大交易、诉讼或者监管项目,并不是由一个问题和一份文书组成的。
它可能持续几个月,涉及数千份文件、数百个任务节点和多轮客户沟通。律师需要不断发现新事实、修正判断、分配任务、核验依据,并把不同阶段的工作成果组合成最终交付物。
因此,真正困难的并不是生成某一段文字,而是维持一个长周期任务的连续性。
模型必须知道当前项目进行到了哪里,哪些事实已经确认,哪些问题尚未解决,哪些工作可以自动执行,哪些判断需要提交给高级律师。
这也是为什么Gabriel把未来的Agent形容为类似一名高级律师。它不仅要完成任务,还要学会调用法律科技工具、调度子Agent,并判断什么时候应当向更强的模型或者人类合伙人求助。
Harvey训练的不是一个更会说法律语言的聊天机器人,而是一个能够参与法律生产过程的执行系统。
GPT和Claude可以学习公开的法律法规、判例、合同和学术资料,但一家律所真正的专业能力,并不完全存在于这些公开文本中。律所的能力还存在于一系列隐性的工作方法中:
• 如何拆解一个复杂事项
• 如何识别真正重要的风险
• 如何组织尽职调查
• 如何分配不同层级律师的任务
• 如何按照客户偏好表达结论
• 在什么情况下必须升级到合伙人判断
这些能力通常没有被完整写进一本书或者一个数据库,而是分散在邮件、批注、模板、项目复盘、客户反馈和资深律师的日常决策中。通用模型可以知道“法律是什么”,但它未必知道“这家律所如何做法律工作”。
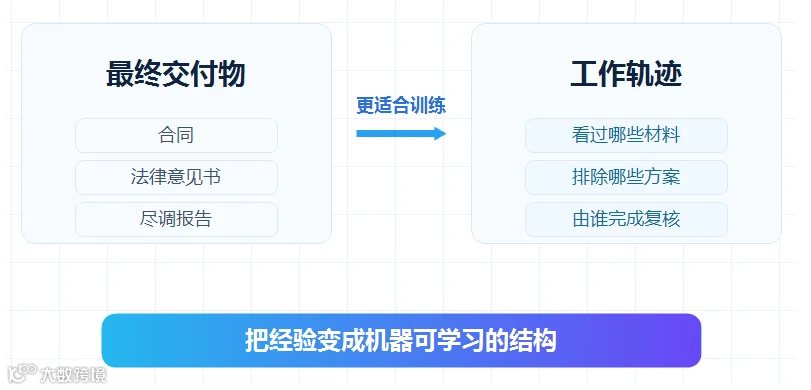
Harvey自建模型的深层目的,是将这些工作方法转化为机器可以学习和执行的结构。未来,模型学习的将不只是最终合同或者法律意见书,还包括形成这些交付物的过程:律师先查看了哪些材料,提出了哪些问题,排除了哪些方案,为什么修改某个条款,以及最终由谁完成了复核。
这些过程数据,可以被称为“法律工作轨迹”。它比最终文书更加稀缺,也更加接近一家律所真实的专业能力。
Gabriel此次发言中最有战略意义的一句话,是让律所“拥有自己的智能”。
过去,律所最重要的资产是律师、客户关系、品牌和历史经验。但这些资产高度依附于个人。
一名合伙人离开,可能同时带走客户、经验和团队;一名资深律师退休,其积累多年的判断方法也很难被完整继承。AI提供了一种新的可能:将律所的专业能力从个人经验转化为组织资产。
如果一家律所能够把历史项目、工作流程、客户规则、审查标准和专家反馈持续沉淀到模型中,那么模型就可能成为律所知识资产的新载体。未来的律所竞争,不仅是人才数量和营业收入的竞争,也可能是专业智能资产积累速度的竞争。
同样拥有1000名律师的两家律所,一家只是让律师使用公共模型,另一家则持续把律师的工作过程转化为自有数据、评测体系和专属模型。
几年之后,两者积累的组织能力可能完全不同。前者是在消费智能,后者是在积累智能。
不过,“律所拥有自己的智能”也不能被简单理解为:每家律所都拥有大量不可复制的独门法律知识。事实上,大多数法律法规、合同结构和法律意见并非绝对秘密。交易文件会在不同市场主体之间流动,优秀做法也会被竞争对手不断学习。
律所真正难以复制的部分,往往不是某一份最终文书,而是长期形成的协作方式。例如,一家律所如何理解某个重要客户的风险偏好,如何与客户法务部门分工,哪些问题需要提前汇报,哪些条款客户绝不接受,以及不同类型事项应当由谁参与。
因此,真正适合被编码的,可能不是抽象的“律所能力”,而是更加具体的“律所—客户—事项”关系。
这种关系包含专业知识,也包含沟通习惯、组织流程和责任边界。Harvey未来最有价值的模型,可能不是一个适用于所有律所的统一法律模型,而是针对特定机构、业务领域乃至重要客户形成的专业智能版本。
Harvey过去的成功,很大程度上建立在调用前沿模型的基础上。但这也带来一个长期问题:如果OpenAI、Anthropic或者Google不断增强法律能力,并直接向律所提供产品,Harvey还有多少不可替代的价值?
如果Harvey只是“通用大模型加法律界面”,那么它的许多产品能力迟早可能被底层模型公司覆盖。

要摆脱这种风险,Harvey必须掌握更多法律智能的核心环节:
1. 它需要定义法律任务
2. 建立法律评测标准
3. 生产训练数据
4. 训练专业模型
5. 调度不同Agent
6. 并把模型输出转化为可以审计、复核和承担责任的法律交付物
这也是为什么Harvey近期连续开放法律Agent评测基准、研究开放权重模型的后训练效果,并建设自己的Agent基础设施。模型、数据、评测、工作流和基础设施正在被连接成一个完整体系。
当Harvey掌握这个体系,它提供的就不再只是一个调用GPT的法律软件,而是一套帮助律所生产、积累和管理专业智能的基础设施。
Harvey此次宣布训练模型,也揭示了法律AI未来可能形成的基本架构。
在这套体系中,真正重要的并不是某一个模型独立完成所有工作,而是不同模型、工具、数据和人类专家之间的协同。
未来最强的法律AI公司,未必拥有全世界最强的通用模型,但它必须知道如何把不同层次的智能组织起来,形成稳定、可信、可规模化的法律生产能力。
Harvey开始训练自己的法律模型,表面上看是一项技术选择,实际上是一次商业模式和产业定位的升级。在法律AI发展的早期,应用公司最合理的策略,是调用最强的外部模型,快速形成产品和市场。
但当AI开始进入真实项目、复杂流程和大规模组织之后,仅仅调用模型已经不够。企业必须进一步控制成本、安全、数据、工作流程和专业能力的沉淀方式。
Harvey正在从“使用谁的模型”,走向“谁拥有由模型形成的专业智能”。
这可能是法律AI下一阶段最重要的竞争分水岭:一些公司继续销售AI工具,另一些公司则开始帮助律所把知识、经验和工作流程转化为长期积累的智能资产。当法律AI从回答问题走向完成事项,模型便不再只是外部采购的技术原料。它开始成为律所的生产资料、组织记忆和核心资产。
Harvey真正想做的,不只是让每一家律所使用人工智能。而是让每一家律所,拥有自己的智能。


