

近年来,语音合成和歌声生成技术快速发展,AI 已经可以生成越来越自然的人声。但一个更接近真实表达的问题仍然存在:
如果一段文本里既有普通叙述,又有歌词、哼唱或旋律化表达,AI 应该把它“读出来”,还是“唱出来”?
在日常交流中,说话和歌唱并不是完全割裂的。我们可能在讲故事时哼出一句旋律,也可能在播客中自然唱出一句歌词。但现有的音频生成模型只会生成单一模态的音频,无法在一句话里做到“又说又唱”。
TTS 模型擅长说话,音乐模型擅长唱歌,统一音频生成模型也通常需要显式提示来决定输出模式。
UniVocal 正是为了解决这一问题而提出。它让模型能够仅根据文本语义,自主判断什么时候应该说话,什么时候应该歌唱,从而生成自然连续的语音-歌声混合人声。

(不同音频生成任务的图例)
▎什么是 SCS?
UniVocal 提出了一个新的任务:Speech-Singing Code-Switching Synthesis,简称 SCS。
简单来说,SCS 要求模型输入一段普通文本,输出一段连续人声,并在其中自动完成说话、歌唱或哼唱之间的切换。与依赖<speech>、<sing> 等显式控制标签的方法不同,SCS 更强调模型通过对文本语义的理解,自然地生成模态切换的声音。
例如,当文本中出现 “That reminds me of a little tune...” 这样的表达时,模型需要意识到后续内容可能进入歌唱模式;而当文本中出现 “Mmm-hmm, mm-mm...” 这样的哼唱片段时,模型也应生成哼唱的声音。
因此,SCS 并不是简单地把语音和歌声拼接起来,而是一个同时涉及文本理解、韵律建模和说话人一致性保持的任务。
UniVocal 的核心设计可以概括为两个部分:
两阶段课程学习,以及基于 refined cent token 的思维链(CoT)规划机制。
首先,UniVocal 采用两阶段课程学习策略。
第一阶段:继续预训练。使用960 小时语音和 3700 小时歌唱数据进行继续预训练,旨在建立两种人声模式的统一表征空间。这一阶段利用开源模型(CosyVoice 2 的 LM 与 Flow Matching 结构)以及公开数据集(LibriTTS、Suno),使模型具备基础语音生成与歌声合成能力。
第二阶段:SCS微调。引入260小时的合成语音-歌声语码转换(SCS)数据,训练模型根据文本语义自动触发模式转换。为了避免模型在学习 SCS 时遗忘原有能力,训练中还会继续混合少量的原本的语音和歌声数据(各200小时)。
这种课程学习的方式相当于先让模型打好“说话”和“唱歌”的基础,再让它学习更复杂的“何时切换”。
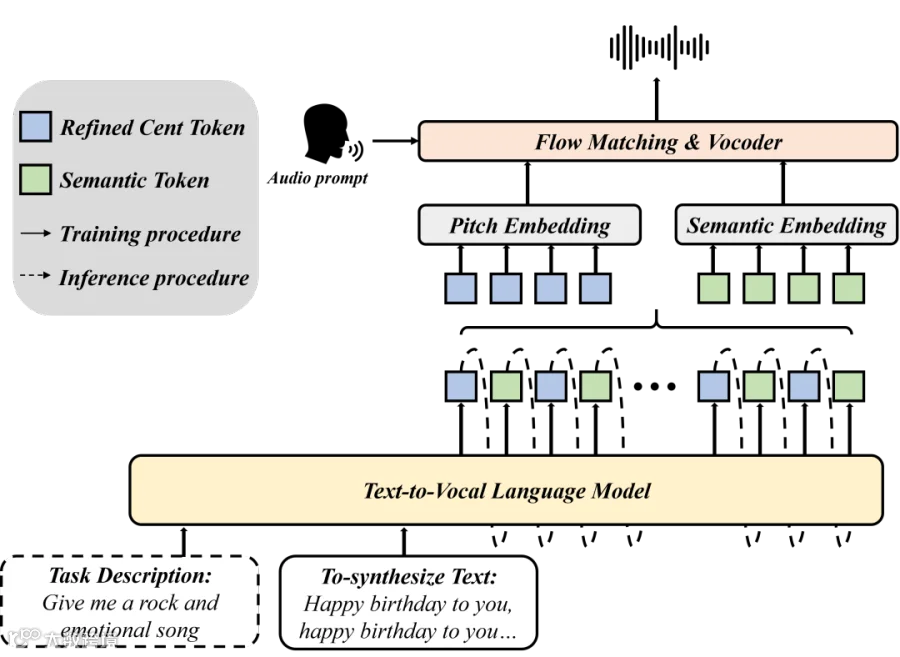
(图示:UniVocal模型结构)
另一方面,UniVocal 还引入了 refined cent token 来增强音高建模能力。
现有cosyvoice 2采用的是ASR任务的semantic tokenizer,这种tokenizer能够捕获“怎么说”的内容语义,但容易丢失“怎么唱”的声学细节,如对于歌声和情感语音而言非常关键的音高、韵律和旋律信息。
因此,UniVocal 提出了一种refined cent token,其物理意义是高分辨率的离散音高表征。它将连续的基频(F0)轨迹量化到以细化音分为单位的空间中,这种细粒度的token既能表征歌唱的旋律也能捕捉语音的韵律。生成采用类似思维链(CoT)的“先规划、后生成”(Plan-then-Generate)模式。
模型在每一时间步首先预测 refined cent token,完成音高与韵律轮廓的规划;随后以此为条件预测语义 token,生成最终人声。这种 plan-then-generate 机制有助于提升歌声旋律表现,也能增强情感语音中的韵律自然度。
真实世界中,同时包含说话、歌唱和哼唱自然切换的数据非常稀缺。为了让模型学会“什么时候说、什么时候唱”,UniVocal 构建了一套可扩展的数据合成流程。
系统首先利用大语言模型生成自然脚本,覆盖生活中常见的场景,并在文本中设计不同类型的切换线索:一类是显式触发短语,例如 “It goes...” 这类显式文字提示;另一类是隐式线索,例如普通叙事的文本和歌词表达本身具有明显的语义区别。
随后,UniVocal 使用第一阶段训练得到的模型合成语音段和歌声段,并尽量保持同一说话人的音色一致。最后,利用 WER 等指标进行质量过滤,去除发音错误或对齐问题严重的样本。
最终,研究构建了约11,769 条、262 小时的语音-歌声代码切换数据,并进一步形成了覆盖不同场景和线索类型的评测集 SCSBench。
▎实验结果:切换更准,声音更自然
为了评估模型的语音-歌声切换能力,论文构建了SCSBench,并设置了三类测试子集:
SCSBench-Implicit:只包含隐式语义线索;
SCSBench-Explicit:包含显式触发短语;
SCSBench-Mixed:同时包含显式与隐式线索。
在实验中,UniVocal 对比了由其他语音合成模型与音乐生成模型手动“拼接”而成的级联系统(Cascaded Systems),级联系统在做SCS切换时,由Gemini 2.5 Pro给出不同模态的判断。
实验结果显示,UniVocal 在 SCSBench-Mixed 上取得了 0.871 的客观 F1 和0.810 的主观 F1,优于多个级联式基线系统。这说明 UniVocal 在不同的场景下均学会了根据文本语义判断说话与歌唱的切换边界。
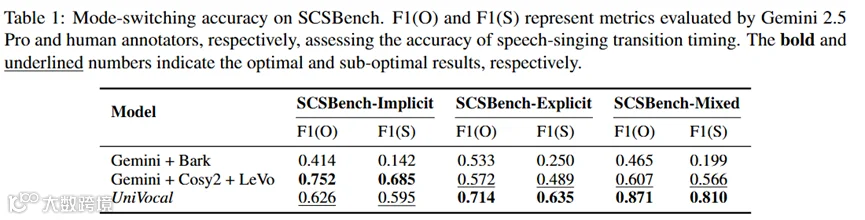
(图示:语音-歌声切换的准确率)
除了切换准确性,UniVocal 在生成质量上也表现稳定。在 SCSBench 中,UniVocal 获得了较低的 WER 和较高的 UTMOS,说明模型不仅能判断“什么时候唱”,也能更好地保证生成内容清晰、声音自然。
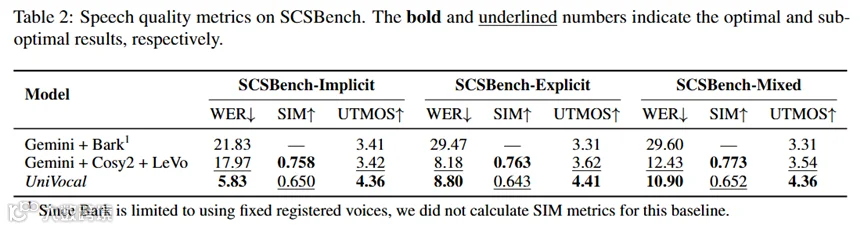
(图示:SCSBench 上的语音质量指标)
对于语音-歌声切换任务来说,还有一个容易被忽略的问题:切换之后,声音还能不能像同一个人?如果说话段和歌唱段听起来像两个不同的人,即使切换位置正确,整体听感也会受到影响。
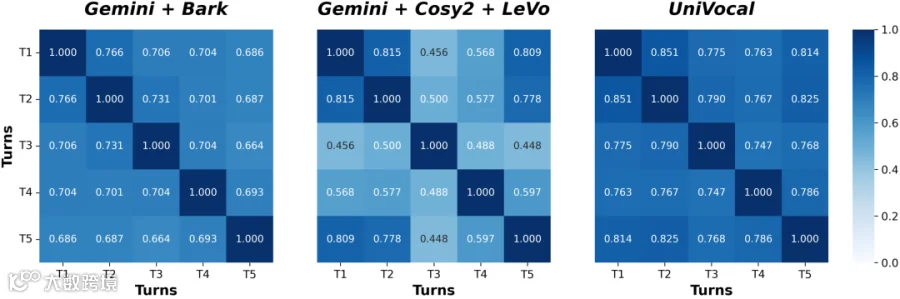
(图示:SCSBench上的说话人一致性)
如图所示,论文进一步分析了同一个生成样本内不同时间片段之间的说话人一致性。结果表明,相比级联系统,UniVocal 在说话与歌唱切换过程中能够更好地保持同一说话人的音色特征,从而减少模式切换带来的音色漂移。
相关文献参考:
[1] Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingchen Shu. 2025. IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto- Regressive Zero-Shot Text-to-Speech. arXiv preprint arXiv:2506.21619
[2] Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, and 1 others. 2024b. Cosyvoice 2: Scalable streaming speech synthesis with large language models. arXiv preprint arXiv:2412.10117
[3] Shun Lei, Yaoxun Xu, Zhiwei Lin, Huaicheng Zhang, Wei Tan, Hangting Chen, Jianwei Yu, Yixuan Zhang, Chenyu Yang, Haina Zhu, and 1 others. 2025. Levo: High-quality song generation with multi-preference alignment. arXiv preprint arXiv:2506.07520.
[4] Yu Zhang, Ziyue Jiang, Ruiqi Li, Changhao Pan, Jinzheng He, Rongjie Huang, Chuxin Wang, and Zhou Zhao. 2024a. Tcsinger: Zero-shot singing voice synthesis with style transfer and multi-level style control. arXiv preprint arXiv:2409.15977.
[5] Dongchao Yang, Jinchuan Tian, Xu Tan, Rongjie Huang, Songxiang Liu, Xuankai Chang, Jiatong Shi, Sheng Zhao, Jiang Bian, Xixin Wu, and 1 others. 2023. Uniaudio: An audio foundation model toward universal audio generation. arXiv preprint arXiv:2310.00704.
[6] Xueyao Zhang, Junan Zhang, Yuancheng Wang, Chaoren Wang, Yuanzhe Chen, Dongya Jia, Zhuo Chen, and Zhizheng Wu. 2025b. Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning. arXiv preprint arXiv:2508.16332.