

阶跃星辰最新大模型命名为「Step 3.5 Flash」,将「速度」直接写进了名字里。
此前阶跃星辰联合创始人朱亦博@Yibo Zhu 已经分享了基模迭代中的几个关键节点:朱亦博复盘阶跃星辰的「快哲学」:用户已经没耐心看模型「蹦字」了。
这次几位研发人—— @hzwer 黄哲威、@Yasmine、@P2oileen、@Melody,将从后训练等技术原理上,进一步解释这种「快」:

@hzwer 黄哲威
阶跃星辰
https://github.com/stepfun-ai/Step-3.5-Flash/tree/main
我又来写 Step 3.5 Flash 小作文
在阶跃做大模型 1000 天
Step 3.5 Flash 的技术报告交上 arXiv 了。看着五十多页 pdf,感觉像是在漫长的荒原徒步后终于看到了存档点的篝火,解锁篝火,一旁刻着 Step 3.5 Flash 的小小石碑轮廓渐明。
想起 23 年初开荒时代的日子,那时候人不少但没卡,都是做视觉转行的同事,不知道要怎么做,对着 Llama 调一点 LoRA 参数,看它能蹦出几句成句的中文,就觉得见到了神迹。后来把评测和基建一点点做起来,踩了不少坑,比如检查训练集里的评测泄露,初步洗数据让模型不出乱码,初建提示词工程。
三个月训出了能用的 130B Step1v,当时觉得总算是摸到新时代的大门了。
但是后来我们走进了死胡同,直到新范式的星光闪现,才看清路标走回头。想起一句话:成功总是朴实的,但失败有千奇百怪的原因。
Step2 的时候,我们迷信「大力出奇迹」,选了一个激活很大的 MoE 模型,想着靠大参数量 + 超轻微调的路子。结果搞了半年,虽然感觉创作能力、情商还不错,但是 RL 做不太动,靠轻量微调没法显著拔高推理能力。而且 all in 训一把就成功显然太低估工程复杂性了
24 年我做还做了不少 RLHF/DPO,总体感觉并没有让模型发生质变,构建的数据总是只让模型学到点皮毛。虽然做 RFT 多轮微调时发现模型思考模式有时非常有趣,但是没有深入下去走到 R1 相近的范式上;当时我周围同事什么过程奖励 prm,树搜索 MCTS,思考模式合成都做过,但是收效却不明显。我试过用收集语料的思路去搞形式各异的 SFT,却对模型的思考模式认知很浅。
25 年我们在 o1/R1 超长链思考的范式下重塑了很多认知,团队也一起调整了研究和组织方式,这一版大家还是自我感觉做的不错的。25 年初 R1 明显改变了我的职业生涯,上一次是 chatGPT。
为什么要做一个 Flash 模型?怎么做?
祛魅了超大参数量,我们这次想把赌注押在精巧小模上。
1. 创业公司禀赋适合做小模型,没有那么多算力可以烧。据说 xAI 有 80 万 H 卡,比国内所有小公司加起来还多。我们很多研究员的认知是在 qwen8B/32B 上实验获得,很难一下迁移到做几百 B 激活的模型,起码得有个靠谱实验机。
确实这几个月感觉一个强的基模和好的基准下,实验迭代,模型合版的流程问题会少很多,因为组里每个研究员都能复现主线实验关键步骤。
吸取 Step 2 教训,我们知道如果做不好后训练,更大的模型并不带来更好的推理能力。而随着自蒸馏和强化学习的演进,后训练能赋予小模型远超预期的生命力。
(安利一下,Step3-VL-10B 点也很高:GitHub - stepfun-ai/Step3-VL-10B: https://github.com/stepfun-ai/Step3-VL-10B)
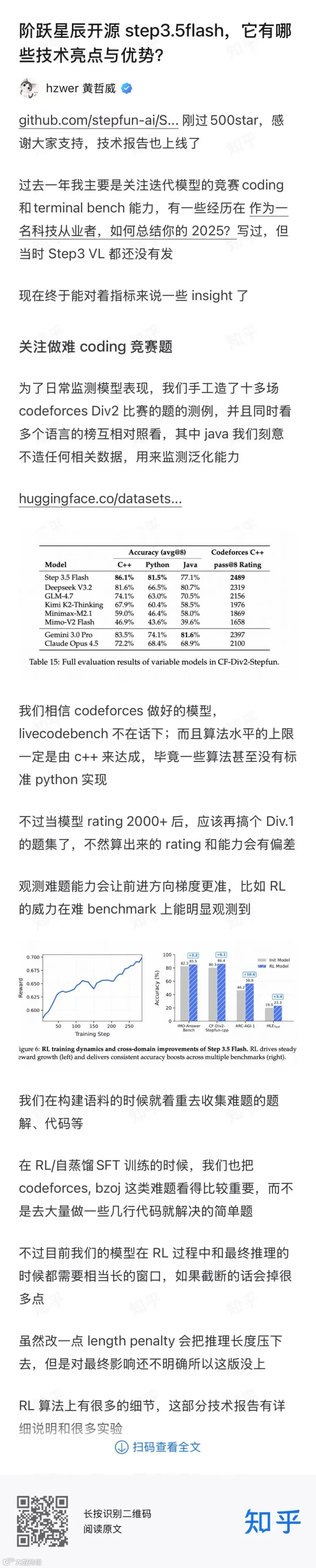
在定版前几周,我还想不到 Step 3.5 Flash 最后在各个推理基准上能做到这么高的性能,比如 AIME 97-98,LiveCodeBench 85+:
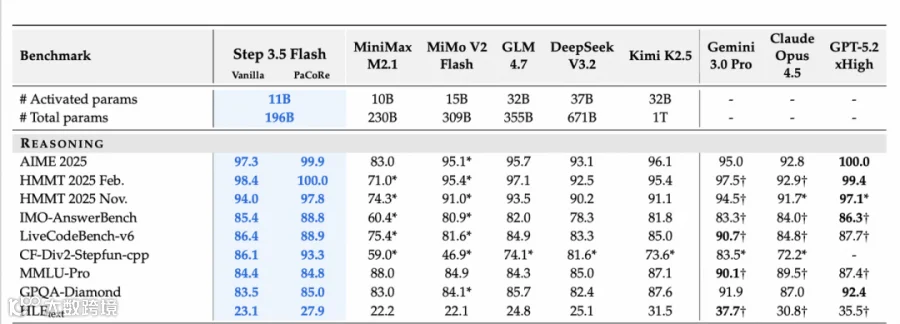
尤其 Codeforces 能力让我特别振奋,训练了多年编程比赛(23 年中还打过一些),现在我水平已经不及 Step 3.5 Flash 小模型了。
两年前期待亲手训练出一个算法水平超过自己的模型,现在有了回响。
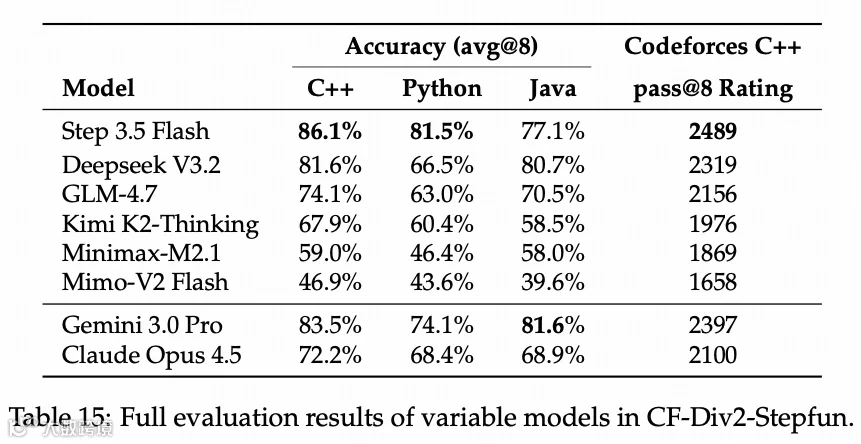
模型上线后我也试了最近两场 Codeforces Div2 和 Div3 比赛,每场只有一题错。
AIME26 新题前 15 题 math arena 也给我们测了,96.67%,只有最后一题 2/4,其它全对。
记得 Kaiming 说过未来是真正测试集,Step 3.5 Flash 是真有泛化的。
长上下文时代需要更强的推理速度
24 年的时候,chatbot 用户经常会抱怨思维链不好读。而现在很大一部分用户是 agent 需求,他们关心的是最终交付结果而不看思考过程。因此我们想极致压榨推理速度,主要靠 @Yibo Zhu 大佬一直说的模型-系统协同设计:
结构上我们选了超稀疏的 MoE,把激活参数量压到了 2.78% (8/288)而且 Step 3.5 Flash 很复古地选择了 GQA-8 (分组查询注意力) + SWA (滑动窗口注意力),主要是考虑到对投机采样和部署硬件的友好。
一点解释:主流的 AI 推理服务器(如 DGX、HGX)通常是 8 卡一组。将 GQA Group 设置为 8,意味着在进行并行计算时,KV Cache 的分发和计算可以完美地在 8 颗 GPU 核心或 8 个张量并行切片上实现负载均衡。 在全量 Attention 下,随着上下文变长,KV Cache 会线性膨胀,推理速度会越来越慢。而 SWA 将注意力锁定在一个固定窗口内,让显存占用和计算密度变得「可预测」。 投机采样最怕的是验证环节太重。如果每一轮投机都要计算几十万长度的全量注意力,那加速效果会被抵消。SWA 提供了一个轻量级的验证环境,让 MTP-3 抛出的多个候选 Token 能够以极低的延迟过审。
综合考虑性能和速度,Step 3.5 Flash 选择了 3 层滑动窗口注意力层 和 1 层全注意力层 交替。S3F1 不是正确率最优解,但是超高性价比
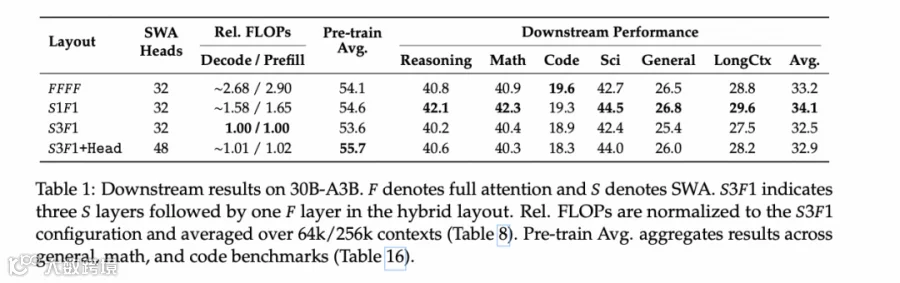
最后的效果是,推理速度平均 100+ tps,根本看不过来;在 128K 序列下推理成本也压低到其他类似尺寸模型的 1/4 到 1/8 左右。
相信社区的力量
如果有新的技术,在小模型上尝试甚至重新训练的代价都会比较小,我们相信之后的 3.6 / 3.7 版本,每一次都会有可观的进步。
另一方面,更小的模型有更低的部署/训练成本,甚至这两天看到在 128GB Mac 上把 4bit Step 3.5 Flash 256K 跑起来的。消费级单显卡能部署的前沿智商的模型,我相信社区一定有很多大佬能进一步给它附魔。
小但是强的 Flash 模型
1、猛拉 agent 能力
24 年初我在做模型调用工具来解题(比如 python),但当时模型指令遵循不够强,而且公司投入更多在 chatbot 上,这一支就搁置很久。
如今,我们希望 AI 成为工作伙伴,生活助手,首要就是要发展 agent 技能树。我们目标是 agent 能力能完全对标 glm 4.7,在复杂工具调用和长程操作的任务上能有很强的能力。
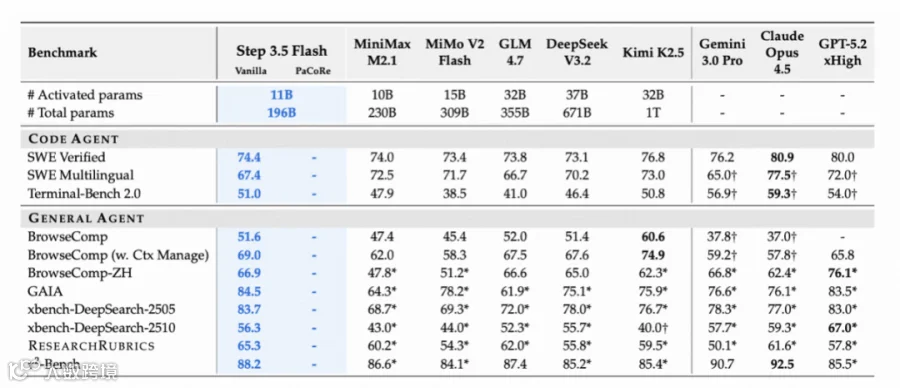
通过细致地做 agent 相关任务的训练和基建,以及为长程任务优化的 MIS-PO RL 算法,工具调用(τ2-Bench 88.2%)、深度搜索(BrowseComp 51.6%)都达到了一个比较不错的结果
这里很有意思的是,当模型推理长链推理能力训练好以后,会自然泛化到多轮工具调用任务上,从而可以通过强化学习和自蒸馏继续强化。
2. 强化学习真有魔法
我以前经常想,一个智障模型,怎么能通过几千个题 RL 就发生质变呢?特别是大模型开荒时代的 RLHF 让人更迷惑,训练一个奖励模型本身就很难,而且听起来先训判别器再训生成器提升很间接,耦合的问题特别多。
现在看来预训练模型表现智障但不真智障,只是沉睡的能力需要唤醒。24 年大家就一直说要靠后训练激发智力,但是却没完全搞清楚怎么激发,长链思考 / 可验证的奖励 / 广泛干净的数据 / 稳定的算法,这几个条件同时具备以后 RL 才真正显示出威力。
o1 以后大家就共识思考模式重要,但是不共识好的思考模式怎么来,所以有很多人在研究过程监督,或者手工合成的方法。做到最后发现 模型思考模式自由发展 非常重要,人工设计作为辅助启动可以,但不应该是主力。模型的思考模式不那么容易解读,人只能设计一个大概。
25 年再次深入研究强化学习,我们组里经过很长时间的尝试和迭代,先是做好了 R1 from zero 的开源复现工作 Open-Reasoner-Zero,然后又进一步做了一些新的设计。
MIS-PO 抛弃了传统的连续重要性采样权重,就是 PPO 里面那个用来校正新旧策略差异的样本权重项
因为训练推理不一致,off-policy 更新等内在原因,按 PPO 原始想法计算的新旧策略差异非常不稳
我们最终改用离散的分布过滤:
Token 级过滤: 抑制训练策略与推理策略之间的局部失配
轨迹级过滤: 剔除那些显著偏离目标分布的整条轨迹
这是我们 RL 跑好的关键设置,不知道别人试用怎么样
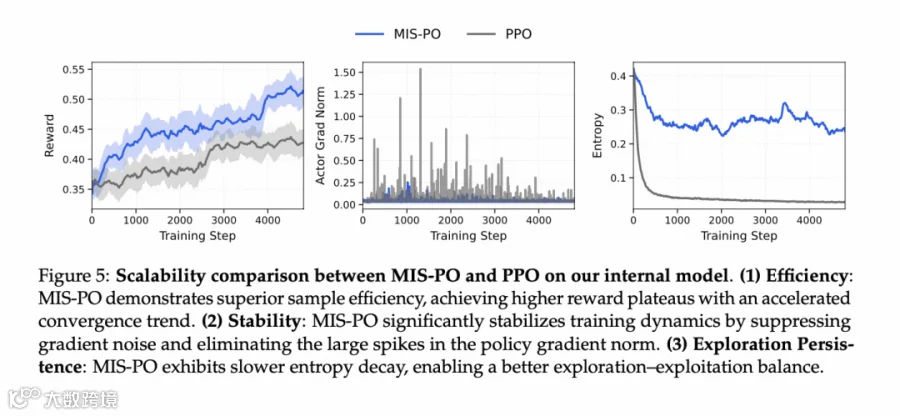
MIS-PO 算法相比于 PPO 在模型训练中具有更高的效率(收敛更快且奖励更高)、更强的稳定性(梯度波动更小)以及更好的探索持久性(熵减更慢),奖励函数用 gpt-oss-120b 配合一些提示词工程,比直接用 math_verify 做匹配鲁棒很多。
最后我们 RL 能在各个领域的难题上能取得很不错的性能增长。
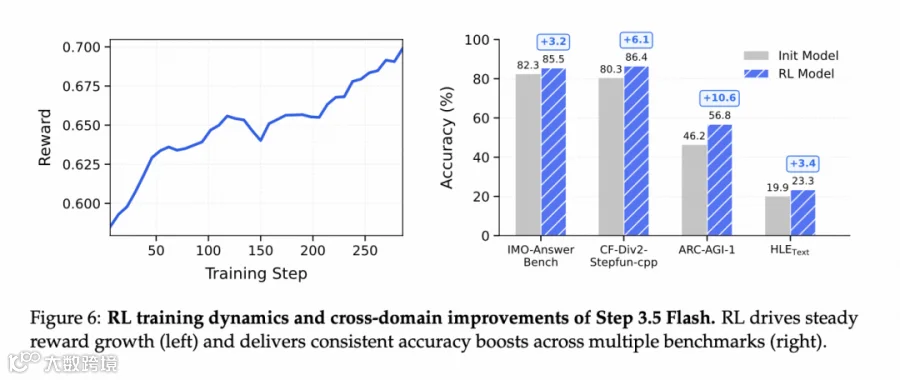
结语
这两天看着技术报告,心里想的不是指标涨点这些,而是想起了最初看到 Llama 7B-LoRA 训一点中文语料部署出来就能聊天,那时候的兴奋。
Step-3.5 Flash 是我们交出的一份阶段性答卷。希望它能成为传递给社区的一根火把。愿微小的篝火,能点亮更多的荒原。
祝大家春节愉快,节后我们还会再上模型的。
感谢小伙伴们,给他们打个广告:
↓后训练↓

↓评测↓

@P2oileen
在阶跃星辰摸鱼
实名上网:Ailin Huang
如果模型高分指标不能被复现,tech report 等同于废纸。
从去年 6 月开始,我在阶跃星辰的基模算法团队负责模型指标评测工作。我和团队一共 6 位小伙伴(大部分是 Intern 同学)们的核心任务,简单来说就是为模型的训练监控判分提供一套稳固的基建。
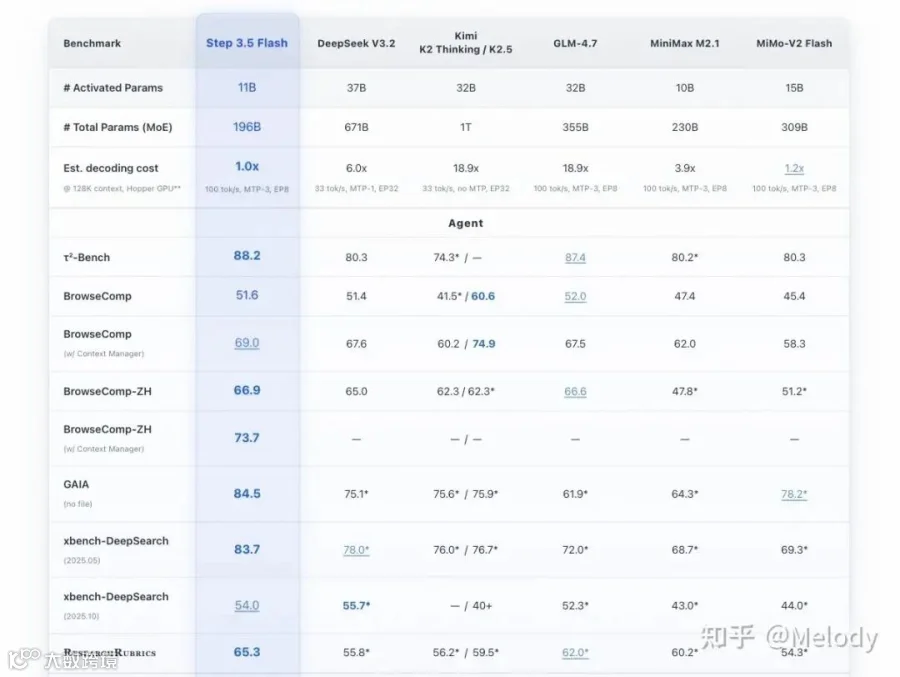
这次 Step 3.5 Flash 的表现非常亮眼:作为一个 196B MoE 架构 A11B 的模型,在竞赛级难度指标上,AIME 2025 取得了 97.3% 的惊人成绩,IMO-AnswerBench 达到 85.4%,LiveCodeBench 达到 86.4%。尤其值得一提的是在 SimpleQA 指标上,它以 11B 的激活参数取得了 31.6% 的准确率,超越了总参数 671B、A37B 的友商旗舰模型。
在即将发布的论文附录中,我们比较自信地(笑)附带了所有报点指标的详细评测方法,欢迎大家来尝试复现。https://http://GitHub. com/stepfun-ai/Step-3.5-Flash
目前我们的评测平台集成了 300 多个外部或内部自建的测试集。借此题我想从基建的角度分享一些技术细节,为了让这些分数真实可靠我们踩过哪些坑,做了哪些微小的工作。
评测基建相关
在大规模评测中,平台面临的测试压力非常大。最头疼的问题是调用失败:无论是供应商接口还是内部服务,总会因为网络波动或负载问题导致连接断掉。
以前的做法比较简单,调用失败没有完整的处理,可能会单纯赋一个低分,但这会严重干扰研究员对模型真实能力的判断,现在我们建立了完善的错误捕获机制,涵盖了待测模型、Judger 模型、tokenizer 等服务(用于一些压缩率指标和其他的 token 长度计算)和沙盒(用于 coding 类指标运行结果)。我们会清楚地统计出具体的调用失败比例和原因并展示在前端,让研究员看到的是确定的失败而不是不明原因的低分。
在推理框架上我们也做了很大改进。最早的流程是必须先转好 HF 权重,部署好服务再测,这中间流程很多,容易产生无法对齐的问题。后来我们改成了在训练框架中,一边训练一边启用护航的从属评测服务自动化测试,彻底解决了训推不一致导致的观测误差。
在管理接入 300 多个指标时,我们也走过弯路。早期管理比较粗放,只有一名管理员负责 review/合并代码,研究员自己接指标,实现方式参差不齐全靠肉眼审核,管理员每天都在救火 233。现在我们推行了接入标准流程和发版制度,明确了责任边界,由熟能生巧的评测团队来承接需求,现在,平台上的 300 多个指标都有明确的负责人,对点和修改记录。最近我们也调教出了好用的 AI Reviewer,并尝试用 Agent 自动接 Benchmark,希望能进一步解放人力。
保证指标的可信度
为了让分数有说服力,我们做了几件事:
我们经常尝试复现外部新发布的友商模型的点位。通过在内部平台测一遍别人的模型,一方面通过全面能力评测建立对外部模型能力的准确认知,另一方面也是验证我们的基建指标能不能和外部对齐。
解决训练数据污染,为了确保成绩没有水分,不是靠背题得到的高分,我们会导出评测平台的测试集给研究员同学进行比对和去重。
解决误判问题。模型答对了但没拿到分,是评测中最冤枉的事。一方面可以通过 Prompt Engineering 来减少误判,最简单的例子是要求模型 put answer in \boxed{},再根据 Pattern 提取。此外,对于一些指标,在内部训练监控时,我们更新了 LLM Judger 到更新的模型(相对于原指标),优化了一些指标不科学的 Rule-based Judger(部分加入了 LLM judger 辅助),并修复了一些指标 Answer Extract 的可能问题。
测试策略。对于样本量少、置信度不足的数据集,我们会多次测试取均值和方差。对于 Pretrain 模型,我们制定了专门的测试策略,比如合理的输出截断(设置 max length 和合适的 stop token),以及通过额外添加 Few-shot 来固定输出 Pattern,确保模型在受控的环境下能展示出真实性能。这里还有老生常谈的各种模型推理参数的正确设置,某些指标刷不上去可能就是评测 Bug,比如 @Yibo Zhu 老师在 Step 3.5 Flash 发布背后的个人感想 中提到「MiMo V2 的 HMMT』25 分数,复现时发现小米官方测试时没把 context 拉长到 256K,导致官方点数比模型实际能力低了足足 11 分」。
Prompt 对齐。最开始接 Benchmark 时不小心把 System Prompt 放在了 Chat Completions 模板的 User 标签里,这一个操作就能在某些模型上差几十个点。在多模态评测(如我们刚发布的 Step3-VL-10B)中,坐标定义的定义方式、Prompt 是否对齐对结果影响极大。这也是为什么我们会在即将发布的附录中开源各指标测试的详细 System Prompt 和 Question Prompt,因为我们要保证能力是可复现的。
针对推理密集型任务和长文任务的专项设计
Step 3.5 Flash 涉及到大量的思考过程。为了评测它的思考质量,我们专门设计了评测流程,额外提供了输出 Token 量的监控。此外,由于超长输入和推理内容对请求压力很大,我们针对性地优化了很多流式接口的 Socket 读取缓冲区逻辑和保活策略。这些基建层面的细节,虽然不显眼,但却是支撑模型在高难度逻辑任务(如 AIME、IMO)和长文指标(如 FRAMES)上拿到高分的前提。
总结
做了 8 个月的大模型评测,最大的感悟是:评测不应仅停留在「接 Benchmark」的阶段,而应该比模型训练稍微先行一点。
在 Step 3.5 Flash 的项目中,目前依然是研究员们通过过往的丰富经验对指标进行筛选,才得到了值得监控的优质指标和合理的测试方式。我们未来的目标是希望能将这种能力量化,通过科学的流程对这 300 多个指标进行质检,从而为研究员提供更清晰的刷点指引。通过评测的确定性,去对冲模型训练的不确定性。希望这套流程能持续改进,能持续为后续的 Step 4 甚至更强的模型保驾护航。也希望这些技术细节能给同行们带来一些 Insight。
最后欢迎大家试用我们的 Step 3.5 Flash,也欢迎大模型评测的相关交流~
↓Search Agent↓

@Melody
step3.5-flash 如期发布,说实话是有超预期的表现。复盘这段时间我们在 Search Agent 方向的探索,最大的收获不是分数上的提升,而是对 Benchmark 评估有效性 的深刻认知。taste 是很重要的,重要的不是做什么,而是不做什么。如果一个 bmk 有捷径,只反应了一个侧面能力,那其实不如不刷。
这里有一个值得社区和学术界共同讨论的现象是,对于实际任务,好的内生知识可以减少 search tool 的调用,节约与环境交互的 context,但代价是更昂贵的预训练(避免知识遗忘和长尾知识持续补充)、严谨但过长的思考,同样的 final answer 输出质量下,孰好孰劣并无很好的评价与定义,这个需要时间与场景的考验。
目前 Browsercomp 的高分模型会比较倾向于将知识参数化。当然这种做法并非错误,只是和想关注的 search agent 能力相悖。或许我们其实应该衡量,模型在调用工具与不调用工具的情况下分数的差值,来衡量模型的实际 agent 场景中 multi-turn long-context condition 的 denoise 和 精准挖掘关键信息 的能力。
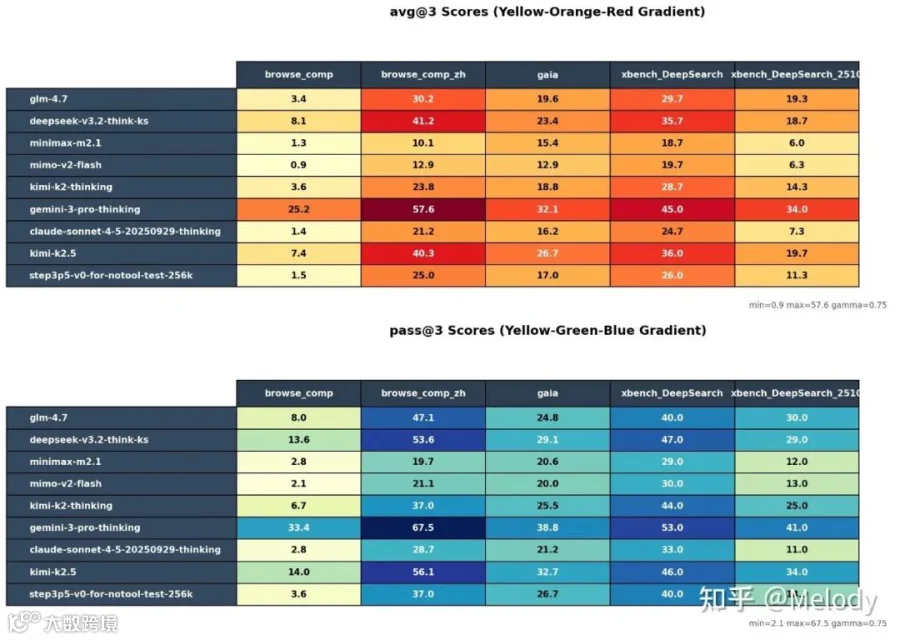
不调用工具时,模型在 search bmk 上的表现
调用工具时,模型在 search bmk 上的表现
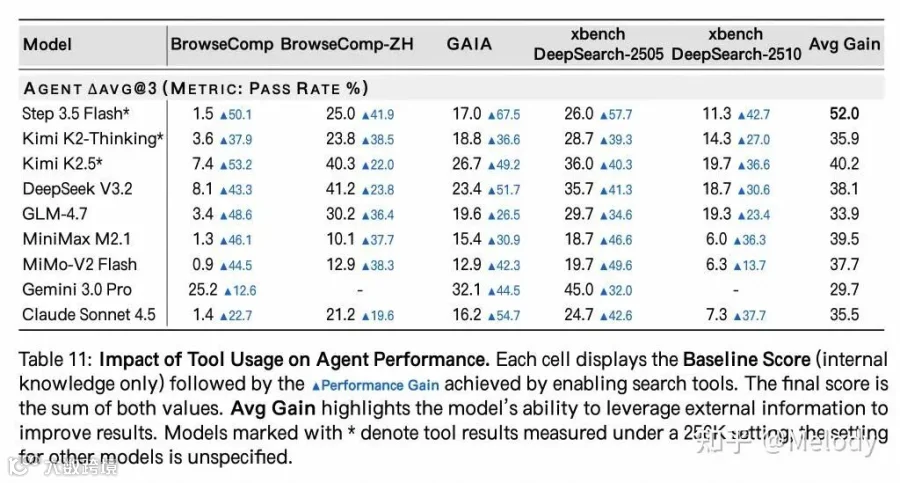
调用工具时的 bmk 分数 减去 不调用工具时的 bmk 分数
除此之外关注一些类似 research rubric 这种偏真实场景的 bmk 不是度量简短的实体名称和数值,而是综合多个维度评估模型输出的一个长报告,会更有实际意义。这样的决策在后面看是有很大收益的:search agent bmk 点数上涨,并没有让模型在真实场景做得更好。相反对真实场景的优化反而带来了各个 search agent bmk 的上涨。甚至部分之前没有监测的 bmk,也因为泛化性表现得很好。
这里也分享一些提升 bmk 分数的做法吧,主要有三个维度可以发力:
更完备的 midtrain:根据我们对 search 场景的理解,拆解定义了几类原子能力并进行了针对性的合成(参考 https://arxiv. org/pdf/2512.20491);此外为了提升模型在真实环境中的表现,我们真的烧了很多搜索的钱合成了百 B 数量级的交互轨迹
agent-RL 效率优化: 早期的 client–server one-step-off-policy 训练架构在训练中受长尾延迟影响严重:约 5% 的样本占据约 80% 的 rollout 时间。同时,我们观察到模型对 off-policy 具有较强鲁棒性,即便存在约 20 步离线也仍保持性能稳定。基于此,我们采用 FullyAsync 范式,使生成与更新完全异步进行。此外,为减少多轮交互的推理开销,我们将同一会话固定调度到同一节点以复用 KV-cache。整体上,该配置在保持训练稳定性的前提下带来约 10× 的效率提升。同时,我们发现 RL from zero 并未随着训练预算增长而显著提升;相比之下,在 mid-training 阶段注入任务相关知识和工具使用先验后,模型在 RL 阶段表现出更显著的性能增益与更稳定的能力涌现趋势。
更好的基模: 说实话,训了半年多的 qwen,已经有点忘了什么叫做」scaling「了,当真正切到 step3.5-flash 之后,智能上是有本质变化的。此外,各个能力(reasoning、agent 等等)数据合版是有意想不到的魔力的。
最后总结一下:过去我们追求 Scaling Law 带来的知识压缩,而现在,通过高质量的 Interaction Data(交互数据)和高效的 RL 探索,我们在赋予模型「承认无知并主动求知」的能力。这或许比单纯刷榜更有意义——因为在真实世界里,「怎么找到答案」往往比「记住答案」更接近智能的本质。真正的智能不在于记住了多少,而在于面对未知时,构建信息获取路径的能力。我们不仅是在训练一个 Answer Engine,更是在训练一个 Researcher。
↓Coding↓

知友讨论
@P2oileen:
技术报告开源啦:https://github.com/stepfun-ai/Step-3.5-Flash/blob/main/step_3p5_flash_tech_report.pdf
@大家都想的挺美:
羡慕有专门的评测团队的,我们都是算法自己干自己维护
@三金乐了:
护航的从属评测服务怎么理解呢?
@P2oileen:
每个训练进程会搭配几个评测service同时运行
@哼唧唧j:
Parallel Thinking以后会考虑开放吗?[思考](虽然说这玩意儿日常用起来好像没有太大用处,但是我看美团好像有。
@Reign:
会的!我们正在积极推动pacore上api & chat前端,有一个可以自己部署的server example,可以先试玩一下:https://github.com/stepfun-ai/PaCoRe?tab=readme-ov-file#-releases
@DreamMr:
我有个问题请教一下,就是单纯只看指标嘛?我之前也做过一些评测的工作,发现大多数时候如果只看指标,实际上相差的不多(可能就0.x%)请问像这种情况,一般还会怎么评测呀?或是就这样
@DreamMr:
可以观摩一下(https://zhuanlan.zhihu.com/p/2001785310347036605)nao老师是我看下来民间测评最客观的
@丨直树丨:
"最早的流程是必须先转好 HF 权重,部署好服务再测,这中间流程很多,容易产生无法对齐的问题。后来我们改成了在训练框架中,一边训练一边启用护航的从属评测服务自动化测试,彻底解决了训推不一致导致的观测误差" 意思是eval是不用vllm/sgl之类的框架吗,感觉训练的框架直接eval还挺难的
@P2oileen:
是用vllm做推理,原文的意思是中间是省去了部署服务的一些流程,训练完的ckpt直接在内存里动态加载权重做推理,就没有类似 rope scaling 没对齐这样问题了
@Gary扬:
你好,请教下文中提到的"模型对off-policy具有较强鲁棒性"这个发现是指search场景,还是所有agentic的任务?
@Melody:
仅限于step3.5-flash + search场景
阅读更多
🚀 AI 产品扶持计划:
知乎为 AI 产品提供定制宣发支持,了解/报名请戳:知乎「AI 新品非正式发布现场」扶持计划
🚀 知乎 AI 社群:
如果你是泛 AI 爱好者,对 AI 资讯感兴趣,欢迎扫码加入知乎 AI 社群↓,我们将每周送上 AI 周报,不定时发布 AI 线上线下活动与 AI 产品测试尝鲜。

知乎AI交流群
让一部分开发者先走起来
🚀 知乎科技账号正式登陆 X:
👉 https://x.com/ZhihuFrontier,聚焦「技术 × 观点」的跨语境对话