
背景

Atypica 是一个消费者研究的智能体。
目标是让 AI 能独立完成用户研究:
规划研究项目
通过社交媒体拟合虚拟消费者
进行消费者访谈
生成洞察报告
这篇文章记录了研发过程的经验教训,以及提炼出的一套通用企业级智能体架构思路(GEA - Generative Enterprise Agent)。
挑战

消费者研究不是确定性交付产出的工作,而是具有「探索性的知识工作」。
具体的挑战如下:
问题1:用户的需求模糊
用户会问:"想了解年轻人对咖啡的偏好"
但这不够具体:
哪个年龄段的年轻人?
关注哪些维度?价格?品牌?场景?
用什么方法?观察?访谈?问卷?
产出什么?用户画像?策略建议?
😢 传统做法:会让用户用更清晰的问题来提问
✅ 我们的尝试:
澄清需求:多轮对话澄清需求
意图构建:从用户输入、团队历史、已有 Persona 中直接组装一个可执行的研究意图。
问题2:Context 很难管理
做一次研究会产生大量 Context:
社交媒体观察结果(几百条内容)
用户画像(Persona)
历史研究模板
中间推理过程
这些 Context:
有些是长期的(Persona 库)
有些是临时的(当前对话)
需要被过滤(噪音很多)
需要被关联(相似研究能被找到)
😢 传统做法:RAG 检索 → 问题;检索只是第一步,还需要持续整理
✅ 我们的尝试:把 Context 当作一个系统来管理:让对的资产在对的时间可用。
问题3:Agent 需要持续调整方向
做研究不是线性流程:
观察 → 发现矛盾信号 → 需要深度访谈
某个数据源无效 → 需要换方向
洞察已经清晰 → 应该停止探索
这需要一个 Agent 持续做判断,而不是按预设流程执行。
😢 传统做法:Multi-Agent 各司其职 → 问题:谁来做这个"持续判断"的角色?
✅ 我们的尝试:
分成两个 Agent:
Reasoning Agent:做判断和决策
Execute Agent:执行具体任务
Reasoning Agent 负责准备 Context、判断下一步、调整方向。
问题4:经验难以复用
每次研究都会积累经验:
某个领域的用户画像
某个平台的观察方法
某种问题的访谈框架
这些经验如果不沉淀,下次又要从头开始。
😢 传统做法:
文档或工具调用 → 问题:文档不够结构化,工具调用不够灵活
✅ 我们的尝试:
把经验代码化为 Skills ——可以被动态加载的能力模块。
过去产品积累
我们有一个产品 DAM,管理用户所有的内容,小到个人大到企业。这个内容管理工具是内容的唯一真相空间,存储图、文、视频、文件等非结构化数据,每一个文件背后都是已经人工和自动解析好的metadata。因此,天然成为了我们Agent的上下文管理系统。
Atypica 的工作流程

以一个典型的研究任务为例:
"想了解年轻人对咖啡的偏好"
1. Intent 构建
|从 Memory(团队关注视觉)、Assets(茶饮研究)组装意图
系统不会让你填表或多轮对话澄清。它直接从你的问题、团队历史、现有 Persona 库中构建一个可执行的研究意图:

2. Reasoning Agent 开始推理
|观察 → 访谈 → 报告 准备:加载 scoutTask Skill、准备社交媒体 MCP
推理 Agent 规划执行路径,准备 Context:
加载 scoutTaskChat skill(社交媒体观察)
准备 system prompt 和相关 tools
从 Persona 库检索相关用户画像
设置推理触发条件(5次观察后深度分析)
3. Execute Agent 执行
|按 scoutTask 方法观察小红书/抖音,收集 120+ 条内容。 发现:"说重视性价比,但为高颜值付费"
执行 Agent 根据准备好的 Context 工作:
Scout 在小红书/抖音观察用户讨论
收集 120+ 条内容,识别关键模式
触发 reasoningThinking 深度分析
发现洞察:"价格敏感 + 视觉导向,但为颜值付费"
4. Context 持续整理
|推理 Agent 根据执行结果调整策略:
矛盾信号?加载 interview skill,深度访谈验证
信息不足?调整 scout 观察维度
洞察清晰?加载 reportGen skill,生成报告
整个过程中,Context 不断被过滤、提炼、重组。

5. 资产沉淀
研究完成后,新资产进入 DAM 系统:
新 Persona 自动入库(Z世代咖啡消费者画像)
研究意图模板化(可复用于茶饮、奶茶研究)
Knowledge Gaps 记录(微博该人群讨论少)
下次类似研究,系统更聪明。
GEA架构

为实现上述工作流程,我们的架构逐渐形成了四个核心部分:

Reasoning 和 Execute 持续与 Context System 交互:获取记忆、访问数据、加载方法。
1. Intent Layer(意图层)
作用:把模糊输入变成可执行意图
具体做法:
解析用户输入
匹配团队历史(类似研究、相关 Persona)
生成结构化的研究意图
产出:一个包含研究对象、方法、产出的明确意图
2. Context System(上下文系统)
作用:管理各种 Context 资产
两个维度:
Build Time:长期资产(Persona 库、研究模板、Skills)
Runtime:会话 Context(对话历史、观察结果、推理记录)
核心能力:
语义索引(不只是关键词)
动态过滤(去噪)
关联推荐(找相关资产)
3. Reasoning Agent(推理引擎)
作用:持续推理和决策
具体工作:
规划执行路径
准备 Context(为 Execute Agent 准备 prompts、tools、skills)
判断何时调整方向
决定何时停止
不做什么:不直接执行任务(交给 Execute Agent)
4. Execute Agent + Skills
Execute Agent:
足够通用的执行器
完全依赖 Reasoning Agent 准备的 Context
动态加载 Skills
Skills(atypica 的具体 Skills):
scoutTaskChat:社交媒体观察
interviewChat:用户访谈
buildPersona:生成用户画像
reportGen:生成报告
Skills 渐进披露
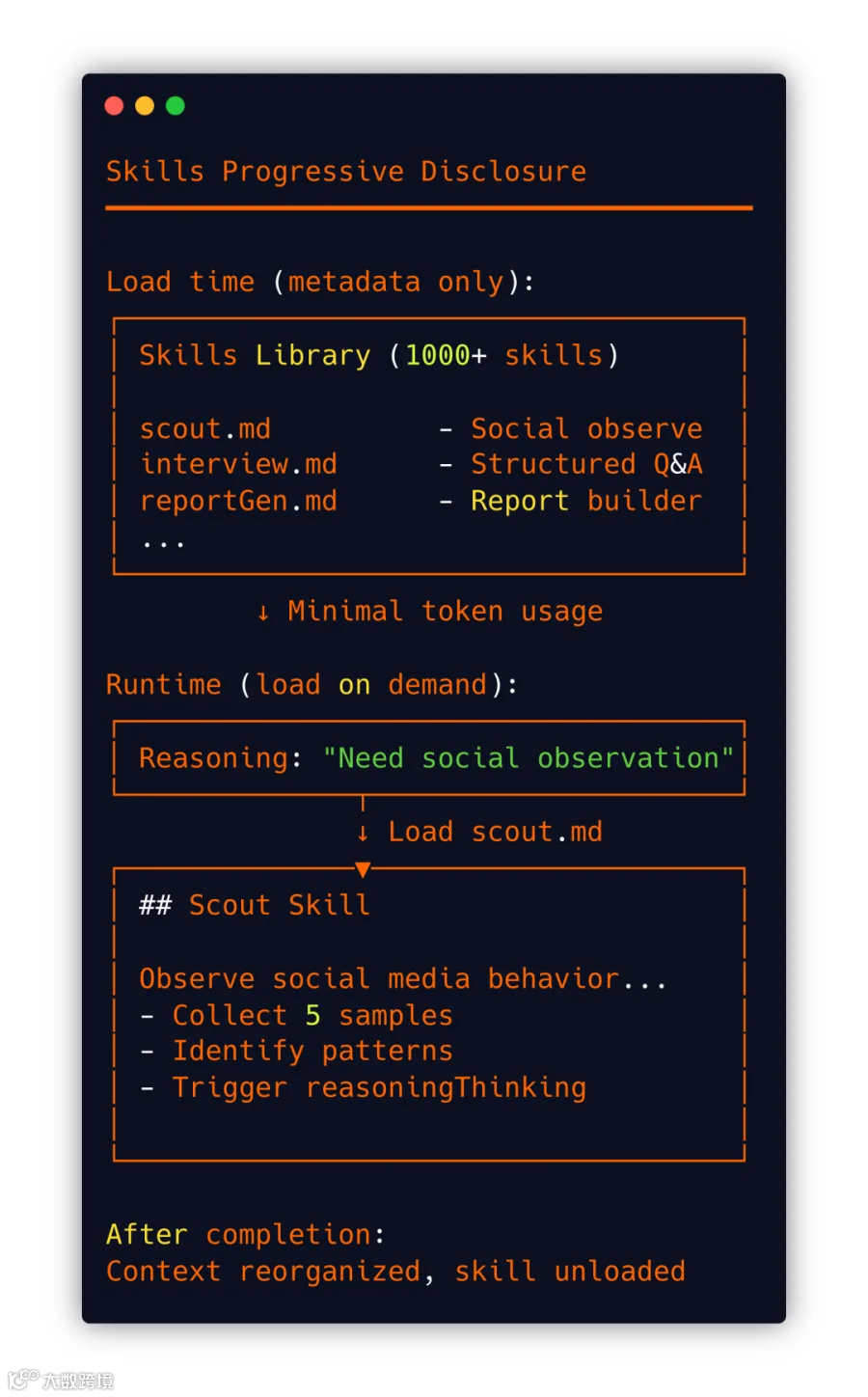
只在需要时加载完整内容,避免 Context 臃肿。
关于 Skills 概念的来源
"Universal Agent + Skills Library" 的理念来自 Anthropic 在 2025 年的思考——不是构建多个专用 Agent,而是一个通用 Agent 配合可组合的 Skills。我们认同这个方向。在 Atypica 的实践中,我们结合双 Agent 架构来使用 Skills,并在消费者研究场景做了具体应用。
和其他架构的差异

GEA 不是替代 RAG 或 Multi-Agent,而是在「探索性的知识工作」场景的一种实践。
1. Content 和 RAG 的差异:
GEA采用Context System,而没有只使用RAG。在RAG基础上增加了持续整理和资产管理——不只是检索,还要过滤噪音、建立关联、及时更新。因此Content System比RAG更动态。
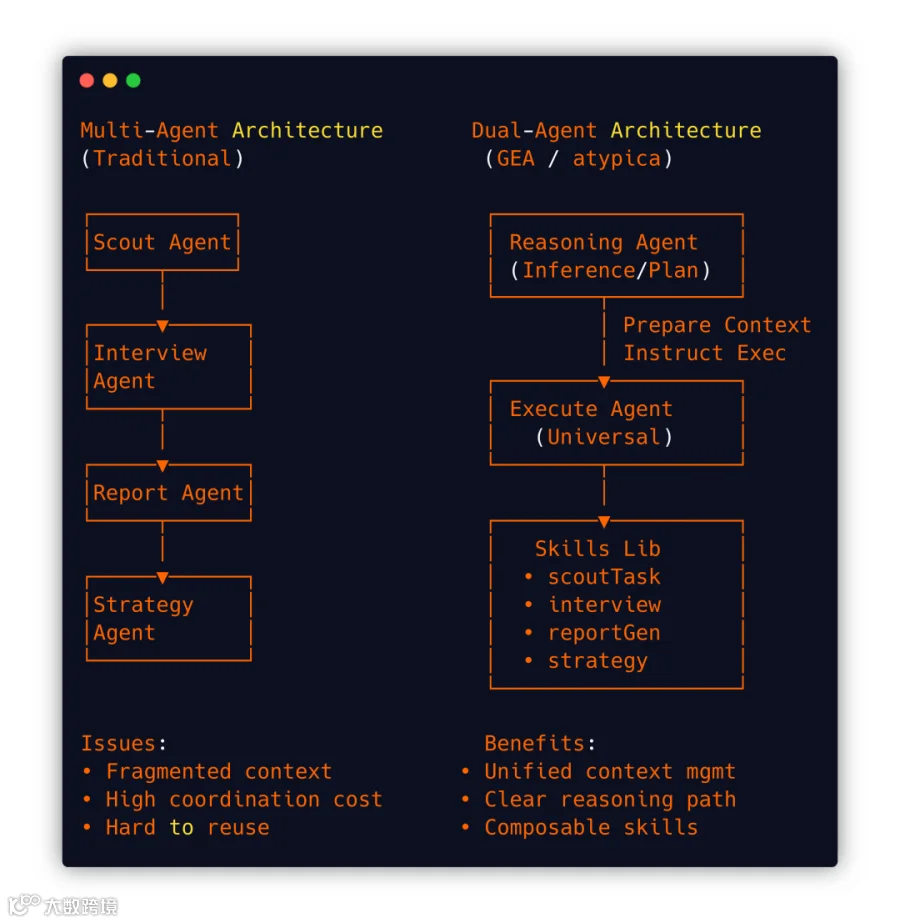
2. 双Agent 和 Multi-Agent 的差异:
GEA采用双Agent架构,即:Reasoning Agent和Execute Agent,而没有选择Multi-Agent。Multi-Agent也有多个能力单元(Skills),但用双 Agent 分离推理和执行,Skills 作为 Context 动态加载,不是固定的多个 Agent,而是可组合的能力模块。因此双Agent比Multi-Agent更有通用性。
双 Agent 架构对比
GEA 的适用边界

我们在用GEA的架构探索其他具有「探索性的知识工作」:
✓ 适合探索型知识工作
- 市场研究和用户洞察
- 产品定义和策略规划
- 内容策划和创意探索
- 技术方案评估和决策
特征:起点模糊、过程不确定、核心是判断
✗ 不适合确定性任务
- 重复性流程自动化
- 强约束的审批流程
- 实时性要求的操作
- 明确SOP的执行任务
特征:流程固定、要求确定、重在执行
GEA 是为"无法写成 SOP 的工作"设计的架构。如果你的工作可以写成明确流程,用传统工作流引擎可能更合适。
atypica.AI|懂消费者的智能体
用「语言模型」为「主观世界」建模