

作者 | Don
来源 | 至顶AI实验室
Ornith-1.0 是什么来头
Ornith-1.0 是AI研究团队 DeepReinforce 在2026年6月25日发布的开源代码模型家族,面向"agentic coding",也就是能自主规划、执行、修复代码的编程智能体场景。家族一共四个尺寸:9B稠密、31B稠密、35B混合专家(MoE)、397B MoE旗舰。9B、35B、397B基于阿里的Qwen 3.5后训练,31B则基于Google的Gemma 4。视频拍摄时31B还没在Hugging Face上公开,397B又太大,视频作者手头没有合适的机器跑,实际测试的只有9B稠密版和35B的MoE版本。
自我进化的模型训练思路
这个模型家族最特别的地方,是训练时用的"自我进化脚手架"思路。以往的编程智能体,通常由研究者手工设计一套固定"脚手架":工具调用、错误处理、任务拆解的整套流程,模型只负责往里面填答案。Ornith-1.0反过来,把脚手架也变成模型在强化学习中自己迭代的对象:先读任务和上一轮脚手架,提出改进版脚手架,再用它生成解决方案,两步反馈都会回流训练。用到的算法是GRPO(分组相对策略优化),最早由DeepSeek在2024年DeepSeekMath论文里提出:让模型针对同一任务一次生成一组答案,组内互相比较打分,省掉训练独立"评判模型"的开销,是近来国产开源模型圈常用的训练手段。
视频里还提到一个背景,多少能解释大家为何对开源模型格外上心:录制前不久,OpenAI发布新一代旗舰模型GPT-5.6,但受美国网络安全审查流程影响,目前只对约20家经审批的合作伙伴开放,普通用户完全无法通过ChatGPT或API访问。作者感慨前沿闭源模型的门槛正变得越来越高,这也让开源权重模型显得更有存在感。
本地测试设备
回到实测。作者用两台机器分别跑9B和35B。9B在一台笔记本上跑,显卡是移动版RTX 5090(24GB显存),Q8量化,通过LM Studio加载。这里值得提一句:笔记本版RTX 5090和桌面版并非同一块芯片,桌面版用完整的Blackwell GB202核心、32GB显存,笔记本版是阉割过的GB203核心、24GB显存,性能更接近桌面版RTX 5080,购买前容易踩坑。35B的MoE版本跑在一台配备RTX 6000 Pro(Blackwell架构专业卡)的机器上,通过vLLM以未量化全精度运行。这块工作站旗舰卡有96GB GDDR7显存,是RTX 5090的三倍,官方定价约8500美元。
多个实测开始
测试项目是作者频道的常规菜单:生成一个可交互的"浏览器桌面操作系统"、一个地铁3D场景并改造成带丧尸敌人的FPS游戏、一个带3D手表模型和电影感首屏的手表电商网站、按图复刻3D模型,以及一些即兴追加测试。作者还用了开源编程智能体Open Code(一个能在终端里调用本地模型自主写代码、跑命令、修错误的工具),把两个模型生成的半成品接进去,看它们能不能自己发现并修复bug。
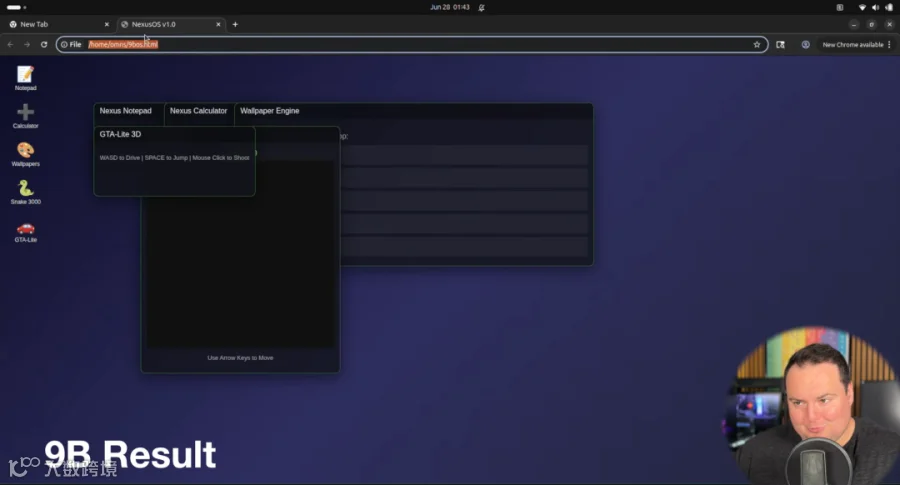
结果上,35B的MoE版本明显更让作者惊喜:生成的"浏览器桌面系统"里带了一个会互动的桌宠,能拖动、有待机动画,离开屏幕再回来还会有反应。
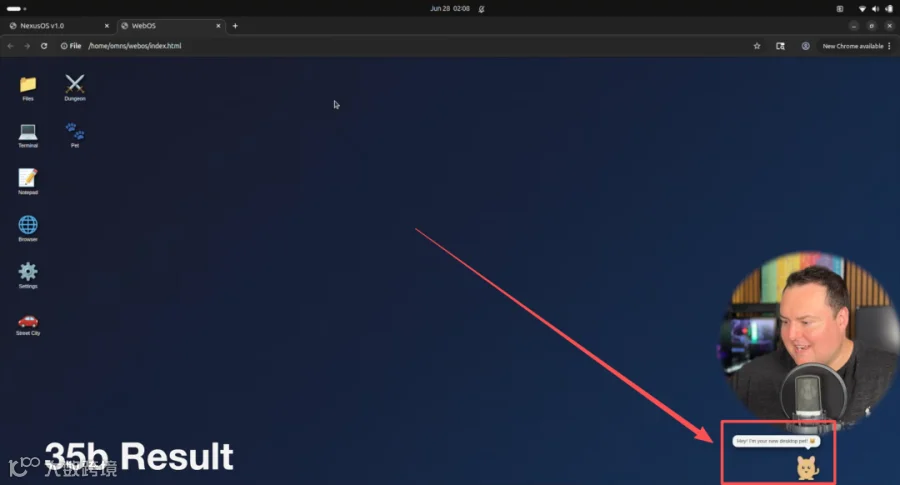
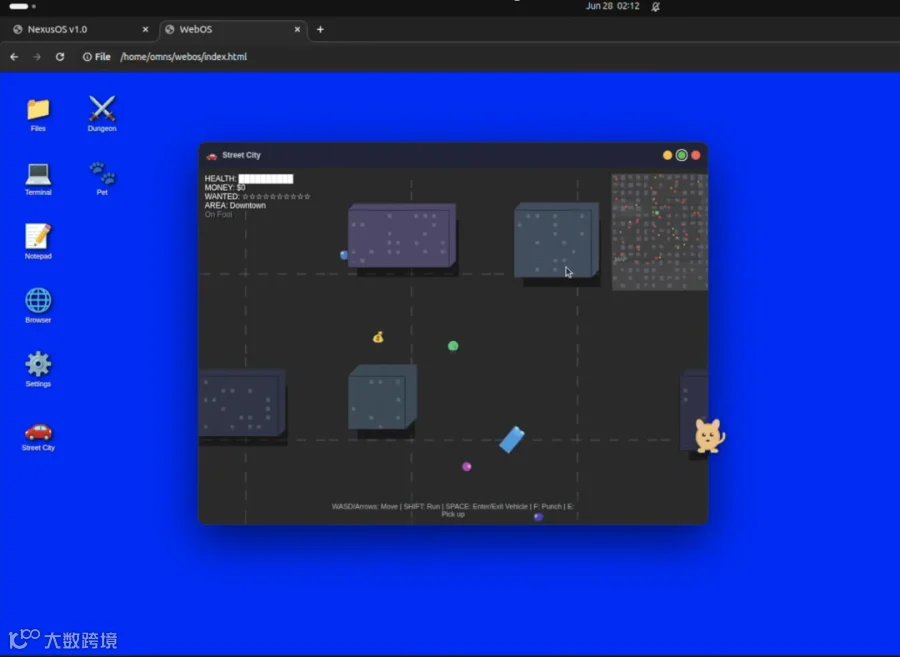
GTA风格小游戏虽非真3D,走路动画、车辆细节、打斗手感却比预期完整。
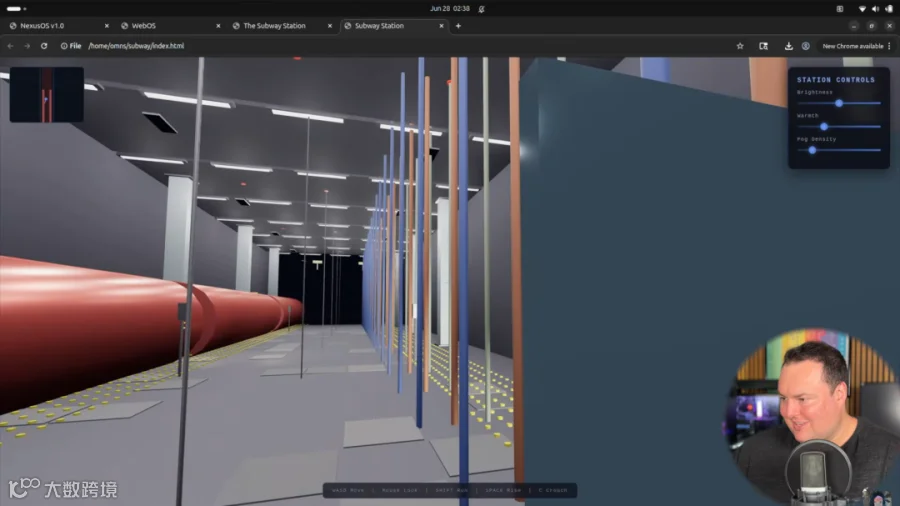
地铁FPS被指出无法造成伤害后,也顺利修复。
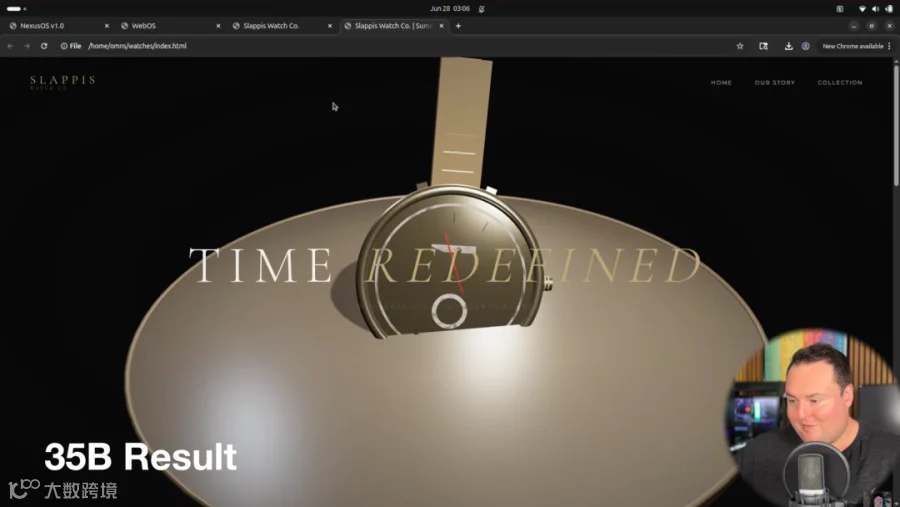
9B版本整体偏弱:浏览器系统初版卡在功能性问题上,交给Open Code修复时,作者盯着思维链发现反复出现犹豫措辞,怀疑进入了思维循环,最终没修好;手表网站的3D模型也一直没修成,倒是35B版本的手表官网首屏效果不错。
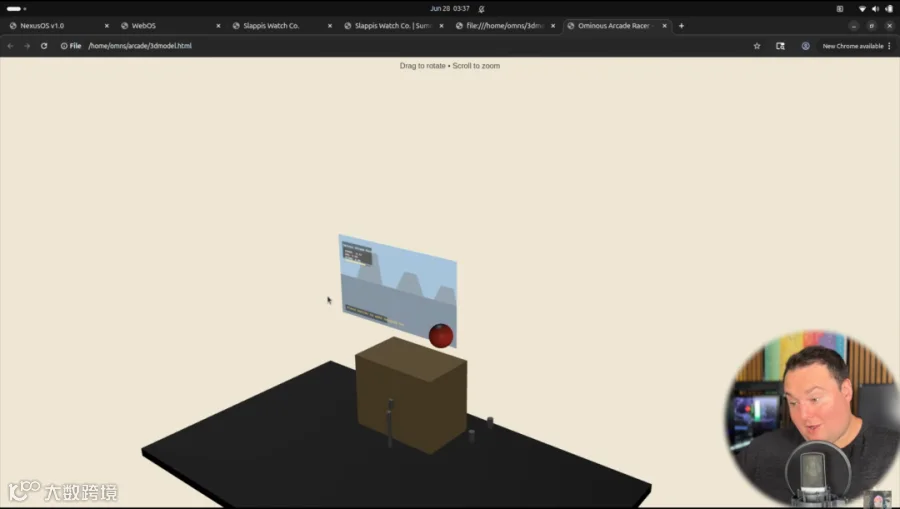
不过9B在按图建模测试里,初版失败后经Open Code重新处理,好歹找补回了颜色、摇杆等元素,说明它的视觉理解基础还在。
作者强调这只是"第一印象"式的轻量测试,而非严格基准评测:35B用的是全精度,本身比Q8量化的9B多一层硬件优势,也没有和各自的Qwen 3.5基座模型做逐项对比,谈不上"微调后一定更强"。
视频最后,作者最期待两件事:一是基于Gemma 4的31B版本公开后的表现;二是希望出一个基于Qwen 27B稠密模型的版本。在他看来,这个27B基座眼下仍是本地代码模型里最能打的选手之一。随着前沿闭源模型的门槛越来越高,这类开放权重、能在自己显卡上跑起来的模型,恐怕会有越来越多人开始认真对待。