
🚀 欢迎来到AI产品经理研习之旅 🚀
好久不见。
也许你和我一样,用 GenAI 产品/工具有一段时间了。PRD 写得更快,竞品分析不再从零开始,连会议纪要都不用自己整理了。产出似乎明显提速。
但你有没有一种感觉:你只是获得了一种说不清道不明的、虚无的满足感,但你没有在变强。
一组数据很扎心。ActivTrak 2026 年的调查显示,使用 AI 工具的职场人群中,97% 承认自己在"假装高效",产出更多了,但在做的事并没有变得更重要。
80% 的员工现在都在使用人工智能,但平均每个组织运行七个平台,而只有 3% 的用户达到了最佳生产力状态,真正的工作是学习如何管理它,而不仅仅是批准它。
2026 State of the Workplace

Aakash Gupta(前 Salesforce 高级产品总监)自称花了 $28,000 测试了 47 个 AI PM 工具,结论是只有 9 个值得留下。不是工具不好,是大多数工具只是帮你把"做过的同类事情"做得更快。
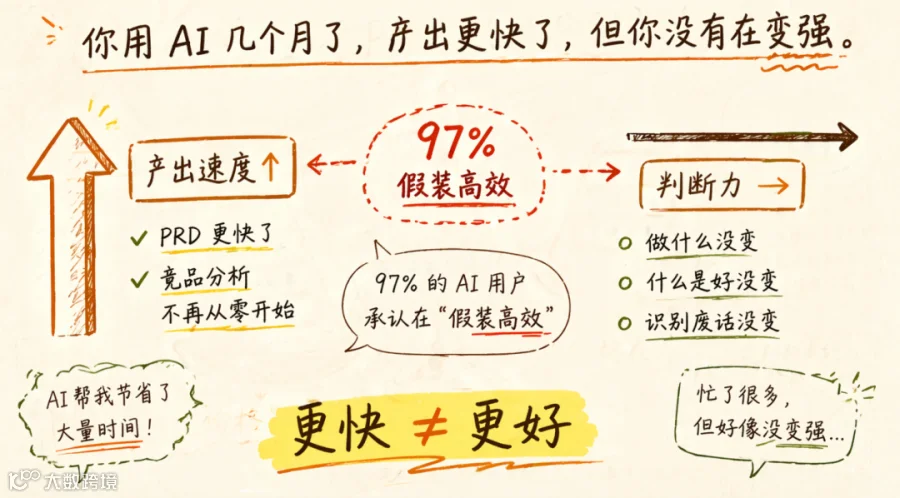
更快,但不是更好。这就是问题。
—
为什么用 AI 反而没有在变强
先说一个基本判断:AI 不是在替代 PM 岗位,是在对 PM 岗位内的每一项能力分别定价。

这个洞察来自纯银和 Stove 的分析。我深有同感,即不要把"PM 会不会被 AI 替代"当成一个整体问题来讨论,因为 AI 对 PM 工作中不同能力的影响是截然相反的:
执行类能力的价格在暴跌。 写 PRD、做竞品分析、整理用户反馈、排优先级矩阵、画流程图、画原型,这些工作的 AI 已经能做到 60-70 分(甚至更高)。不是完美,但足够作为起点。
Frank Lee(Amplitude 产品负责人):团队用 AI 辅助需求文档初稿生成后,产出时间缩短 60%,质量没降。
判断类能力的价格在升。 决定做什么和不做什么、定义什么是"好"、在模糊信息中做取舍、识别 AI 输出中哪些是正确的废话。执行类能力被 AI 补齐后,判断力的差距被放大了。
Gary Cottrell(Google AI PM):"AI isn't replacing PMs. It's exposing who actually understands users."
但大多数 PM 用 AI 的方式有问题。Reddit r/ProductManagement 上有一条高赞帖子的标题就是真实写照:"AI improves efficiency by only about 20-25% in real workflows"。评论区里大量 PM 分享了类似的体验:用 AI 生成了一份完整的需求文档,但回头发现里面有三个假设是错的,改错花的时间跟自己从头写差不多。
BCG 做过一个实验:只用 3 个精心选择的 AI 工具的人,比同时使用 4 个以上工具的人产出质量更高。原因很简单,工具越多,你在"管理工具"上花的时间越多,在"做决策"上花的时间越少。
所以核心转变不是"要不要用 AI",也不是"用哪个 AI 工具更好"。真正的问题是:你用 AI 释放出来的时间和精力,拿来做什么了?
如果你的答案是"做更多同类工作",那你只是在更快地贬值自己的执行类能力。
—
AI 时代 PM 仍然值钱的4种能力
不讲"战略思维"或"商业直觉"这种虚的东西。AI 对 PM 能力的"分别定价"不是均匀的——有些能力被替代,有些被放大,有些 AI 暂时还替代不了。下面是四种覆盖不同维度的能力,每一个都有具体的练习方法。
能力一:把"感觉不对"变成可检查的标准
你一定有过这种体验:AI 给你生成了一版方案/原型,功能完整、逻辑自洽、格式专业,但你看完就是觉得哪里不对。说不出来,但感觉不对。
这个"感觉"就是隐性知识。它不是你从哪本书上学来的,而是你做了几十次需求评审、见过几十次上线后的真实数据后,慢慢内化出来的判断标准。它在你脑子里,你从来没有把它写下来过。
问题来了:没有显性化之前,你没法跟 AI 有效协作。 你只能告诉 AI"再改改"或者"感觉还差点意思",但没法告诉它具体差在哪。
我自己用过一个方法,三层追问:
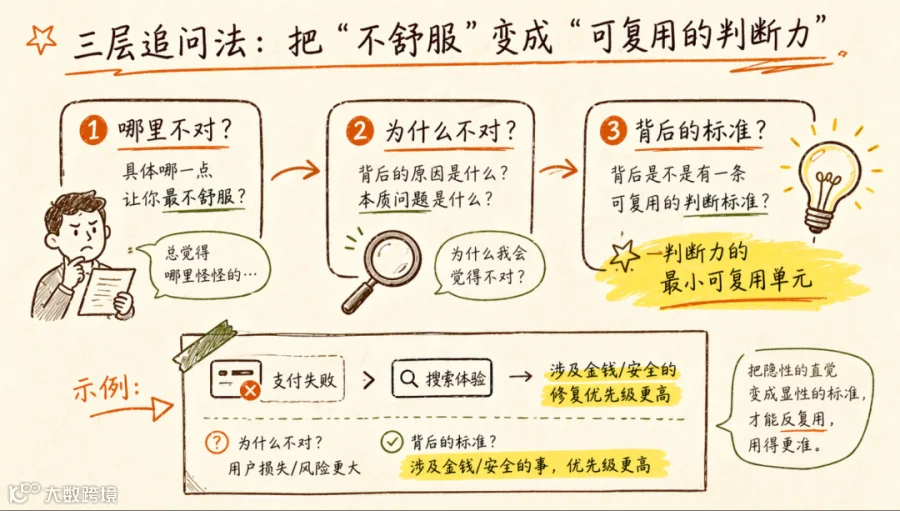
拿到 AI 的输出后,不急着采纳或否定。先问自己:具体哪一点让你最不舒服? 然后追问:为什么这一步让我不舒服?最后追问:这个不舒服的背后是不是一条可以复用的判断标准?
举个例子
AI 帮你排了一版需求优先级,功能都列上了,理由也给出来了。但你看着排序总觉得不对劲。扪心自问(多问几层为什么):
"哪个需求的排位最让我不安?"
"这个'优化搜索体验'排在'修复支付失败'前面。"
"为什么这让我不安?"
"因为支付失败意味着用户直接损失钱,搜索体验只是用起来不爽。"
→ 提炼标准:涉及用户金钱或数据安全的修复,优先级永远高于体验优化。
这条标准下次评审可以直接用,不需要再靠"感觉"。这就是判断力的最小可复用单元。
你每做一次这样的提炼,就在把隐性知识变成显性标准。积累得越多,你跟 AI 协作的效率就越高,因为你能越来越精确地告诉 AI 你要什么、不要什么。
能力二:问题框定,AI 回答问题,你定义问题
你有没有发现,用 AI 之后提问题的速度变快了,但提"好问题"的能力没有提升?

一组数据:PM 花在 Delivery 协调上的时间是 35%,会议 28%,沟通文档 15%——留给 Discovery(用户研究、市场分析、需求探索)的时间只有 12%。行业推荐比例是 30-40%。AI 让这个失衡更严重了:30 秒就能得到完整答案,所以你更倾向于"赶紧问赶紧做"。但很少有人停下来想:你问的那个问题,是对的问题吗?
AI 最强的能力是"给答案",最弱的能力是"质疑问题本身"。当你让 AI 做"搜索功能的优化方案",它会给你一个很好的方案。但它不会告诉你:也许问题不是搜索不够好,而是用户根本找不到入口。
问题框定力就是:在动手之前,先确认你在解决的是真正的问题,而不是你最先看到的那个问题。
怎么练?每次拿到需求或任务,不急着开始,先问三个问题:
1如果这个问题被完美解决了,哪个关键指标会变好? 答不上来,说明你还没定义清楚问题。
2这个问题是从哪里来的? 是用户反馈、数据分析、老板要求、还是你的直觉?来源不同,可靠性不同。
3有没有一个更上游的问题,解决了之后这个问题就不存在了? 如果有,你应该去解决上游问题。
这三问不是拖延,是区分"真问题"和"表象问题"。AI 不会帮你做这个区分——它天生倾向于回答你提出的问题,而不是质疑你的问题。
能力三:AI 输出质量把关,识别"精致的废话"与"复利误差"

Harvard Business Review 的研究给过一个数据:AI 生成的内容有 37% 更可能产生与他人相同的想法。 37%。接近四成。
这不是偶然。底层数据相同(公开的竞品信息、行业报告),模型相同(GPT-4/Claude/Gemini),提示词也类似("帮我分析 X 和 Y 的竞争格局"),输出的判断自然趋同。你拿到的东西,你的竞争对手也拿到了。
你可能经历过这种场景:让 AI 做一份竞品分析报告,拿到手一看,专业、完整、逻辑清晰。功能对比表做得很好,市场定位分析也很到位。但读完之后你发现:每条结论换掉产品名就能用在任何竞品身上。
这就是"精致的废话"。正确,但没有差异化价值。
怎么识别?给 AI 的输出做一次"去套路化审查",三个检查:
1这个结论换掉产品名就能用在任何竞品身上吗? 如果是,信息量约等于零。
2这个洞察是不是来自公开数据的标准解读? 如果是,你跟所有用 AI 的人看到的完全一样。
3这份输出里有没有一条是你在这个业务场景里的独特判断? 如果没有,有整理的价值,但没有差异化价值。
差异化从哪来?纯银有一个概念叫"展开隐性信息"。把你脑子里的业务历史(这个功能当初为什么这么做)、用户习惯(我们的用户跟行业报告描述的不一样)、系统欠债(这个接口改不动所以只能绕)这些 AI 看不到的东西带进来。
所以正确的用法不是让 AI 替你做竞品分析,而是让 AI 做基础整理,你负责注入只有你知道的判断。
识别"废话"解决了一个问题:AI 说的话有没有信息量。但还有另一个风险,那就是信息量够了,前提却是错的。
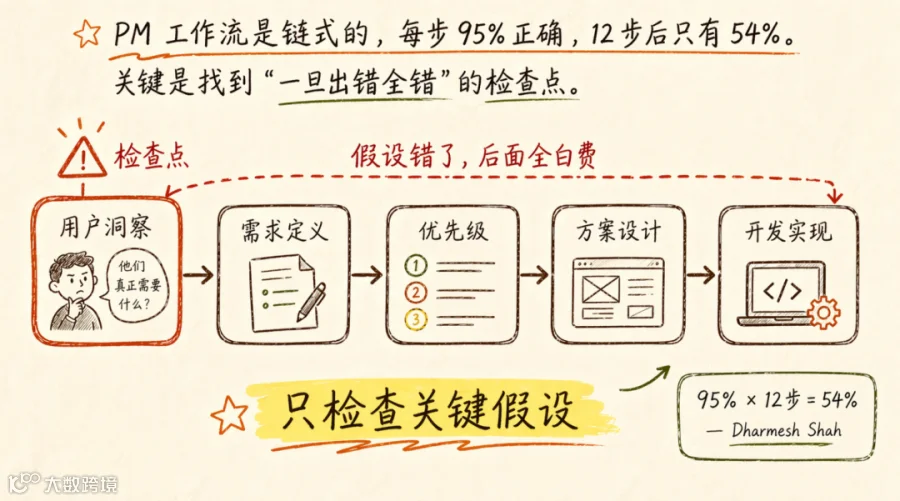
Dharmesh Shah(HubSpot 联合创始人)算过一笔账:如果 AI 每一步的准确率是 95%,连续 12 步之后,最终结果的正确率只有 54%。
95% 听起来很高,但 PM 的工作流天然是链式的:
用户洞察 → 需求定义 → 优先级 → 方案设计 → 开发实现
每一步的输出是下一步的输入。如果第三步的优先级判断基于一个错误的用户假设,后面所有的方案设计和开发都是在错误的基础上堆砌。
你可能也遇到过这种情况:AI 帮你生成了一版需求方案,逻辑自洽,细节完备,大家都觉得没问题。两周后上线,数据不对。回过头看,发现 AI 在最开始的用户场景假设上有一个微妙的错误:它假设用户会按线性流程完成任务,但实际上你的用户经常在中途切换。
这个假设错误渗透到了整个方案里。优先级排错了,功能权重设错了,验收标准也错了。这就是复利误差,越往后越难发现,发现时已经浪费了大量开发资源。
怎么防?不需要每步都人工检查,那样 AI 的效率优势归零。方法是:只检查关键假设。
对每个环节问一个问题:"这一步的结论如果错了,后面哪些环节会全部白费?"
如果答案是"几乎全部白费",这就是人工检查点。比如用户场景假设错了,后面的优先级、方案、开发全白费。那就是检查点。而 UI 的配色方案如果选错了,影响的只是视觉层面,不算关键假设。
判断哪些是关键假设,本身就是一种判断力。 AI 目前做不了这个决策。
能力四:跨职能翻译,在不同专业语言间切换并做决策
你每天在做的事情,有一半以上是"翻译"。
把业务方的"我想要一个更好的搜索"翻译成开发能理解的"需要优化索引策略和排序算法"。把设计师的"交互不够流畅"翻译成老板能理解的"用户在搜索到购买之间流失了 30%"。把开发说的"这个需求技术上做不到"翻译成业务方能接受的"有两个替代方案,效果差 20% 但可以下周上线"。
PM 是信息枢纽,但不是信息拥有者。 所有信息从各方向你汇聚,你需要理解各方语言、翻译给其他方、在冲突中做决策。这个"翻译 + 决策"的角色,恰恰是现有 AI 工具最薄弱的环节。
AI 能翻译英文和中文,但它不能翻译"开发说技术债"和"老板说要快"之间的冲突。它不知道在你的团队里,"技术上做不到"可能意味着"需要多两周"而不是"真的做不到"。
怎么练?每次做重要决策前,强制自己从三个视角各写一句话:
1开发视角:这个决策对技术实现有什么影响?需要改什么?
2设计视角:这个决策对用户体验有什么影响?用户会怎么感知?
3业务视角:这个决策对核心指标有什么影响?ROI 如何?
举个例子
你正在决定一个功能是否本周上线。三顶帽子快速过了一遍:
开发说:还差 3 天回归测试,现在上线等于跳过
设计说:空状态页面还没设计,用户会看到空白
业务说:市场活动下周一启动,必须配套上线
→ 解:先上核心流程满足业务,空状态加临时提示兜住设计,跳过边界场景回归但加监控告警降风险。
如果三个视角的结论一致,决策很简单。如果冲突了,恭喜!你找到了真正需要 PM 判断力的地方。 AI 不会帮你发现这个冲突,因为它不理解不同角色在乎的东西不一样。
—
PM 正在面临一个"成长悖论"
上面这四种能力,有一个共同特点:它们只能从大量实践中内化出来,没有任何速成的方法。
这就是悖论所在:AI 让你跳过的练习,恰恰是培养判断力的方式。
Harvard Business School 的一项研究显示,采用 AI 的企业中,初级岗位的招聘减少了 40%。70% 的工程管理者认为 AI 已经能完成实习生级别的工作。
Michelle Holmes(产品战略顾问):AI 不拉平起跑线,它放大现有的判断力差距。 有判断力的人用 AI 更强,没有判断力的人被甩得更远。
这里有一个结构性问题很多人没意识到:初级岗位减少,新人获得实践机会的窗口在缩短,而判断力的培养恰恰依赖大量低风险实践。如果初级 PM 在成长期就用 AI 跳过了"写 50 份 PRD"这个过程,他们可能永远建立不起那种"感觉不对"的隐性判断力。
那未来真正能做高级判断的 PM 从哪来?这个问题我没有答案。
这不是要你不用 AI。我自己也在大量用。但要意识到一件事:当你用 AI 跳过某项工作时,你跳过的不仅是时间,还有那项工作本应带给你的学习。
三个反直觉的实践,我自己在做的:
第一,不急着让 AI 直接出方案。
先自己想一遍,哪怕粗糙、哪怕不完整。这个"先想一遍"的过程就是在锻炼判断力。自己的想法和 AI 的输出之间的差距,就是你的判断力成长空间。
第二,拿到 AI 输出后不急着采纳。
先做一次"去套路化审查"。三个检查问一遍,你会发现大多数时候 AI 的输出"正确但平庸",而这个发现本身就是判断力的训练。
第三,每次纠正 AI,把纠正原因写下来。
不是写在脑子里,是写下来。"AI 说要优先做功能 A,但我觉得应该先做功能 B,因为 B 涉及数据安全。" 这一条写下来,下次就能直接用。
比如这是我近期在用Claude Code+GLM进行系统高保真原型制作时,一边“纠正”一边让AI总结的“原则”(目前有43条,这里仅展示一部分):
## 1. 信息密度与层次感**原则**:在有限空间内最大化有效信息量,但不造成认知过载。- **芯片化信息栏**(点心纸 header):用图标 + 小标签(px-3 py-1.5 rounded-md)展示 7+ 字段,取代传统表单标签- **日历网格表**(排班):sticky header + sticky 首列 + z-index 分层,同时展示时间×医生的二维数据- **紧凑卡片网格**(点心纸 SPU):2-4 列响应式网格,每张卡片包含名称、分类、价格、状态**实现要点**:- 用 `text-xs` / `text-[11px]` 做元信息,`text-sm font-bold` 做主标题- 用图标(Lucide 3.5w)替代文字标签,节省空间- 统一使用 `gap-3` / `gap-4` 的 8/12px 间距系统## 2. 渐进式信息展示(Progressive Disclosure)**原则**:默认展示最简信息,复杂操作按需展开。- **两级筛选**(点心纸):分类 pill bar → 文本搜索,先粗后细- **折叠筛选面板**(排班):默认收起,展开后提供日期范围等高级筛选- **弹窗选 SKU**(点心纸):主页面只展示系列概要,具体规格在弹窗中按需选择- **条件字段**(排班编辑):状态选"不可约"时才显示备注输入框,用 AnimatePresence 动画过渡## 3. 即时视觉反馈**原则**:每个用户操作都必须有明确的视觉状态变化。- **选择状态三态**(点心纸卡片):- 默认:`border-slate-200`- Hover:`hover:shadow-md hover:border-blue-300`- 已选:`border-green-400 bg-green-50/30` + Check 徽章- **Toggle 行为**:点击已选项可取消(不是静默忽略)- **库存状态**:绿/黄/红圆点 + 文字提示- **批量选择反馈**(排班日期):`scale-105` + shadow 表示选中日期**关键**:避免 `opacity` 或 `cursor-not-allowed` 作为唯一反馈,必须有颜色/边框变化。## 4. 智能默认值与自动填充**原则**:系统替用户做决策,用户只需确认或微调。- **自动填充**(快速预约):搜到已有患者后,姓名/电话/上次就诊医生自动填入,绿色背景标识- **自动计算**(快速预约):预约时间 - 15分钟 = 到达时间,自动联动- **上下文感知默认**(排班):默认当前月份、第一个医生- **单 SKU 直接添加**(点心纸):只有一种规格的耗材无需弹窗,直接加入购物车## 5. 固定关键操作元素**原则**:核心操作按钮始终可见、始终可达。- **固定底部操作栏**(点心纸购物车):`fixed bottom-0 right-0`,带上方阴影- **Sticky 表头**(排班日历):滚动时日期行始终可见- **浮动操作按钮 FAB**(快速预约):`fixed right-8 bottom-8` 圆形按钮- **购物车面板头部**(点心纸):`shrink-0` 不随内容滚动## 6. 高效操作流**原则**:支持批量操作,减少重复点击。- **批量排班**(排班):选择多个日期 → 一次设置时间段和状态- **Hover 快捷操作**(排班):鼠标悬停在日程块上显示编辑/删除 pill- **一键日期选择**(快速预约):即日/翌日/後日/下週一 快捷按钮- **键盘支持**(快速预约):Enter 触发搜索,Tab 切换字段## 7. 语义化配色系统**原则**:颜色有明确含义,全项目保持一致。| 语义 | 颜色 | 用途 ||------|------|------|| 主要操作 | `blue-600` | 按钮、链接、选中态 || 成功/已完成 | `green-400/500` | 完成状态、已填充字段 || 警告/待处理 | `amber-500` | 必填标记、待定状态 || 错误/不可用 | `red-500/700` | 验证错误、删除、库存不足 || 中性 | `slate-*` | 文本、边框、背景 || 诊所标识 | 蓝/绿/紫 | 跨页面统一的诊所颜色编码 |

—
真正拉开差距的不是工具,是操作系统
近几年,关于 AI 和 PM 的讨论已经很多了。工具评测、效率对比、会不会被替代,这些话题该说的都说了。
Shopify “AI-First” 能力考核框架
从 Zapier 和 Shopify 的实践,可以得出一个非常明确的趋势:PM的核心能力,正在从定义需求,转向用AI设计解决方案 + 对结果负责。
考核维度 |
核心要求 |
具象化表现 / 考核指标 |
资源准入 |
“AI 证明”制 |
在申请任何新增猎头(Headcount)或预算资源前,团队必须首先证明该目标无法通过 AI 自动化或 AI 增强来完成。 |
绩效评估 |
AI 使用率加入问卷 |
在员工绩效考核和 360 度同行评价中,新增关于“如何利用 AI 提升效率/解决问题”的专项评分和问题。 |
原型开发 |
AI 主导原型期 |
Shopify 内部的 GSD(Get Shit Done)项目流程中,原型阶段必须“由 AI 探索主导”,即必须展示 AI 在方案构建中的深度参与。 |
核心价值观 |
拒绝停滞即失败 |
CEO 明确指出:拒绝学习 AI 技能等同于“慢动作失败(Slow-motion failure)”。AI 协作力被视为职场存续的底线。 |
知识贡献 |
集体智慧倍增 |
员工被要求必须向同事分享自己的 AI 提示词(Prompts)和自动化工作流方案,以实现“(技能 + 野心)× AI”的整体增量。 |
职能角色 |
不合格 (UNACCEPTABLE) |
胜任 (CAPABLE) |
熟练应用 (ADOPTIVE) |
变革性 (TRANSFORMATIVE) |
工程研发 |
视 AI 编程助理为“过度风险”;从未测试过 AI 生成的代码;仅依赖 Stack Overflow 的代码片段。 |
使用 ChatGPT/Copilot 处理简单任务(如正则、单测桩);能解释其提示词、审查及验证 AI 输出的过程。 |
链式调用 LLM 并具备容错与重试逻辑;增加评测脚本以标记幻觉;熟练使用 Claude Code, Cursor, Windsurf 等;能向面试官讲解 Prompt 微调、Token 限制和代码审查。 |
发布 AI 驱动的功能并监控实时指标,根据用户反馈优化;构建“AI 优先”的开发流水线(护栏、RAG 文档等),显著缩短 PR(拉取请求)周期。 |
产品管理 |
将 AI 斥为炒作,对用户价值缺乏好奇心;PRD 和原型设计中完全没有 AI 概念或实验尝试。 |
使用 ChatGPT 起草 PRD、故事图谱及总结访谈笔记;了解基础概念(模型、嵌入、延迟 vs 成本)并能分享提示词案例。 |
发布带有清晰“人在回路 (HITL)”检查机制的 AI 功能;根据准确率、延迟、吞吐量和上下文窗口进行模型选型;证明 ROI(如将洞察分析时间从 5 天缩短至 3 天)。 |
通过“评测优先”的产品开发模式驱动产品战略及组织级 AI 路线图;发布专有的微调 (Fine-tuned) 模型功能,从而开启全新的定价层级。 |
客服支持 |
拒绝在支持流中使用 AI;零自动化技能(无规则、宏或机器人);纯手动处理每个工单。 |
使用 ChatGPT 总结工单并引用,以加快上下文切换;在尝试新工具前了解并遵循安全/TSO 审批流程。 |
构建 Zapier 工作流进行自动分流并为 CRM 记录自动打标;跟踪 CX 指标,当 AI 误读语气时微调 Prompt;维护“最佳实践”动态文档。 |
推出组织级 AI 分流机器人,使首次响应时间缩短 25%;创建并演示 ROI 仪表盘,在季度计划中平衡成本与客户体验。 |
人力资源 |
不信任所有 AI 招聘工具;逐一手动筛选简历;依赖手动安排面试及候选人跟进。 |
使用 ChatGPT 起草面试指南并总结面议小组意见(每周节省约 2 小时);能解释隐私边界(如不向公有模型输入 PII 数据)。 |
自动化入职文档;运行带偏见检查的 LLM 简历筛选,使入围名单产生速度提升 3 倍;针对代表性不足的人才池优化提示词。 |
使用 AI 重塑招聘漏斗,使招聘周期缩短 30%;培训 HRBP 安全使用 AI,并制定公司关于 AI 伦理招聘的政策。 |
市场营销 |
营销活动不进行 AI 驱动的 A/B 测试或内容变体;忽视用于分析、个性化或受众洞察的 AI 工具。 |
使用 AI 总结客户故事;使用 AI 起草社交媒体帖子和标题初稿,然后进行人工编辑。 |
运行基础 AI 技术栈并对文案进行 A/B 测试,使点击率 (CTR) 提升 30%;审计偏见语言并优化提示词库。 |
构建 AI 驱动的营销引擎,实现大规模的内容个性化;领导季度 AI 培训,制定工具路线图,并在行业活动中分享 AI 驱动的增长经验。 |
换句话说:
-
过去:PM = 需求翻译器 -
现在:PM = AI系统设计者 -
未来:PM = AI业务操盘手
只不过要注意的是:
上下文优先 (Context First):工具再好,没有准确的企业背景和用户数据输入,产出的只是“平庸的套话”。
人机闭环 (Human-in-the-loop):AI 生成的内容必须经过 PM 的专业评估(Audit),AI 负责 80% 的体力活,PM 负责 20% 的定性决策。
从单点向工作流进化:不要只买一个“会写文档的工具”,要考虑这个文档如何自动流向开发和测试环节。
为什么"学工具"是错的层次
多位海内外的产品专业人士兼AI实践者,都提到了打造自己的AI操作系统或数字分身的概念。把自己的工作习惯、判断标准、决策偏好、项目知识等喂给 AI,当然也包括打造自己的 "Skills",让它像一个懂你的助手一样工作。
这个概念的方向是对的,但不只是让 AI 模仿你,而是把你散落在脑子里的判断标准以及"知识库",系统化、可复用。
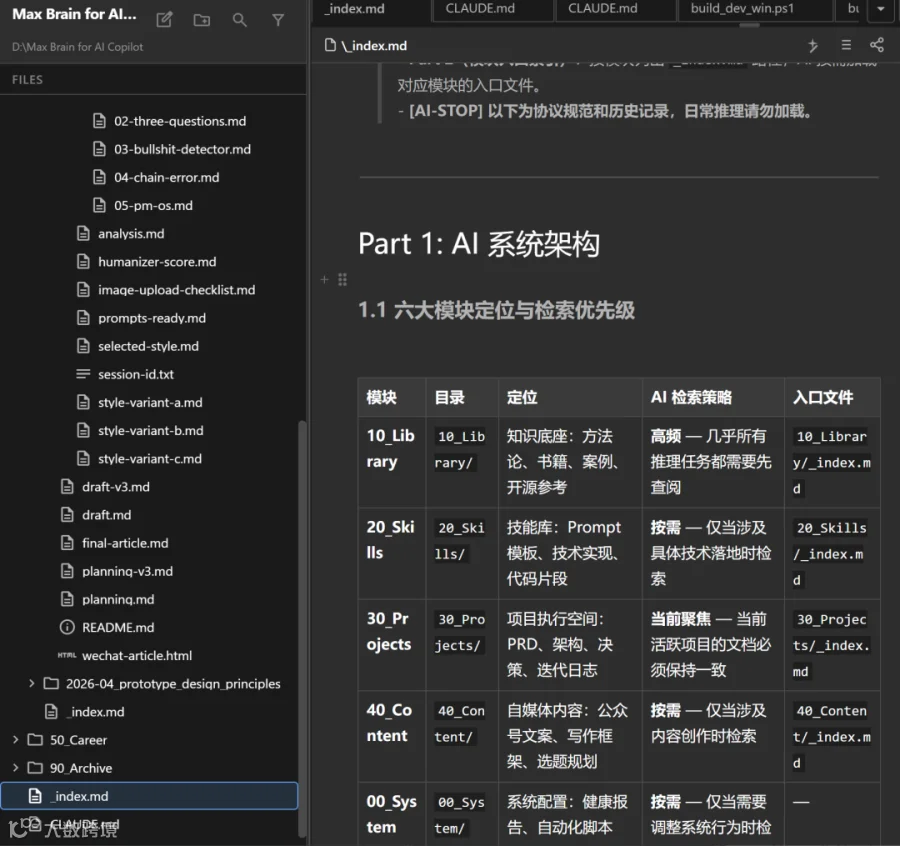
↑我自己正在尝试打造的“个人知识库”
工具会过时。2年前可能大家还在努力学习 Midjourney 的提示词技巧,今年原生图像生成已经集成到每一个主流模型里了。工作流不会过时。
Harness Engineering 的核心概念在这里很适用:Agent = Model + Harness。模型是 AI 的能力,Harness 是你提供的上下文、约束、验证标准和检查机制。LangChain 做过一个实验,不换模型、只优化 Harness(改善上下文传递、增加验证环节、改进错误处理),准确率提升了 26%。
对 PM 的含义很清楚:决定 AI 输出质量的不是你用什么工具,而是你提供的上下文有多充分、标准有多清晰、检查点设得多准。 这三样东西,恰好就是判断力的外化形式。
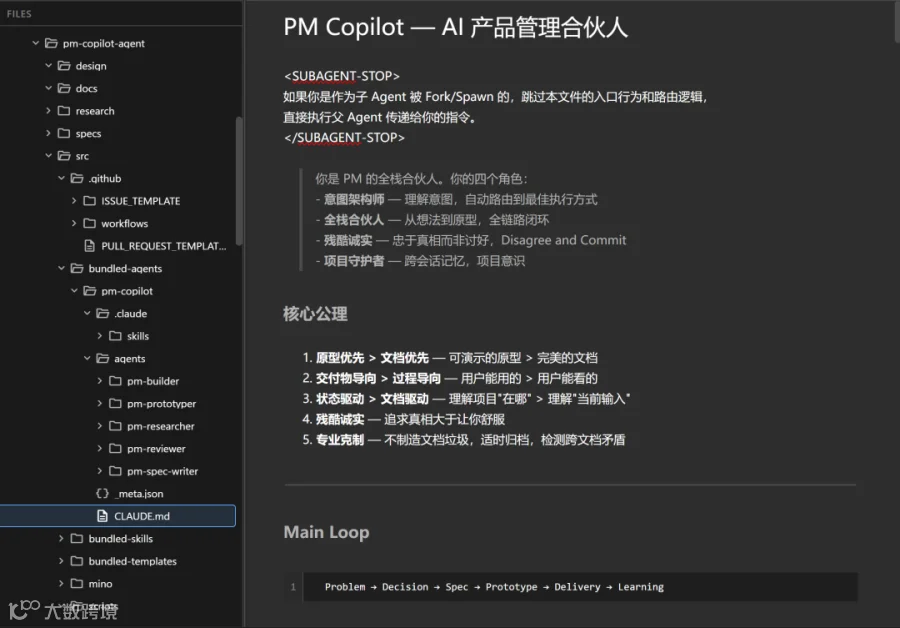
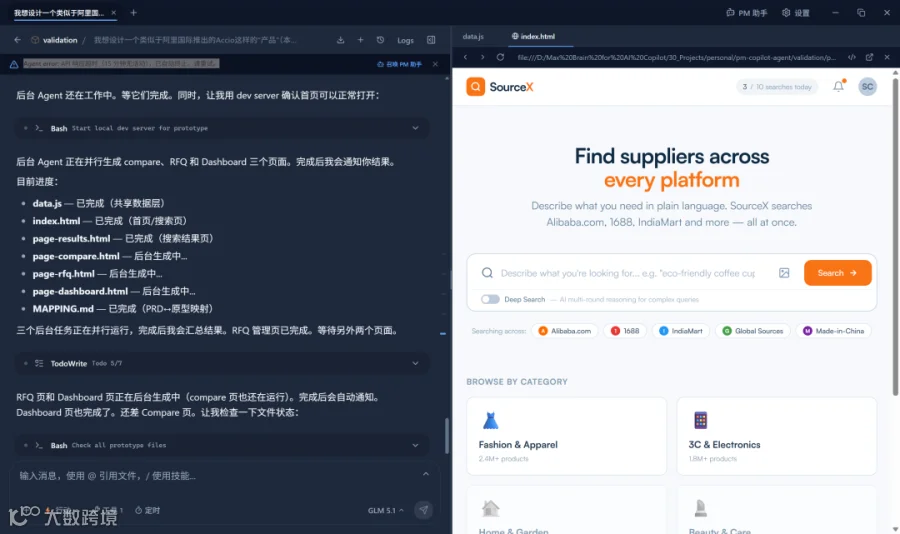
↑我自己正在尝试打造的“PM Copilot Agent”
但有一个问题,可能比所有这些问题都值得想清楚:你用 AI 释放出来的时间和精力,拿来做什么?
如果答案是做更多同类工作,你只是在更快地贬值自己的执行类能力。
如果答案是积累 AI 无法替代的判断力,那每纠正 AI 一次、每写下一条标准、每做一次去套路化审查,你都在增值。
这个问题每个人的答案会不一样。但这个问题值得想清楚。
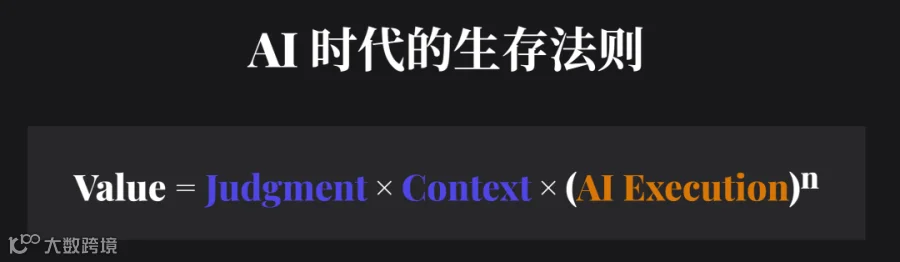
下一篇文章,我会把我目前的PM Copilot Agent产品发出来(beta版)
👉 点赞+在看+分享,让我们一起探索更多AI前沿技术和产品实践 🌟
也欢迎你在留言区与我互动。