
本文是JiuwenSwarm系列技术博客的第四篇。上一篇我们看到自演进机制如何让Agent越用越聪明,而这一切的前提,是系统得先「记得住」。本篇拆解JiuwenSwarm的记忆引擎和上下文工程:它如何跨对话持久记忆,如何在有限的上下文窗口里装下长任务,又如何在多 Agent 团队里共享记忆而不打架。
往期回顾
1. openJiuwen
2. JiuwenSwarm:智能体学会“养蜂”,从单兵作战到兵团作战
3. JiuwenSwarm的协同工程范式:从「调教一只」到「编排一群」
让Agent越用越聪明,有个前提:系统得先 "记得住" 用过的经验。这篇就来拆解这个前提背后的两套机制:记忆引擎和上下文工程。
它要回答三个问题:Agent如何跨对话持久记忆,如何在有限的窗口里装下长任务,又如何在多Agent团队里共享记忆而不打架。
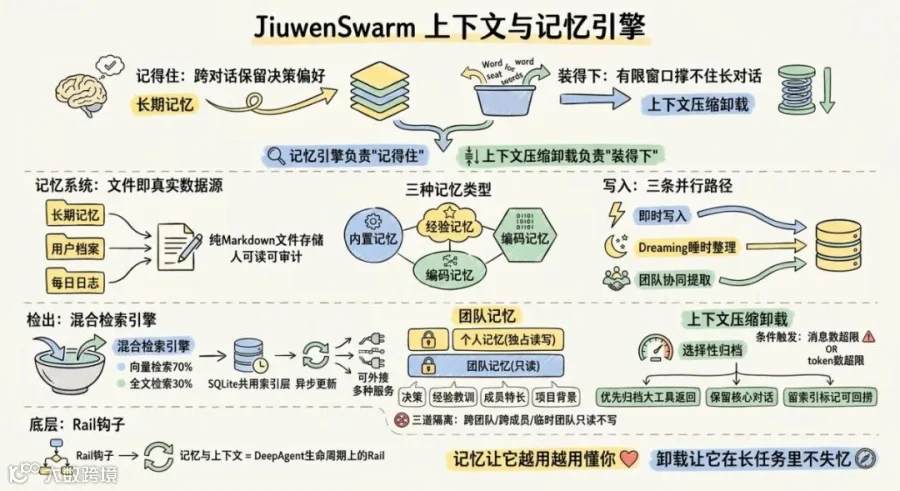
一、两个方向相反的压力:记得住 vs 装得下
长程任务里,Agent同时被两股相反的力拉扯。
一方面,它需要 "记得住":跨对话、跨会话地保留决策、偏好和经验教训,不能每开一个新对话就失忆。今天聊清楚的项目背景,明天不该从头再交代一遍。
另一方面,它又得 "装得下":上下文窗口是有限的,长对话、大工具返回、长文件很快就能把窗口撑爆。聊到第 50 轮,早期信息被截断,Agent开始忽略前面说过的关键细节。不是模型记性差,是token窗口有上限,而对话历史在线性增长。
这是两个相关、但本质不同的痛点。JiuwenSwarm把它们分开处理:记忆引擎负责"记得住",上下文压缩卸载负责"装得下"。 两者共享同一个设计哲学:把上下文和记忆都当成模型之外、需要被工程化管理的资源。

这套设计的有效性有据可查:在长期对话记忆权威评测集LOCOMO上,JiuwenSwarm用 8B 模型就实现了 85%的准确率,优于业界主流记忆系统。下面一层层看它是怎么做到的。
二、记忆系统总览:文件即真实数据源JiuwenSwarm的记忆系统通过一个配置项控制四种工作模式:仅内置(默认)、仅外接、两者并存、全部关闭。 内置记忆有一个很关键的设计取向,叫 "文件即真实数据源":记忆用纯Markdown文件存储,Agent通过标准文件工具(读、写、编辑)直接操作,没有额外的存储层抽象。这些文件分三层:
用文件而非黑盒数据库做真实数据源,意味着记忆是人可读、可审计、也可以手工编辑的。文件可以直接打开看、直接备份、直接分享。这恰好接住了整个框架"可控、可驾驭"的取向。 记忆没有用"一种走天下"的做法,而是按场景分了三类。 
|
三、记忆怎么写进去:三条互补路径
记忆的写入不是单一入口,而是三条路径并行。

第一条是会话内即时写入。 Agent在对话过程中主动调用文件工具写记忆。决策和偏好进长期记忆文件,用户信息进用户档案,日常笔记进当天日志。这是最直接的一条,覆盖"用户明确要求记住"和"Agent 判断应该记住"的信息。
第二条是Dreaming睡时整理。 这个设计很有意思。很多信息散落在对话历史里,单看不值得记,汇总起来却很有价值。Dreaming就做这件事:它是一个后台离线机制(默认关闭),由编排器周期性触发LLM扫描历史会话,像人睡觉时整理白天的记忆一样工作。Agent模式下提取用户偏好、背景,写入整理文件(最多 50 条);Code模式下提取调试根因、接口边界行为、设计决策,按内容去重写入。
Dreaming的工程细节透着一股"不打扰"的克制:默认 4 小时触发一次、启动后 120 秒首次扫描,Agent正忙着处理请求时会退避跳过,并用断点记录已处理的会话做增量扫描,避免重复劳动。
第三条是Agent Swarm团队协同提取。 在多Agent团队里,Leader在每个协作轮次结束后自动提取团队记忆。这条路径牵出团队场景的特殊设计,下文专门展开。
四、记忆怎么读出来:混合检索引擎记忆存多了,"怎么找回最相关的那条"就成了核心问题。JiuwenSwarm用的是混合检索:全文检索与语义检索两条腿走路。 全文检索做关键词精确匹配,无需额外配置;语义检索按意图模糊召回,需要配嵌入模型。系统默认两者结合,用一个加权公式合并分数:向量得分占七成,全文得分占三成。 
这个七比三的默认权重透露了设计倾向:以语义召回为主、关键词匹配为辅。 道理也直白。用户很少精确记得"上次说的那句话原话是什么",更多是"我们聊过关于XX的事"。语义检索抓得住"意思相近但用词不同"的记忆,全文检索则保留了精确命中的能力。 承载这套检索的核心组件是共用索引层,基于SQLite,包含全文索引表和向量索引表。它负责记忆持久化,用文件监控机制异步更新索引,并按需读取以保持上下文精简。嵌入模型通过环境变量配置,不配则退化为纯文本检索。除了内置,还支持外接多种服务:本地长期记忆、云端事实抽取、字节上下文数据库,以及自定义插件。 |
五、团队记忆:多Agent怎么共享而不打架
到了多Agent团队场景,记忆冒出一个新难题:多个成员同时读写,怎么不冲突、不串味?
JiuwenSwarm的答案是双层记忆架构。
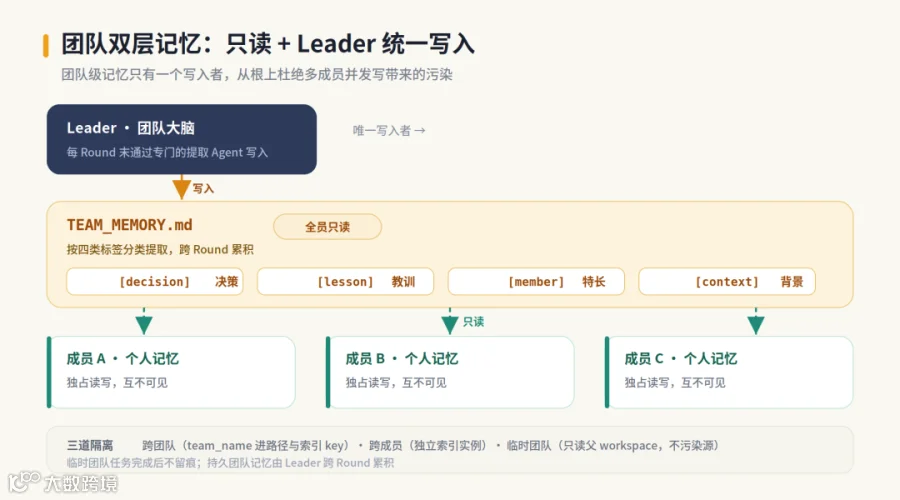
-
• 个人记忆由每个成员独占读写; -
• 团队记忆则对所有成员只读,由Leader在每个协作轮次末通过专门的提取Agent自动写入。
提取的内容用四类标签分类:决策类(为何选A不选B)、经验教训类(什么有效、什么导致返工)、成员特长类(谁擅长什么)、项目背景类(业务约束、截止日期)。
"只读 + Leader统一写入"是这里的关键防冲突设计。 团队级记忆只有一个写入者,从根上杜绝了多成员并发写带来的污染。隔离机制还做了三道:跨团队隔离(团队名进路径和索引键)、跨成员隔离(每人独立索引实例)、临时团队只读不写(不污染源记忆)。临时团队任务完成后不留痕,持久团队的记忆则由Leader跨轮次累积。
六、上下文压缩卸载:在有限窗口里装下长任务记忆解决"记得住",上下文压缩卸载解决"装得下"。文档给的比喻很形象:像"整理办公桌"。桌面(上下文窗口)堆满时,把"大而次要"的东西归档进抽屉,桌面上只留一张索引便签。 
它不是无差别压缩,而是按条件触发的。两个阈值是OR关系:消息数超过上限(比如 3 条),或token数超过上限(默认 20000)。触发后的策略是选择性归档:用"大消息阈值"来界定哪些内容值得优先处理,用"消息角色过滤"来决定只压缩哪类消息。典型配置是只压缩工具返回的冗长数据,保留用户和助手的核心对话。 这套设计的关键在于"选择性"和"可检索"两点。它不会粗暴砍掉旧消息,而是优先归档"大而次要"的工具返回;归档后还留一个索引标记,需要时能把内容再捞回来。两个保护机制兜底:强制保留最近若干条消息不被压缩,确保最新一轮完整对话完整保留。 在中文政务这类场景里,这套机制还能进一步适配:对高频政务术语设保护词表、对政策原文保留更完整上下文,对"收到""已阅"这类重复通信做更大胆的过滤。 |
七、工程底座:挂在生命周期上的一组Rail
把视角拉回Rail机制会发现,上下文和记忆的能力,同样是挂在DeepAgent生命周期上的一组Rail。
-
• 静态提示词由一个扩展版的提示词构建器管理,按身份、安全、技能、工具、记忆、上下文等分区组织; -
• 动态内容由提示词附件管理器按会话和分区存储,以独立消息注入(适合长文件、心跳、记忆召回)。
上下文侧有两条Rail:一条负责注入工作区结构、上下文文件和工具列表,另一条负责压缩长对话、卸载大工具结果、修复不完整的调用。记忆侧则是三条Rail:通用长期记忆Rail、项目记忆Rail(向量和BM25混合检索,注入最相关的五条)、外部记忆Rail(预取、同步、熔断)。
换句话说,记忆和上下文管理不是外挂功能,而是从架构层面就编织进Agent生命周期的能力。
八、小结:记忆让它"记得住",卸载让它"装得下"
JiuwenSwarm的上下文与记忆引擎,说到底是在"有限窗口"和"无限任务"之间架了一座桥:
-
• 记忆引擎用"文件即真实数据源"加三类记忆、三条写入路径和混合检索(语义七成、关键词三成),让Agent跨对话记得住; -
• 团队记忆用"只读 + Leader 统一写入"的双层架构,让多Agent协作时记忆共享而不冲突; -
• 上下文压缩卸载用"选择性归档 + 可检索索引",让Agent在有限窗口里装得下长任务。
记忆让它越用越懂你,卸载让它在长任务里不失忆。 两者合起来,才撑得起前几篇讲的长程任务、多Agent协作和自演进。而要把这些任务真正有条不紊地推进,还需要一套任务规划系统,那是下一篇的主题。
更多JiuwenSwarm信息,请参见官网:
官网地址:https://www.openjiuwen.com/
AtomGit: https://atomgit.com/openJiuwen
PS:
最后,做个小小的推荐,目前正在进行的两个项目:
Agent Insight:openEuler孵化的项目,旨在让每一个Agent 都可被观测、可被评估、可自我进化。
Skill Radar:给Agent Skills技术画一张”活地图”,追踪Skills技术,让Agent能力进化有迹可循。
如果你对Agent Insight感兴趣,欢迎参与进来,一起把它变得更好~~
🔗 仓库地址:https://atomgit.com/openeuler/agent-insight
更多Agentic AI技术前沿分享,欢迎扫描下方二维码进入技术交流群(或者添加群助手ID:qstarsky 邀请您进群交流)

往期回顾
往期回顾
1. openJiuwen
2. JiuwenSwarm:智能体学会“养蜂”,从单兵作战到兵团作战
参考资料
-
1. 官网地址:https://www.openjiuwen.com/ -
2. AtomGit: https://atomgit.com/openJiuwen -
3. openJiuwen官方文档:https://openjiuwen.com/docs-page?path=%E4%BA%A7%E5%93%81%E7%AE%80%E4%BB%8B