

今日话题:Context Engineering
7 月 1 日,Hacker News 榜首文章《The new skill in AI is not prompting, it’s context engineering》中提出了一个观点:决定 AI 代理效果的关键已经从「写好提示词」转向了「上下文工程」。
它将「上下文」从单一提示扩展为包含七个维度的完整信息体系:系统指令、用户提示、对话历史、长期记忆、外部检索信息、可用工具和输出格式定义。
如何看待观点:
AI 的关键点不是 prompt
而是 Context Engineering?
@Navis Li
7 月 2 日发布于知乎
确实,单纯写 prompt 已经不够了。
最开始大家都在研究怎么写「完美提示词」,但现在你会发现,真正决定 AI 应用成败的,往往不是那几句话写得多精妙,而是你给 AI 准备了什么样的「食材」。
为什么很多问题你开了联网搜索反而会得出一堆乱七八糟的结论?就是因为联网搜到的垃圾信息太多了,「垃圾输入只会带来垃圾输出」就是这个意思。
就像 Tobi Lutke 说的,Context Engineering 就是「为任务提供所有上下文,使 LLM 能够合理解决问题的艺术」这的关键在于「所有上下文」这四个字。
那么 Context Engineering 到底包含什么?
Context 远不止是一句 prompt,它包括:
指令/系统提示:定义模型行为的初始指令
用户提示:来自用户的即时任务或问题
状态/历史:当前对话的短期记忆
长期记忆:跨多次对话收集的持久知识库
检索信息(RAG):来自文档、数据库或API的外部知识
可用工具:模型可以调用的所有功能定义
结构化输出:对模型响应格式的定义
这其实就是在构建一个完整的「AI 工作环境」,而不是简单地给 AI 下指令。
举一个很典型的例子来说明:
场景:AI 助手收到邮件「明天有空开会吗?」
普通 AI 的回应:
感谢消息。明天可以,你想要几点?
而有「完整工作环境的 AI」在回应前会收集:
你的日历信息(显示明天全天都被安排满了)
与这个人的过往邮件(确定合适的非正式语调)
你的联系人列表(识别他们是重要合作伙伴)
发送邀请或邮件的工具
然后生成回应:
明天我这边排得很满,整天都是会。要周四上午才有空,你看行吗?我发个邀请,你看看时间合适不。
所以你看到差别了吗?「神奇」的不是算法更聪明,而是上下文更丰富,你提供了更多的有效信息给 AI。
这是 AI 应用的必然进化,而且对于中国是好事
传统的 prompt engineering 本质上还是在做「人机对话」我问你答。但 Context Engineering 已经在做「人机协作」了 — AI 会变成了一个有完整工作环境的「赛博同事」。
所以我非常看好这一波 AI 代理 ( Agent ),AI 不再只是回答问题,而是要主动完成任务,这时候光有好的 prompt 就不够了。
中美 AI 模型的性能差距在快速缩小,这说明技术壁垒并不存在,真正的差异化竞争在于工程能力。
Context Engineering 本质上反映的是 AI 应用从「实验室玩具」向「生产工具」的转变。就像早期的网页开发,从简单的 HTML 页面演进到复杂的 Web 应用架构一样,AI 应用也在经历同样的工程化过程。
所以我的判断是:Context Engineering 确实是当前 AI 发展的关键方向。不过,这并不意味着 prompt engineering 就不重要了,而是说单纯的 prompt engineering 已经不够了,我们需要更系统化的思维来构建 AI 应用的整个上下文环境。
@桔了个仔
7 月 2 日发布于知乎
prompting 其实从来都不是 AI 的关键点,尤其是在这两年 LLM 的文本生成能力很强,即使你写不好 prompt,市面上也有很多 AI 工具可以帮你做 prompt enhancement。
随着人们对 Agent 的能力要求越来越高,仅仅靠 prompt 也无法满足人们对 AI 的期待了,人们期待 AI 能「有记忆,懂用户」。因此,Context Engineering(上下文工程)就开始被关注到。
context engineering 是指通过系统性构建、管理和优化 AI 模型的输入上下文,以提升模型在复杂任务中的理解与输出能力。
其中包括几部分:
第一是历史交互数据。例如多轮对话记录(用户与模型的历史对话内容),交互行为数据,(如用户操作日志,如电商推荐中用户多次浏览但未购买的商品类型)。
第二是 context 的总结。对话可以一直延续,但模型的上下文窗口有限,怎么记住之前的对话?当然是压缩,例如把最近 5 条对话的内容原封保留,再之前的内容总结一下。
但更重要的,是领域知识与背景信息。
AI 的能力来源于两个方面 in-weights memory(训练集里学到的) 和 in-context memory(参考资料里学到的)。 in-weights memory 基本上是很难修改的,但 in-context memory 更容易修改和更新,你只要提供新的资料,正确的资料,模型就能有「新知」。
下面有请 @知乎直答 出来挨夸。知乎直答更新了一个功能:知识库支持公开分享了。
公众号小编注:只是举例,真的不是广告
这意味着啥?意味着,你现在使用直答问问题,模型参考的资料,是行业专家里帮你筛选出来的资料库,而不是 search agent 自己到处搜的资料。用过各种 deep research 的小伙伴会发现,模型有时候参考的搜索结果真的不靠谱。例如我搜索「桔了个仔」,search agent 可能会返回「果园桔子大丰收」这样的结果给模型参考。
而指定知识库后,我就可以只把这部分内容 feed 进 in-context memory,这样,整个 context 会更纯净。例如我用 @白小鱼 创建的《【知识库】人工智能报告集》,就可以得到业内准确的关于 AI Agent 的研究总结。这就是 clean context 的好处。
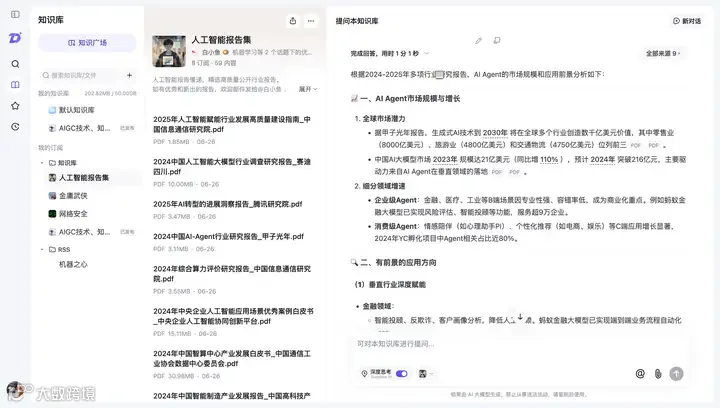
啊,我又不小心免费给知乎直答打广告了@知乎科技 @知乎直答 速速打盐粒给我!
另外一个 context Engineering 的应用是 Cursor rule,它能够整合多维度上下文信息,加速上下文检索,减少用户手动提供上下文的负担。Cursor rule 是用户为 Cursor 编写的一组指导说明,以配置文件形式存在,可用于定义上下文边界、设置相关性层次、控制访问模式等,能让 AI 更好地理解和处理代码库。有 github 网友提供了一些不错的 cursor rule 案例(github.com/PatrickJS/awesome-cursorrulesgithub.com/PatrickJS/awesome-cursorrules)
中午 @强化学徒 吐槽 Cursor 用不习惯,我的建议就是来点 rule,其实也是 context engineering 一下。期待 @强化学徒 的反馈。
但是,context engineer 看起来容易碰到上限,AI 能力的发展方向,what is next?
我认为是长上下文。这是大力出奇迹的方法。虽然目前很多长上下文模型表现并不好,但可能未来通过工程方法,新型架构的突破,长上下文模型会有质的飞跃。
@程墨Morgan
7 月 2 日发布于知乎
Context Engineering 就是新瓶装旧酒,但是这种装酒的方式是非常必要的。
长期以来,Prompt Engineering(提示词工程)给人的感觉就是,以后搞 AI 应用就是用自然语言写提示词这一项技能了,各种所谓 Prompt Engineering 的技巧也都涌现了,一套一套的,但是核心就是自然语言写作。
搞 AI 真的这么简单吗?
显然不是。
Prompt Engineering 让很多人只关注于最后的「提示词」却忽略了管理和生成提示词的过程。
换句话说,真正的复杂的 AI 应用,不是靠 chat 输入提示词这么简单,而是需要自动化多次和大模型的交互,这个自动的过程中,需要能够自动产生给大模型的提示词。
我最近研究 Cursor 的工作方式,就是 Context Engineering 的实践,一个很简单的交互流程就如下图这样管理上下文,左侧这些方框里的东西就是 Context,我们一步一步看,上下文是如何被管理的。
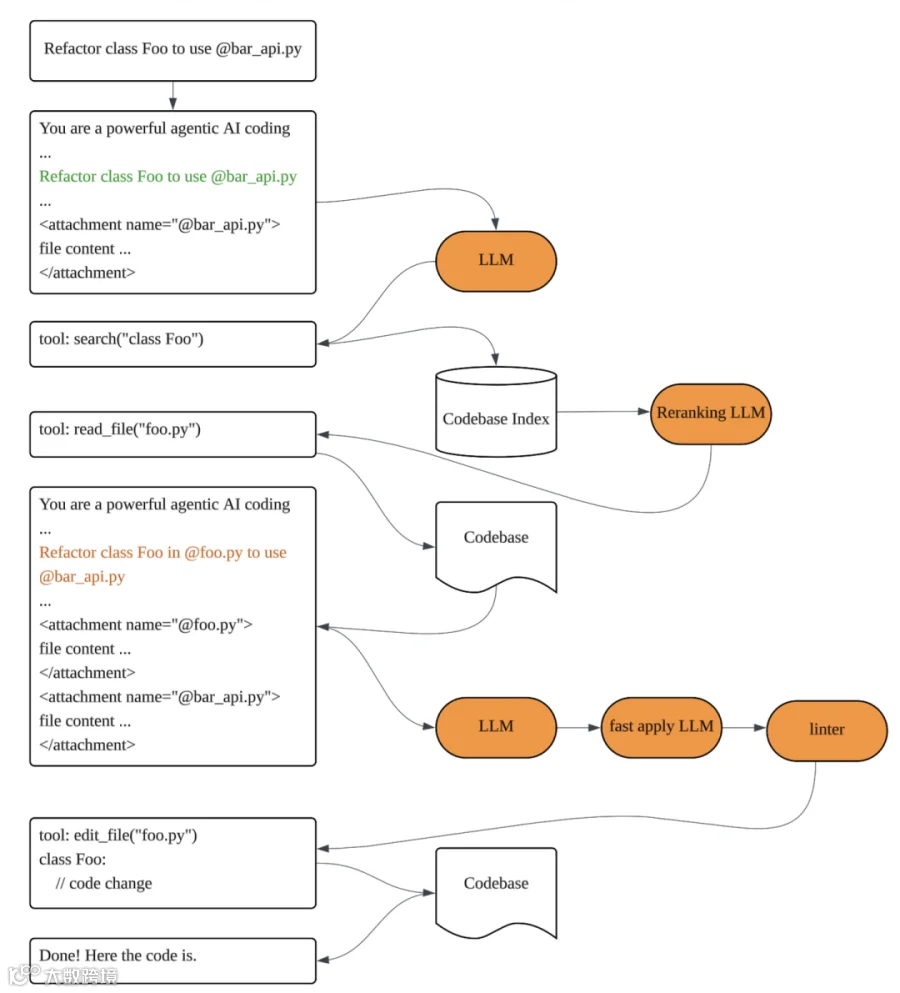
上来,用户给的提示词就一句话:

纯自然语言,讲得很清楚,让 AI 重构 Foo 这个类,用于适应 bar_api.py 这个文件——虽然这个提示词很清楚,你觉得直接塞给 AI 大模型它就能干完吗?
当然不能。
AI 不知道 Foo 类定义在哪个文件里,也不知道 bar_api.py 里是个什么玩意,这些,需要 Cursor 的代码攒一个完整的提示词告诉 AI,而且还需要分步骤进行。
第一步,Cursor 读取 bar_api.py 的内容,然后攒出这样一段完整的提示词,前面加上「You are a powerful agentic AI coding」这样的身份设定,然后加上用户输入的提示词,最后还要把 bar_api.py 的内容加上,这才基本包含了比较完整的上下文。

第二步,把上面的提示词塞给 AI 大模型,同事还要告诉 AI 大模型一些 tool 可以用,AI 大模型不知道 Foo 类在哪里,就会输出对于 seach tool 的调用。

第三步,这时候,Cursor 的代码库索引又派上用场了,根据 search 在向量数据库中搜索 class Foo,得到的结果经过一个 ReRanker LLM 排序(注意这个 ReRanker LLM 未必是前面第二步一样的 LLM),得到 class Foo 定义在文件 foo.py 里。
第四步,Cursor 再读取 foo.py,再次把 foo.py 的内容和之前的提示词整合,这时候上下文差不多是这样,再次塞给 LLM。

第五步,LLM 理解了请求,对于 foo.py 进行初步修改,但也只做大概的修改。
第六步,另一个 LLM,专门改代码的 fast-apply LLM 上场了,根据第五步的结果对 foo.py 代码进行精细化修改。
第七步,终于搞定了。
你看,简单一个『Refactor class Foo to use @bar_api.py』的提示词请求,背后 Cursor 要做这么多工作才能管理好上下文,不要指望这些靠和 AI 聊天就能完成,这个过程需要精细的规划、架构设计、代码实现,才能无误差地完成任务,
嗯嗯,这个过程需要精细的规划、架构设计、代码实现,才能无误差地完成任务。
是的,这个过程需要精细的规划、架构设计、代码实现,才能无误差地完成任务。
你有感觉吗?我再重复一遍——
这个过程需要精细的规划、架构设计、代码实现,才能无误差地完成任务。
是不是看着很眼熟?
回到我最开始的论点—— Context Engineering 就是新瓶装旧酒,但是这种装酒的方式是非常必要的。
当我们把这个酒瓶上的 Context Engineering 标签撕开,会发现,下面写着的就是——Software Engineering。

图片由 Gemini 2.5 Pro 生成
没错,所谓Context Engineering,其实就是Software Engineering!软件工程是永远需要的,所以这种装酒的方式非常必要。

More
MCP、Function Calling 有什么区别?与 AI Agent 是什么关系?丨AI 青年大学习
为什么开发 Agent 容易,让它好用却很难丨知乎 × 晚点
知乎 AI 社群:
如果你是泛 AI 爱好者,对 AI 资讯感兴趣,并愿意认真测评、为开发者反馈真实意见或交流沟通。
欢迎扫码加入知乎 AI 社群↓,我们将不定时送上 AI 热点问答和产品测试活动。

知乎AI小卖部
让一部分开发者先走起来