

今日话题:Kimi K2 模型开源
7 月 11 日,月之暗面正式发布 Kimi K2 模型并同步开源。Kimi K2 采用 MoE 架构、 32B 激活参数在多项关键基准测试中取得开源模型 SOTA 成绩。
moonshotai.github.io/Kimi-K2
huggingface.co/moonshotai/Kimi-K2-Instruct
kimi.com
# 开发者自述:
6 位 Kimi 开发者@Justin Wong、@刘少伟、@Dylan、@Flood Sung、@镜子、@苏剑林 在知乎上分别从自己的工作内容出发,分享了关于 K2 在前端交互、架构效率、模型与 Agent 未来关系上的解读,进一步讨论 Kimi 在模型端到端 RL 这条路径上的探索和坚持。
@苏剑林 完整文章《 QK-Clip:让 Muon 在 Scaleup 之路上更进一步》可点击文末「阅读原文」查看。

@Justin Wong
Kimi K2 Technical Staff
7 月 13 日发布于知乎
前两天忙活了大半年的 Kimi K2 终于发布了,在上线前熬了个大通宵之后饱饱睡了两天,今天终于有闲写一点心得。
叠甲:以下内容全部是我个人观点,不代表公司立场。
再叠甲:以下内容全部是我古法手作 (仅使用 Github Copilot 当高级输入法用)。
✍️ 关于「写前端」
从 Claude 3.5 Sonnet 开始,AI 写前端到达了可以实用的程度,此后几乎所有新出的模型都会秀一下自己写前端的能力,Kimi K2 当然也不能免俗。
这里,我想 share 一下个人对此的思考。
一直以来各种文本 AI 都是默认输出 Markdown, 产品都是高级的 ChatBot,人们对一个 ChatBot 的期待无非就是能回答问题、写写文章、像人一样提供情绪价值。
有一次我在用户反馈中看到有用户要求 Kimi 「把文章重新排版,要放进一页 A4 纸」,这个在纯文本模式显然是无法实现的,我还把这个 case 当作一种产品经理与程序员的笑话一笑了之。
在大约今年 3 月的时候,Kimi Researcher 立项开发,当时无论是 Open AI 还是 Gemini 的 Deep Research 最终交付物都是一份纯文字的研究报告,我们就想能不能做得不一样一些,借助当时已经不错的前端编程能力,给用户最终输出一份更丰富多彩的交互式报告。这个 idea 的最终形态在 Kimi Researcher 上线之后已经和公众见面了,收获了不少好评。
但当我看到这个 idea 之后,脑中浮现了完全不一样的东西:没有人规定文本 AI 必须输出 markdown,如果「前端编程」成为 AI 默认的交互方式,产品形态会变成什么样?
也就是说,把人与 AI 的交互方式,从 chat-first 变成 artifact-first:你和 AI 交互的过程不是为了它直接输出一段内容,而是它理解用户的需求后立刻开启一个小工程,交付一个前端应用出来,用户可以继续追问、修改、迭代,但这些都围绕着一份交付物进行。
眼尖的朋友可能已经发现,这不就是个 cursor / aider / openhands 么?没错,从实现方式来说这就是 AI 编程干的事情,但如果在产品上精妙设计一下,把写代码的过程藏起来,对于不懂编程的用户,这就是「我和 AI 说句话,它竟然直接给我做了个 PPT / 画了个流程图 / 写了个小游戏」,这一次,AI 不仅能「把文章重新排版放进 A4 纸」里,还能给你变换颜色甚至加上动效,这是完全超越传统 ChatBot 的体验。
于是我趁着清明假期肝了一天,从 Aider 抄了 workflow 和 prompt 做了个 demo 出来,交互仍然是 ChatBot 的形式,但当用户问「介绍一下小米 Su7」时,普通的 chatbot 会给出一段文字简介, 我这个 demo 会直接输出一份图文并茂、可以交互的 PPT 一样的网页出来,用户还可以继续提要求修改,什么「背景改成黑色」,「再补充介绍一下 Su7 Ultra」之类的。
我拿着这个 demo 到产品部门 sell idea,大家都表示很有意思,但是活实在太多,下次一定,下次一定。现在 K2 已经发布,Kimi Researcher 也已上线,相信 kimi 产品也会很快有一些令人惊奇的变化。
记得 2009 年,我大二的那一年,有个师兄说:也许 20 年后的编译器,就是程序员说「我要一个 firefox」,然后编译器哼哧哼哧算了2天,拿出一个 firefox 来。
当时我们拿这个当笑话和幻想,现在看来,甚至不到 20 年。
✍️ 关于 Tool Use & Agent
年初 MCP 开始流行,当时我们就想能不能让 Kimi 也通过 MCP 接入各种第三方工具。当时我们在 K1.5 研发过程中通过 RLVR (Reinforcement Learning with Verifiable Rewards) 取得了相当不错的效果,就想着复刻这套方法,搞它一堆真实的 MCP Server 直接接进 RL 环境中联合训练。这条路很快撞墙:
首先是部署麻烦,例如 Blender MCP 对于已经有 blender 的用户很容易,但在 RL 环境中装上 blender 就是一个负担;
其次也是更致命的,不少第三方工具需要登录使用,你总不能为了训练 Notion MCP 使用而去注册一堆 Notion 账号吧?
但是我们换个思路,我的假设是:模型在预训练中已经知道工具该怎么用了,我们只需要把这个能力激发出来。这个假设的的基础很容易理解:预训练见过大量的代码数据,其中有大量的、用各种语言和表达方式的 API call,如果把每个 API call 都当成一种工具,那么模型早就该会用了。
另一个基础是,预训练模型本身就掌握了丰富的世界知识,比如你让他角色扮演一个 Linux Terminal,它完全能和你像模像样的交互一番,那么显然对于 terminal tool 调用应当只需要少量数据就可以激发出来。
因此我们设计了一个比较精巧的 workflow,让模型自己合成海量的 Tool Spec 和使用场景,通过 multiagent 的方式合成了非常 diverse 的工具调用类数据,果然效果不错。
对于 Agent,我的理解就是,如果一个模型能做到这样,它就是个不错的 Agentic Model:
task = get_user_input()history = [task, ]whileTrue:resp = model(history, toolset)history.append(resp)ifnot resp.tool_calls:breakfor tool_call in tool_calls:result = call_tool(tool_call)history.append(result)
当然这个流程还可以更高级一些,比如 toolset 可以让模型自己动态生成(参考 github.com/CharlesQ9/Alita)。
在训练的视角,这样的数据也并不难合成,只要想办法把一段长长的任务改写成探索、思考、工具调用、环境反馈、错误重试、输出内容等不同形式交织轨迹,就不难激发出这样的能力。
我认为现阶段我们对模型 Agent 能力的开发还在早期,有不少数据在预训练阶段是缺失的(比如那些难以言语描述的经验/体验),下一代预训练模型仍然大有可为。
✍️ 为什么开源
首先当然是想赚点名声,如果 K2 只是一个闭源服务,现在一定没有这么多关注和讨论,搞不好还会像 Grok4 一样明明做得很好却要承担不少苛责。
其次是可以借助很多社区的力量完善技术生态,在我们开源不到 24 小时就看到有社区做出 K2 的 MLX 实现、4bit 量化等等,这些凭我们这点人力真的做不出来。
但更重要的是:开源意味着更高的技术标准,会倒逼我们做出更好的模型,与 AGI 的目标更一致。
这一点不是很容易理解,不就是把 model weights 放出来吗,为什么会「倒逼模型进步」呢?其实答案很简单,开源了就意味着第一方再也不能用各种 hack 的方式粉饰效果,必须拿出足够通用、任何第三方拿到同样的 weights 都要能很简单地复现出你的效果才行。对于一个闭源的 ChatBot 服务,用户压根不知道背后是什么样的 workflow、有几个模型,我有听说过一些 rumor 说有大厂的入口背后是几十个模型、数百种场景分类和数不清的workflow,还美其名曰这是「MoE模型」。
在「应用优先」或者「用户体验优先」的价值观下,这种做法非常自然,而且是性价比远远优于单一模型的选择,但这显然不是 AGI 该有的样子,对于 Kimi 这样的创业公司来说,这种做法不但会让自己越来越平庸,极大阻碍技术进步,而且也不可能拼得过每个按钮都有个 PM 雕花的大厂们。
所以,当开源要求你不能走捷径的时候,反而更有利做出更好的模型和产品。(如果有人用 Kimi K2 做出了比 Kimi 更有意思的应用,我一定会去 PUA 产品部门的。)
✍️ 关于决心和一些可能引起争议的零散观点
去年 Kimi 大规模投流引起不少争议,乃至到现在还有很多 diss 的声音。
哈哈,我只是个小程序员,这个背后的决策逻辑咱也不知道,咱也不乱讲。
我只说一个客观的事情:在年初我们停止投流之后,国内不少应用商店搜索 kimi 甚至第一页都看不见,在苹果 App Store 搜 kimi 会推荐豆包,在某度搜 kimi 会推荐 「某度 DeepSeek-R1 满血版」。
即使在如此恶劣的互联网环境之下,Kimi 也没有恢复投流。
DeepSeek-R1 暴涨之后,很多人说 kimi 是不是不行了,你们是不是恨死 DeepSeek 了?恰恰相反,不少同事都认为 DeepSeek-R1 的爆火是个大好事,它证明了硬实力就是最好的推广,只要模型做得好,就会获得市场认可;他证明了那条我们相信的路不仅能走通,而且是一条康庄大道。
唯一的遗憾就是:这条路不是我们走通的。
在年初的反思会上,我提出了一些相当激进的建议,没想到植麟后续的行动比我想的还要激进,比如不再更新 K1 系列模型,集中资源搞基础算法和 K2(还有一些不能说的按下不表)。
前一段时间各种 Agent 产品很火,我看到不少声音说 Kimi 不应该卷大模型,应该去做 Agent 产品,我想说:绝大多数 Agent 产品,离了 Claude 以后,什么都不是。Windsurf 遭 Claude 断供的事情更加证明了这一点。
2025 年,智能的上限仍然完全由模型决定,作为一家以 AGI 为目标的公司,如果不去追求智能的上限,那我一天也不会多呆下去。
追求 AGI 是极其险峻的独木桥,容不得一丝分心和犹豫,你的追求也许不会成功,但犹豫一定会失败。2024 年 6 月智源大会上我听到开复老师脱口而出地说「我作为一个投资人我会关注 AI 应用的 ROI」,我就知道他创立的那家公司活不长了。
最后,我知道 Kimi K2 还有数不清的缺点,现在我比任何时候都更想要 K3。

@刘少伟
Kimi K2 Technical Staff
7 月 13 日发布于知乎
利益相关:参与过 Kimi-K2 的接生,自己的孩子怎么看都顺眼。
自从 Kimi K2 发布以来,很高兴得到了开源社区大量的关注。注意到尽管我们的模型结构近乎完全继承了 DeepSeek-V3(下文简称 DSv3),依然有很多小伙伴深入探究两个模型仅存的一点「不同」背后的原因。
作为 Moonshot Infra 侧推理小透明一名,今天想从推理角度来简单讲一下 Kimi K2 的 config 为什么「长成」现在的样子。
提前叠甲:内容涉及到很多训练相关的内容,里面会掺杂一些个人理解,如有不准确的地方请其他同事纠正。
✍️ K2 模型结构的设计宗旨
在启动 K2 训练之前,我们进行了大量模型结构相关的 scaling 实验,结果是,所有当时 propose 的、与 DSv3 不同的结构,没有一个能真正打败他的(顶多旗鼓相当)。因此,问题就变成了,我们要不要为了与 DeepSeek 不同,强行选择一个没有优势但不一样的结构,最终的答案是 no。原因也很简单:DSv3 的结构是经过验证,在 large scale 上依然有效的,而我们的「新结构」还并没有经历过足够大规模的验证。在已经有 muon 优化器和更大参数量两个巨大变量的前提下,我们并不想引入没有明确收益的额外变量来「标新立异」。于是,就有了第一个约束条件:完全继承 DSv3 的结构,调整适合我们的模型结构参数。
而第二个约束条件就是成本,包含训练成本和推理成本。原因很简单,作为一家小公司,我们的训练和推理资源都是非常有限的。在 DSv3 推出之后,我们经过认真评估,认为它的训练成本和推理成本,都比较接近我们当前能承受的上限。因此,我们需要将 K2 的训练和推理成本,尽量控制在与(我们自己训推)DSv3 持平的水平。
综上所述,模型结构的设计问题就变成了: 在给定 DSv3 结构的框架之下,如何选择合适的参数,使得模型在训练、推理成本与 DSv3 相当的前提下,获得明显更低的 loss。其中训练成本方面本文不会详细展开(才不会承认因为我也是一知半解),我们会在我们之后发布的 tech report 中介绍 K2 的训练方案与优化,敬请期待:)
✍️ 具体改动和动机
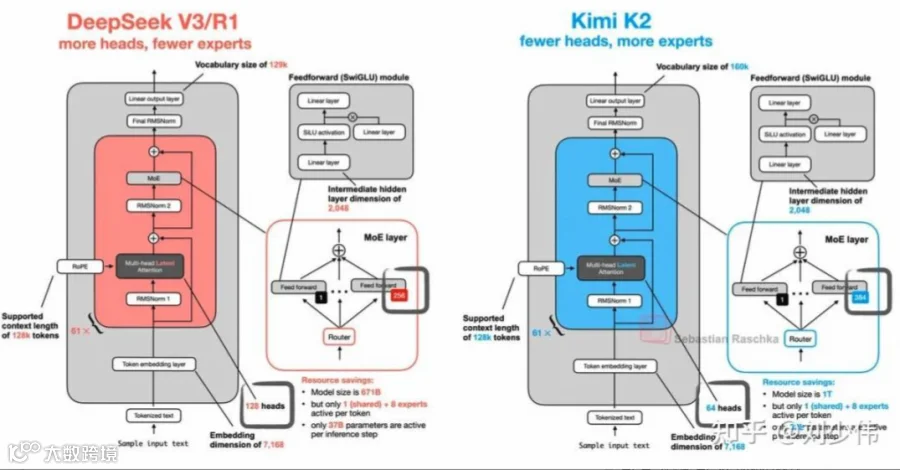
正如很多人对比两份 config 文件所观察到的,我们在模型结构参数上,具体的改动主要包含:
expert 数量
attention head 数
前面的 dense 层数只有 1 层
无分组的简化版 router
接下来我会按这个顺序,从模型推理的角度介绍它们背后的考量。本次推理方案完全沿用 DeepSeek 的 tech report [1] 和 OpenDay [2] 中提到的 EP+DP 方案,理论分析暂不含通信(假设通信可被推理层面尽可能overlap掉)。
2.1 num_experts = 384
这条结论来自 pretrain 团队的 sparsity scaling law,是 K2 项目从 pretrain 阶段开始的主要驱动力之一(另一个当然是 MuonClip)。简而言之,我们验证了在固定 # activate params 不变的前提下,单纯增长 MoE 总参数量,scaling law 依然成立,且不论训练 loss 还是验证 loss,结论始终保持,也就是无需担心增大总参数量会过拟合。因此,num_experts=384 承担了降低模型 loss 的核心任务。对推理的影响:
prefill 阶段:如果 prefill 节点数能做到和 num_experts=256 时一样大,且 prefill 的 seqlen 足够长,耗时基本无明显增长,因为此时的prefill是compute bound 的任务,我们的激活参数量不变,MoE 环节的总 FLOPS 也不变。
decode 阶段:由于需考虑线上实际的 TBOT 指标,我们无法无限增大推理时的 batch size(虽然现在已经被狂喷慢慢慢了orz)。因此可以粗略地认为 MoE 阶段的GEMM仍是 memory bound,那么 MoE 参数量增大到 1.5×,相关计算的耗时也就变成了 1.5×。以 EP=128 为例(128 是我们的 384 和 DSv3 的 256 的最大公约数,方便比较),对 DSv3 来说,每个 EP rank 上会存放 2 个路由专家和 1 个共享专家,大约 7.5 GB 的 MLP weights(不计算 EPLB方案 的冗余专家);而 K2 则需要大约 10 G,大了 2.5G。
2.2 num_attention_heads = 64MoE
阶段实打实地变慢(贵)了,我们就得考虑能否从其他环节找补回来,attention 的 head 数是第一个想到的切入点。原因在于 MLA 的论文中,DeepSeek 为了让 MLA 尽可能充分利用访存带宽,相比 MHA 常见 attention heads ≈ layer 数的设计,把 head 数翻倍,也确实带来轻微涨点,但也带来两个问题:prefill 和 decode 实际上都变贵了。
相比之下,如果我们将 attention head 数量重新变回 64:
prefill 阶段:
(1) MLA attention 计算量为 2hs²(d_nope + d_rope + dv),h 是 head 数,s 是序列长度,三个 d 分别为128,64,128。而整个模型其他部分基本都是矩阵乘法,计算量的公式为 2Ns,其中 N 是所有矩阵乘法相关参数的参数量。注意到,attention 计算量与 seqlen 成平方关系,而其余矩阵乘法则为线性关系,即随输入序列长度增大,attention 在 prefill 阶段耗时占比越大。而K2 的目标场景(agent、vibe coding)中,长序列是标准的使用形态,正好被这个问题直戳痛点。而将 head 数砍半,则可以一定程度上削减这个快速增长的平方项对整体耗时造成的影响。
(2) 除此之外,attention 前后还有 QKVO projection,这几个矩阵乘的参数量与 head 数线性相关。大家应该也能看到 DSv3 的激活参数 37 B,而 K2 只有 32 B,差的 5 B 就来自这里。粗略来看,DSv3 激活的 37 B 中,QKVO projection 占 10 B,K2 只有 5 B,随着参数量的减少,这几个 projection 在 prefill 阶段的 FLOPS 消耗也随之减少,K2 再胜一局。
decode 阶段:
attention core 的计算耗时主要取决于 KV cache 大小,这一点 K2 和 DSv3 完全相同,平手。但 QKVO projection 部分 与 prefill 阶段 类似,实打实地把 10 GB 的访存量降到了 5 GB。更关键的是,在 DP Attention 下,QKVO projection 会在所有 rank 上 replicate,因此这 5 GB 的差距不会像 TP 那样,随并行度增大而摊薄。因此不管 EP size 多大,每个 rank 都有 5GB 的仿存减少。回顾前面 MoE 的差距,EP128 下我们总参数量增大到 1TB,每个 rank 才多了 2.5 GB 访存,而这里 head 数从 128 降到 64,就能省下 5 GB,瞬间感觉自己很赚。
综上,降低 head 数可以瞬间把 MoE 参数增大亏掉的部分全部补回来,还有富余。我们最担心的只剩下这样对模型效果是否有明显的负影响。算法同学通过充分对比实验,确认了把 head 数还原到接近层数的「baseline」设置对 loss 的负影响要远远小于 MoE 参数增大的正影响,于是,num_heads=64 就这么愉快地决定了。(留一道思考题:减少 attention head 数,还可以为 Speculative Decoding 留下了更多提速空间)
2.3 first_k_dense = 1
与 DeepSeek 的观察类似,我们也同样在训练中发现第一层 MoE 的 router 很难做到负载均衡,但不同的是第二层之后并没有发现什么大问题。为了更充分利用 MoE 优势,我们只保留第一层 dense,其余全用 MoE。这个操作对 prefill 几乎无影响,对 decode 每个 rank 大约增加几百 MB 访存,可以忽略不计。
2.4 n_group = 1(expert 无分组)
expert 分组的最大价值是当一个 rank 上存在多个 expert 时,可以让它们同组,在 device(GPU) level 让 MoE 计算更均衡。但在当前模型的参数规模下,我们不得不使用很大的 EP,每个 device 上只剩少量、甚至只有一个 expert,group level 的均衡则从 GPU 层面转换到了节点层面。而即便节点层面能够做到相对均衡,但每个节点内部遇到所有 token 都被 route 到当前 group 的同一个 expert上这种最坏情况下,MoE 计算耗时仍然不会理想。
因此,EPLB 方案里面的动态重排和冗余专家对于当前设定下的负载均衡问题相对来说要更为关键一些。而更自由的 router 方案能让 expert 的组合空间显著增大,从而进一步提升模型能力。
✍️ 小结
以上就是 K2 模型结构参数被设定为当前这个状态,来自推理侧的完整思维链了。综合以上四个相比 DSv3 的改动,我们能够得到一个在相同 EP 数量下,虽然总参数增大到 1.5 倍,但除去通信部分,理论的 prefill 和 decode 耗时都更小的推理方案。即使考虑与通信 overlap 等复杂因素,这个方案也不会比 DSv3 有显著的成本增加。
可以自豪地说,虽然只有小小的 4 个参数的改动,但每一个决策的背后都有充足的理论分析和实验验证。也希望模型开源后,能有更多的推理厂商和框架共同帮我们验证前面分析的正确性。再次感谢所有小伙伴对 Kimi-K2 的关注!

@Dylan
Kimi K2 Technical Staff,post-train 相关
7 月 14 日编辑于知乎专栏「AI大模型训练:从0到1」
作为「接生群」里最后阶段的「接生婆」,感受到这版模型按捺不住的强大,也不得不感叹前面几个月里同事们的「高质量数据培育」、「精准调优」。
看到有好些同事写了很棒的回答,也想简单聊聊自己浅薄的一些理解和感受。
✍️ Data Efficiency First
I think a lot of the researchers looked at reasoning and RL but it was not really about scaling test time compute. It was more about data efficiency. —— Noam Brown
为什么一定要做 RL ? 我觉得 Noam 说得非常好,算力终究是无穷的,但数据是有限的,scaling test time compute 背后的原因是因为 RL 算法能够有更高的 data efficiency.
比如在 Kimi1.5, R1 出来之后 1-2 个月,我们发现有非常多小模型,甚至 7B 的模型在海量数据的 SFT 训练下,也能在某个 domain 比如 AIME 上达到和这些 RL 之后的大模型一样的效果,而且你可以在任何 domain 复现这样的「蒸馏」现象。
那这两者的区别是什么呢?
实际上不难发现,对于 Kimi1.5, R1 这样的「大」模型,它可能用几千、几万条的数据通过 RL 训练,在相对比较小的 gradient update steps 能达到 SOTA 水平,同时保持比较好的泛化性,但是小模型在某一个 domain 达到同样的效果就需要可能百倍的数据量。比如 NVIDIA 的 OpenMathReasoning 用了 3.2M 数学蒸馏数据在 Qwen-7B 上就能获得一个数学接近 SOTA 的模型。
那这个故事告诉我们,那就堆数据不就好了吗?「frontier model 负责冲刺 SOTA,小模型负责蒸馏复现 SOTA」。
但细想会发现,做数学题有一些特别之处,它是相对封闭、完备的领域,并且因为问题结构相对规整、易于明确标注答案,从而能更轻易地收集和利用,题量相对比较多。比如 stack exchange 上数学相关的提问有 170 w,基本上等于 physics(24.5w), english language(13.3w), machine learning(21.9w) 等等领域之和。数学之外,大部分领域并不能很容易地收集到这么海量的数据,尤其是一些可能没有办法很清晰地定义和分类的开放型提问。从这个角度思考来看,提高 data efficiency 就非常重要了。
为了提高 data efficiency, 我们肯定需要 RL 这样的手段, 为了能够做得动 RL, 模型的激活参数一定不能特别大,否则推理速度会非常慢。
为什么一定要「大」模型?
我觉得这同样是为了 data efficiency 考虑。很容易发现一个现象,模型总参数越大,pre-train 阶段 scaling law 验证下来 loss 越低;post-train 阶段也可以发现同样的数据量下,大的模型在测试集上的表现总是比小的模型要表现好。
但多大算好呢?肯定不能无限大,一方面是成本考虑,另外一方面是总有一个模型大小的 data efficiency 收敛点,到这个点附近之后继续 scale 收益性价比会变低。(实验细节可以期待一下 tech report)
为什么要用 Muon 优化器?
同时也是为了 data efficiency, 参考 moonlight paper 里面的实验,可以发现 Muon 相比 Adam 来讲,最大的卖点就是相同的 tokens 下,Muon 的 loss 显著更低。这也是为什么我们一定要把 Muon 的 scaling 做 work 的原因。
所以综合这三个方面,我们需要的就是一个激活参数小、总参比较大的模型,再加上更好的优化器,才能够在 pre-train 和 RL 阶段把 data efficiency 做到极致。
最后展望一下,我觉得这并不是全部。
如果和人类对比,K2, R1 这样的模型数据吸收效率还是太低。哪怕是今天,一个受过良好教育的人类在学习一个全新任务的数据效率还是远高于最强的模型,因为人类的探索拿到的反馈远不止是「对」或「错」的标量,而是细粒度地「哪里错了」、「下次如何改进」的这些细粒度反馈。这些反馈会被海马体迅速「写入」并整合,实时刷新我们的大脑模型,从而实现高效地迭代。
✍️ Model = Agent
呼应这次发布 kimi app 上的标题「模型即 agent」,去年 o1 刚发布的时候,我恰好发了一篇知乎叫做 《o1 is an end-to-end agent》 当时写这个知乎的时候,还完全不知道 o1 是怎么做的,只有一点蛛丝马迹,但我们非常相信那就是我们想要的提升模型智能的方式。回顾来看,非常庆幸的是当时最后两点的预测可能恰好被 R1 和 K2 给分别实现了。
1. 技术民主化:开源社区的平替版本会让更多、更 general 的方向涌现出来;
2. 更复杂的 agent 能力,比如加入 tool use(可能会很快在 coding 上体验的升级);
当然,不是批判各种 workflow,毕竟「壳有壳的价值」,深入场景、理解用户也很重要,只是想表达模型的端到端优化会有很高的潜力。
✍️ Infra–Algo Co-Design
和 Deepseek v3 / R1 类似,K2 也是 infra-algo co-design 的产物。
首先,我们采纳了 Deepseek 提出的 MLA, 一个公认的高效 attention 结构,也是大模型领域最经典的 infra-algo co-design 工作之一。MLA 成功的关键点就是源自来自对当前算法和系统的综合考量,使得模型可以根据训练和推理的不同特性(Compute-Bound or Memory-Bound)选择最佳的形式,尽可能地达到效率最大化。
K2 的 pre-train 也存在很多 infra-algo co-design, 在这里两位大佬的回答中可以略窥一二(@刘少伟 的回答),更多细节可以期待一下 tech report。
RL 里面也有很多 co-design 的工作。首先是内部的 RL 训练框架和算法的配合,从 Kimi1.5 到现在,经过多位 infra 大佬的精心打磨,哪怕是在 K2 这个 1T model 上, 基本上实验迭代效率也是「天」这个时间量级。另外,再比如从 Kimi1.5 到 Kimi researcher 我们一直在提的 partial buffer, 是 agent RL 必不可少的 feature。
随着 agent 交互轮次越来越多,任务越来越复杂,现有的训练框架依然有非常多不好的地方需要去优化,但想要做好这些优化并不能单纯来自算法的拍脑袋 idea 或者 infra 同事极致的优化能力,我觉得依然是需要持续 co-design。
那怎么做 co-design 呢?
个人认为 co-design 的第一层是 infra、algo 双修的高人,既能优化 kernel、又能设计模型,但能做好的人寥寥无几。co-design 的第二层是建立良好地团队合作方式,充分沟通,这个路径可能更有普适意义。作为一个 infra、algo 都不太通的渣渣,每天最好的进步方式就是拉着 infra 的大佬吃饭、锻炼,拉着 algo 的大佬喝咖啡、摸鱼(学习)。充分沟通下就会有很多灵感和想做的事情,也非常容易就推动下去,可能这也是小团队在这个时代为数不多的优势之一。
最后,我觉得公司里面「接生群」的名字起地非常好,K2 实际上就是一个刚出生的 baby,虽然略显「灵性」,但和很多已久的 frontier model 相比,还是有很多、很明显的缺点。作为 post-train 相关的同学,还是略感惭愧,希望后面的版本迭代里面能够持续释放 K2 base model 的潜力。

@Flood Sung
月之暗面 · RL Lead
7 月 13 日发布于知乎
对于 Kimi K2,最值得关注的信息除了 MuonClip 带来的漂亮得起飞的 loss 曲线,当然是 Agent 能力啦!毕竟我们的 blog 标题可是《 Kimi K2:Open Agentic Intelligence 》 简称 OpenAI from:

那为什么我们选择提升 Agent 能力呢?答案会比较简单而直接:我们一开始就想做 Agent!
懂 RL 的一定都懂,Agent 这个概念本来就来自 RL。Agent 就是脑子 (大模型)带了手和脚(Action)可以和现实世界交互的实例。
所以,如果你完全用 RL 的思维去思考 Agent,那么就会很自然得出这样的结论: Model 就是 Agent!Agent 就是 Model!而 AGI 要实现,模型一定要以 Agent 形态存在,从而可以和现实世界交互,完成需要的任务。
在一年多前的内部年会上,我们曾畅想未来的 AI 可以完全控制电脑自己干活,然后想象深夜的办公楼里一片漆黑但是闪着一个个荧幕的亮光,Agent 正在嗷嗷干活的情景!没想到这么快,Agent 能力已经突飞猛进,设想一定程度上已经到来,并在不断加速进化!
回到技术实现上,为了实现更好的通用 Agent 能力,本质就是 tool use 的能力,我们构建了一个大规模的 agent 合成数据 pipeline:
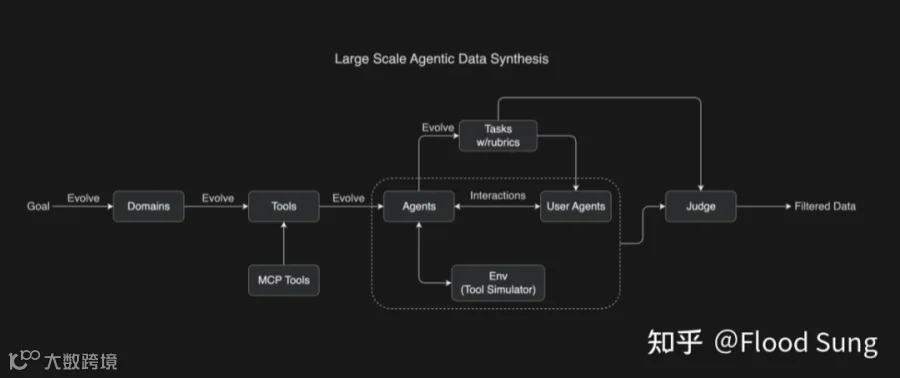
简单的说这是一个完全自动化的 agent 数据生产工厂!通过全流程的模拟来过滤出好的 Agent 轨迹数据。
这个生产线非常符合老子的思想:一生二,二生三,三生万物。
我们先让模型生成几百个场景比如外卖,微博,微信…,然后基于场景生成几千个 tools,比如点个外卖,发送微博,查找联系人,然后基于不同的 tool 组合生成几百上千个不同的 Agent (不同的 sytem prompt +不同的 tool set)接下来我们针对每一个不同的 agent 生成从简单到复杂的具有得分点的任务。然后我们开始进入大规模的 Agent 模拟了:
先把任务分配给一个模拟的用户,让用户根据任务和对应 agent 多轮交互,用户也是生成出来的有不同的个性和语言风格。
接下来 agent 调用的工具也通过 tool 模拟器其实等价于 world model 来执行,并反馈给 agent 继续处理。
执行完整个任务后,我们再用裁判根据得分点来评估 agent 交互轨迹是否符合要求,好的数据就是存起来!
想象一个深夜,OK 没有屏幕不需要屏幕,但有几千个 agent 在虚拟世界里疯狂交互,是不是有点科幻? 这让我联想到了《黑镜:Hang the DJ 》那一集两个虚拟人模拟恋爱上千次来判断是否匹配。
Fantastic!这是 self-improvement 的雏形!当然这里面肯定存在模拟失真的问题,还可以不断的改进。我们在一些场景也会用真实的环境来做,同时我们也收集了几千真实的 mcp tool 来提升数据的真实性,这些都进一步加强了我们模型的 agent 能力。
那么接下来呢?当然是 large scale agent rl!相信大家会非常期待的。

@镜子
Kimi K2 Technical Staff
7 月 14 日发布于知乎
利益相关,但以下内容只代表个人观点
今年为 K2 和 Kimi researcher 的幻觉抑制这一块做了很多工作,不过 LLM 的幻觉这件事吧,目前确实学术上都还有很多没有研究清楚的地方,体感上也还做不到 0 幻觉,因此很遗憾可能还算不上一个值得关注的贡献_(:з」∠)。
benchmark 分数啥的就不自己拿出来提了,说说自己觉得优化比较明显的场景吧。
带搜索场景的 faithfulness。
让模型生成回答时,如果触发了搜索,尽可能各种事实依据都来自于搜索得到的信息,减少模型利用自身知识进行直接回答的比例,从而起到抑制幻觉的效果。
因为搜索算是可以比较清晰定义出来的一个场景,让模型少自己编东西,尊重搜到的内容,老老实实当个海量信息的归纳过滤员,而不是凭记忆拍脑袋回答你。
这个能力对于快思考模型,推理模型,深度研究,都是受益的。
这一块目前有不错的提升,但是也还不够好,比如模型在搜一个人名时搜到了多个重名的人(尤其是中国人名字用拼音表示时,在互联网上重名更加严重),如何分辨哪一个是用户想找的那个 ta,哪些信源的信息是冲突的(比如某百科上的数据经常就是错的),如何交叉验证等等,这些细节都还来不及打磨到极致,也不是非推理模型的强项,Kimi researcher 在这部分上会做的好很多,后续推理模型和 agent rl 中我们肯定还会加大力度去搞。
我想要实现的 Kimi,是能像人一样,被老板丢了一个莫名其妙的名字,就用尽各种手段全互联网去把那个人找出来。
但是不论怎样,至少我们迈出了第一步,至少先保证模型能就事论事地用搜到的内容回答你。模型的幻觉其实有很多种,我们先抑制一些可以清楚定义的幻觉。
年初 deepseek r1 带来惊艳的同时,我们也深深感受到模型幻觉对生产场景的危害,像一朵乌云悬在头顶,你不知道它什么时候会下雨。
中国大模型的天空也许乌云还有很多,但总有更多人去努力拨开乌云,仰望星星。
与各位共勉。

@苏剑林
月之暗面 · 资深研究员
7 月 14 日发布于知乎
四个月前,我们发布了 Moonlight ,在 16 B 的 MoE 模型上验证了 Muon 优化器的有效性。在 Moonlight 中,我们确认了给 Muon 添加 Weight Decay 的必要性,同时提出了通过 Update RMS 对齐来迁移 Adam 超参的技巧,这使得 Muon 可以快速应用于 LLM 的训练。然而,当我们尝试将 Muon 进一步拓展到千亿参数以上的模型时,遇到了新的「拦路虎」——MaxLogit 爆炸。
为了解决这个问题,我们提出了一种简单但极其有效的新方法,我们称之为「QK-Clip」。该方法从一个非常本质的角度去看待和解决 MaxLogit 现象,并且无损模型效果,这成为我们最新发布的万亿参数模型「Kimi K2」的关键训练技术之一。
……
篇幅所限,完整文章请点击文末「阅读原文」查看

More
马斯克 Grok4 有哪些亮点?如何看待「不懂计算机科学的人用好 AI 编程是妄想」丨知乎 AI 周榜