

6 月 13 号下午我刷开发者群,一半人在骂 Anthropic 突然砍了海外用户的访问权限,存了半个月的项目上下文直接没了,另一半人在发智谱刚更的 GLM-5.2 截图。
没有发布会,没有通稿刷屏,就这么直接放出来了。
官方的说明很短,只说这是迄今最强的开源模型,支持 100 万 token 上下文,还是他们心中最强的国产 Coding 模型,下周按 MIT 协议全量开源。最戳人的是开头那句话:「在一些前沿模型突然变得不可用的时刻,我们选择相信另一条路。」
我翻了全网能找到的所有外部实测,把最真实的感受整理出来。
01先看最直观的:写代码到底能不能打
测试用的是同步更新的 ZCode 3.0,就是智谱专门做的 AI 编程桌面端,权限开了完全访问,省得每一步都要确认。

第一个需求很简单,写个带 AI 对战的五子棋,分三个难度。它先让我选技术栈,我选了 Web 单文件,大概十几分钟,一个完整的网页版五子棋就出来了,界面很清爽,规则没毛病,新手难度我随便赢,普通难度要费点劲,困难模式我连下了三局都没赢过。

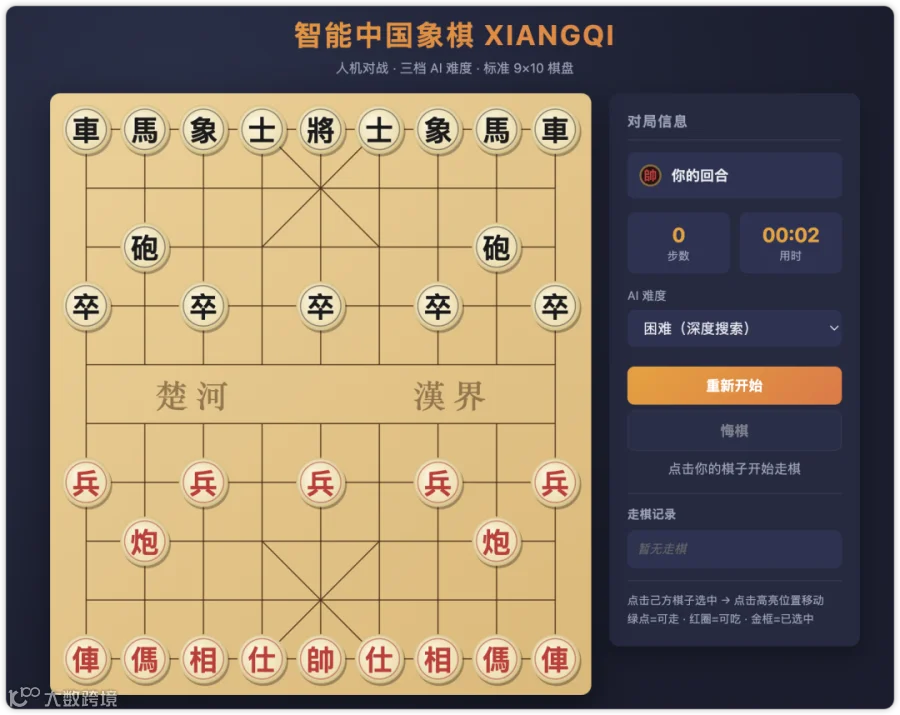
第二个需求是同样带三档难度的中国象棋,这次界面也没问题,能正常跑,但三个难度其实没拉开差距,本质都是新手级,我调了半天参数才改对,属于大方向没问题,细节要补的类型。

有媒体做了更复杂的三个测试,难度比小游戏高了不少。第一个是纯 SVG 写的机械天文钟,要做五层同心结构、齿轮转动、月相变化、控制面板,它一次写了 900 多行代码,首版打开就能跑,发现月相逻辑有问题之后,没有凑活改,直接推倒重写了整套逻辑,还自己做了边界相位验证,新月、上弦、满月、下弦全部符合天文规律。

第二个是 3D 点球大战,要用 Three.js 和 Cannon.js 做物理引擎,还要做 AI 门将扑救逻辑。它先把整个游戏骨架搭通,再逐步填细节,甚至专门查了西甲门将扑救的生物力学论文,把动作拆成蹬地、横移、伸手三个阶段,完全符合真实的运动规律,最后做出来的游戏除了画质朴素点,可玩性一点不差。


第三个是复刻迷你 Excel,要支持网格编辑、公式计算、撤销重做、CSV 导入导出,它跑了整整一个小时,把 Excel 的核心功能全部在浏览器里实现了,唯一的问题是中间有十几分钟只有思考过程,没有输出可运行的代码,我好几次都以为它卡住了。

能做到这个程度,已经超过了绝大多数开发者的预期。
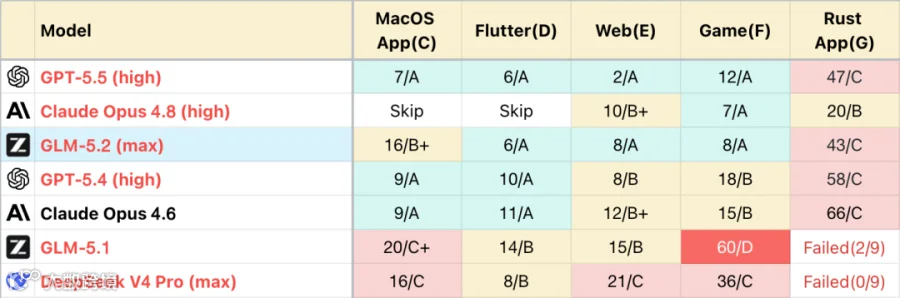
第三方的编程测评榜单也印证了这个感受,在 5 个公开的工程测试里,GLM-5.2 拿到了 3 个 A 档,A 档意味着几乎不用用户干预就能一步到位,这个成绩和 Claude Opus 4.8 持平,而且完成同样的项目,它的 token 消耗比 Opus 还要低 30 %左右。
02100 万 token 的长上下文,真不是噱头
很多人没注意到,这次 GLM-5.2 最大的升级其实不是代码质量,是把上下文窗口从之前的 20 万直接拉到了 100 万,输出上限也提到了 13.1 万 token。
我猜很多人一开始看到这个数字,第一反应是「噱头吧,能真的用上?」至少我一开始是这么想的。
实际用下来才知道这个升级有多实用。之前写稍大一点的项目,模型经常会忘了最开始的需求,或者漏看前面写的代码逻辑,要反复把上下文贴回去,100 万 token 的窗口,意味着你可以把一整个中型仓库的所有源码、配置文件、测试用例,甚至整个对话历史全部放进去,不用再反复压缩、粘贴上下文。
有早鸟用户让它自主搭建网页版音乐合成器,整个任务跑了四个小时,17 万 token,从写代码到跑测试到修 bug 全程没人插手,换做上一代模型,中间大概率就会因为上下文溢出忘记需求。还有人拿它分析一个月的服务器日志,几十万 token 的原始数据,它从最开头一条毫不起眼的日志里,找到了半个月后系统故障的早期预警信号。
这种感觉没用过的人很难懂。
大模型观测员的测评里也提到,GLM-5.2 的产出代码量比其他被测模型平均高 30 %,却很少出现因为看漏代码细节导致的 bug,足以证明这个 1 M 上下文的含金量,不是虚标。
03别着急当默认主力,这些坑得提前知道
但我劝你别着急把所有任务都切到 GLM-5.2,至少先看看这些真实踩过的坑。
第一个坑是细节可靠性还不够稳。海外有博主拿它做 3D 潜行游戏,结果光照太暗几乎看不清,做恐怖游戏,钥匙收集齐了却没触发怪物追逐的逻辑,做 MC 克隆版,界面出来了角色却不能动。它往往能把整个项目的架子搭得很完整,却会在交互、触发条件、视觉细节这类地方掉链子,要是你指望它一次性产出高细节的成品,大概率要返工两三轮。
额度这件事,比模型能力更能决定你能不能长期用它。
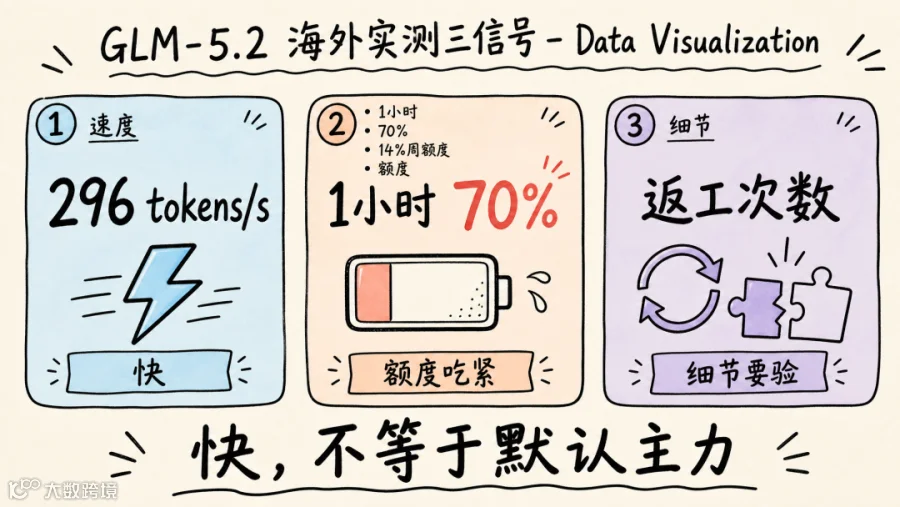
官方的规则是,GLM-5.2 属于高阶模型,高峰期(每天 14:00-18:00)调用要扣 3 倍额度,非高峰扣 2 倍,9 月底之前非高峰有 1 倍的福利。而且 Coding Plan 不是无限量,有每 5 小时限额和每周限额,Lite 版每 5 小时只能用 80 次 prompt,Max 版是 1600 次。更重要的是,你发一次 prompt,Agent 背后可能会触发 15-20 次模型调用,海外有博主重度测试 1 小时,就用掉了 70 %的 5 小时额度,还有 14 %的周额度。

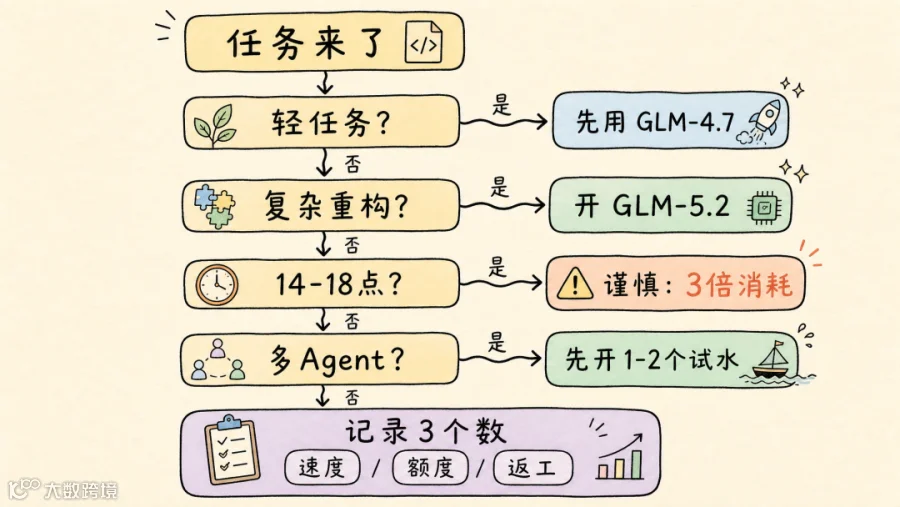
所以它其实不是适合所有任务的默认主力,更像工具箱里的重任务档:跨文件 debug、大型工程改造前的方案规划、长上下文代码阅读、多约束冲突判断,这些任务用它很合适。如果只是写小函数、改个简单脚本,用 GLM-4.7 反而更划算,也更快。
04开源这件事,比模型本身影响更大
比模型能力更值得聊的,是智谱这次选的 MIT 开源协议。
这个协议有多宽松?你可以免费下载权重,可以自己修改,可以用来做商业产品,甚至可以二次封装了卖,只要保留原作者的版权声明就行,没有地域限制,没有使用门槛。
换句话说,你不用担心哪天早上起来,这个模型突然就不能用了,也不用因为是海外模型,要折腾各种访问渠道,甚至有能力的团队,直接下载权重自己部署到本地,数据都不用出域。

昨天我把 GLM-5.2 写的五子棋发给了我做前端的朋友,他玩了两局,输了。
他问我这东西在哪能试。
我说,现在就能。

