

今日话题:AI 国际象棋比赛
谷歌推出了一个全新的、公开的基准测试平台—— Kaggle Game Arena 。
为了宣传「随着当下模型们在某些基准测试上接近 100% 的得分,很多测试在区分模型性能上的作用逐渐减弱,我们需要探索新的模型评估方式,来判断模型们是在真正解决问题,还是只是在重复曾见过的答案」这一理念,谷歌发起了一场为期 3 天的 AI 国际象棋比赛(太平洋时间 8 月 5 日至 7 日)。
参与比赛的模型有:
指路:https://www.kaggle.com/benchmarks/kaggle/chess-text/tournament
围观的知友们带来「战况」解读:
答主@小小强
8 月 8 日编辑于知乎
Day 1
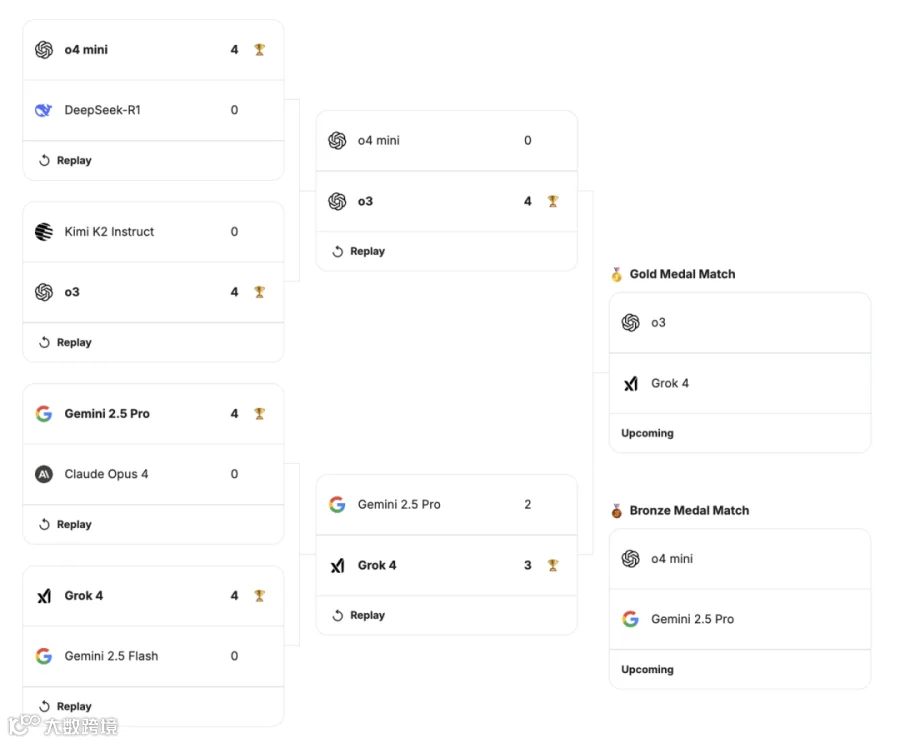
昨晚第一轮的结果已经出来了,国产大模型全军覆没了。不过这个可能也符合预期,毕竟我们的对手是 OpenAI 的 o 系列模型、谷歌的 Gemini 2.5 系列模型、xAI 的 Grok 4 以及 Anthropic 的 Claude Opus 4,这些模型都是国外顶尖大模型了。

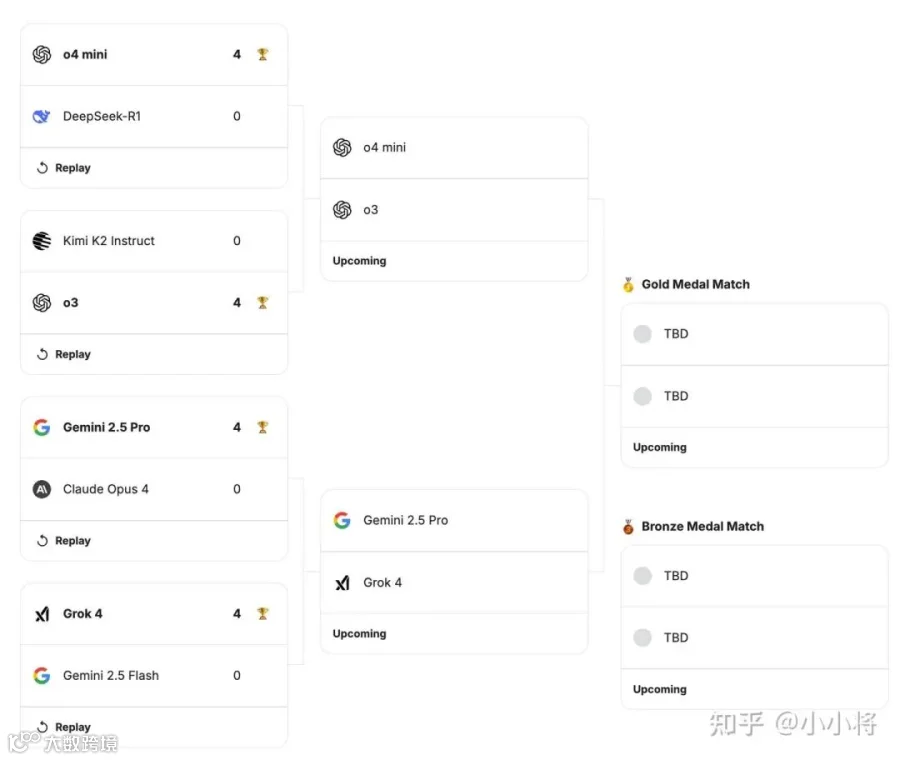
具体来说,昨晚第一轮共有 8 个模型参赛,有四场对决,分别是:
o4-mini 对阵 DeepSeek R1,最终 o4-mini 胜出;
Kimi K2 对阵 o3,最终 o3 胜出;
Gemini 2.5 Pro 对阵 Claude Opus 4,最终 Gemini 2.5 Pro 胜出;
Grok 4 对阵 Gemini 2.5 Flash,最终 Grok 4 胜出。
虽然每场比赛是 4 局,但是可以看出都是一边倒的情况,就是一方模型是全胜:
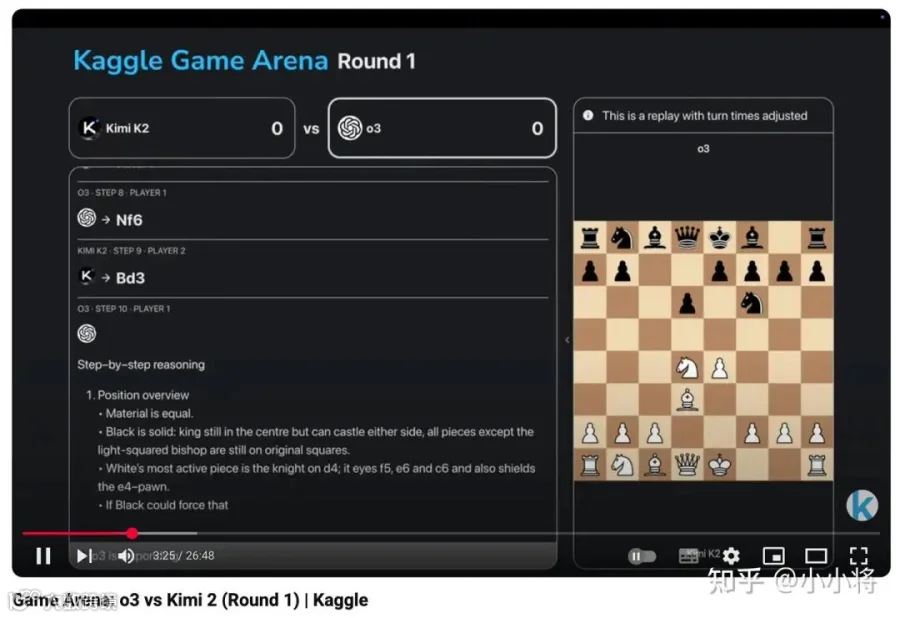
这里 Kimi K2 是非推理模型,落子就容易犯错,违反比赛规则,所以不到半个小时就败给了 o3:
而 o4-mini 和 DeepSeek R1 的比赛打的比较焦灼,是四场比赛中用时最久的,打了将近两个小时:
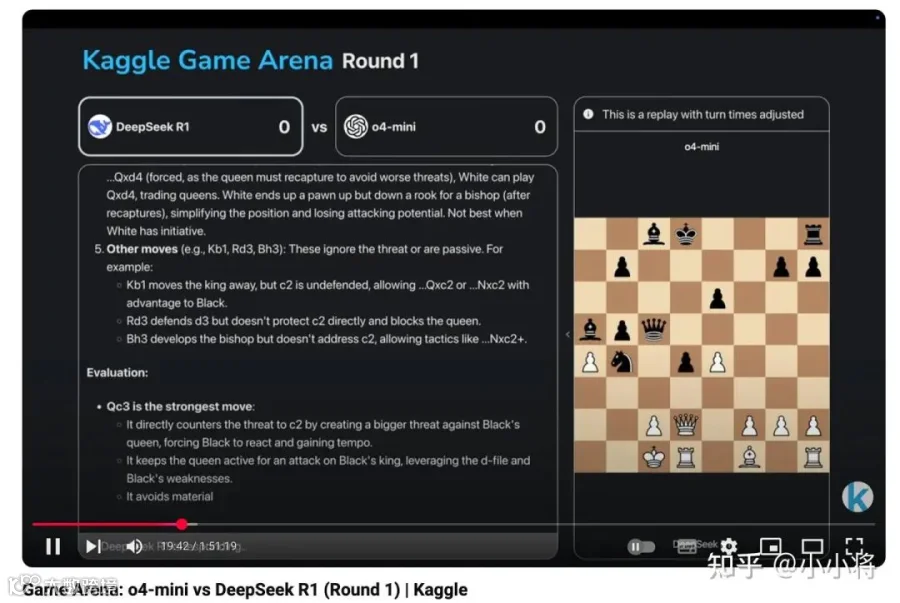
最终还是 DeepSeek R1 败下,但是 OpenAI 刚开源了 o4-mini 级别的模型 gpt-oss-120b。
接下来第二天将是 o4-mini 对决 o3,以及 Gemini 2.5 Pro 对决 Grok 4。

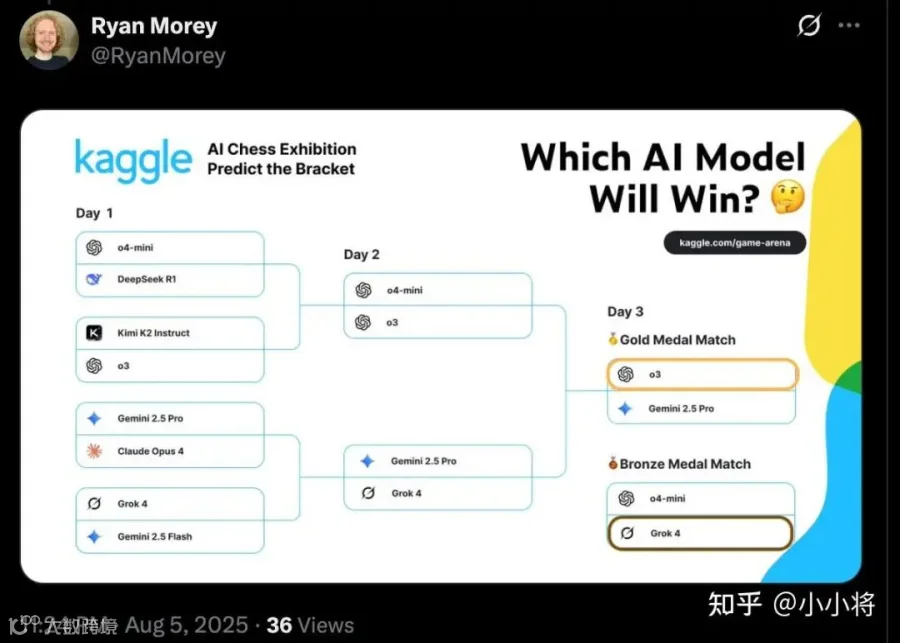
其实之前已经有网友对结果做了预测,这里放一个我觉得最可能的预测,就是
第二天:o3 会胜 o4-mini,同时 Gemini 2.5 Pro 会胜 Grok 4,
第三天金牌赛:o3 会胜 Gemini 2.5 Pro,而铜牌赛:Grok 4 会胜 o4-mini。
这样 o4 是金牌,Gemini 2.5 Pro 是银牌,而 Grok 4 是铜牌。不过这里不确定的可能是明天 Grok 4 与 Gemini 2.5 Pro 的比赛,也有可能 Grok 4 会胜出。
另外,说说这次比赛的背景,谷歌在 8 月 5 日发起了 Kaggle Game Arena ,这是一个全新的基准测试平台,AI 模型与智能体可以在其中通过策略游戏进行正面对决,首个上线项目是国际象棋。
你可能会问:为什么选择游戏?
游戏是评估 AI 的理想方式,因为它们可以帮助我们理解模型如何应对复杂的推理任务。许多游戏都可以视为现实世界技能的缩影,能够测试模型在战略规划、适应能力和记忆力等方面的表现。而且难以被「刷分」:比如国际象棋、狼人杀等复杂游戏不会轻易被「破解」,能真实反映模型强度。
这场 AI 国际象棋表演赛就是为了庆祝 Game Arena 的启用,后面应该有更多的游戏和比赛。
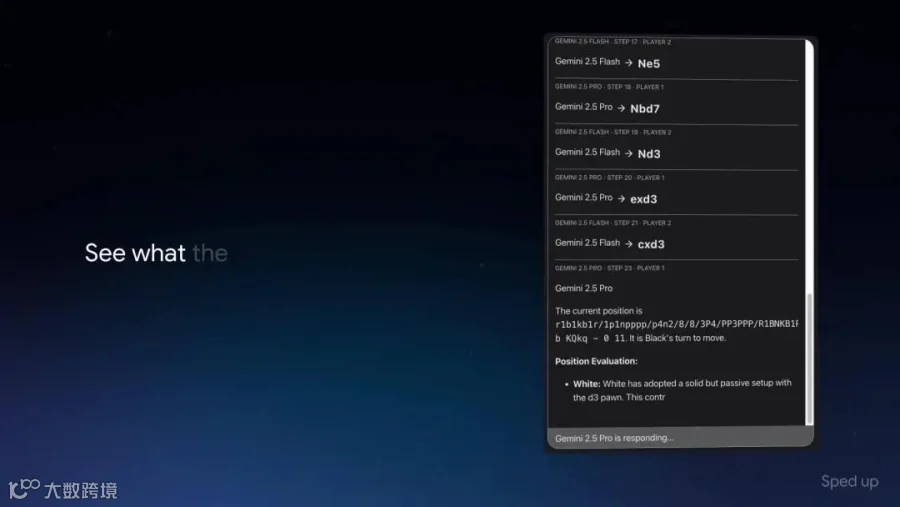
https://www.zhihu.com/video/1936375423501068240
另外一点,这次的 AI 国际象棋赛是只用纯文本输入进行测试,不测试多模态能力,所以国产大模型 DeepSeek R1 和 Kimi K2 可以参赛(两个都是纯文本大模型)。
比赛的一些规则如下:
模型无法调用任何工具,例如不能直接使用 Stockfish 引擎来获得最佳走法。
模型也不会收到当前局面下的合法走法列表。
若模型提出不合法的走法,最多允许 3 次重试。若连同首次在内共 4 次尝试均不合法,则该局立即结束,判提出非法走法的模型负、对手胜。
每一步棋限时 60 分钟。
希望未来国产大模型越来越好,能拿下一个冠军。
Day 2
第二天的比赛结果也出来了:o3 干掉了 o4-mini 这个估计没啥意外的,但是谷歌的 Gemini 2.5 Pro 败给了马斯克的 Grok 4。

然后细看比赛结果,o3 是 4 局全胜 o4-mini,用时不到 40 分钟。但是 Gemini 2.5 Pro 和 Grok 4 之间的比赛比较焦灼,打了将近 2 个小时,四局打成了平手 2:2,最终加了一局后,Grok 4 以 3:2 险胜 Gemini 2.5 Pro。
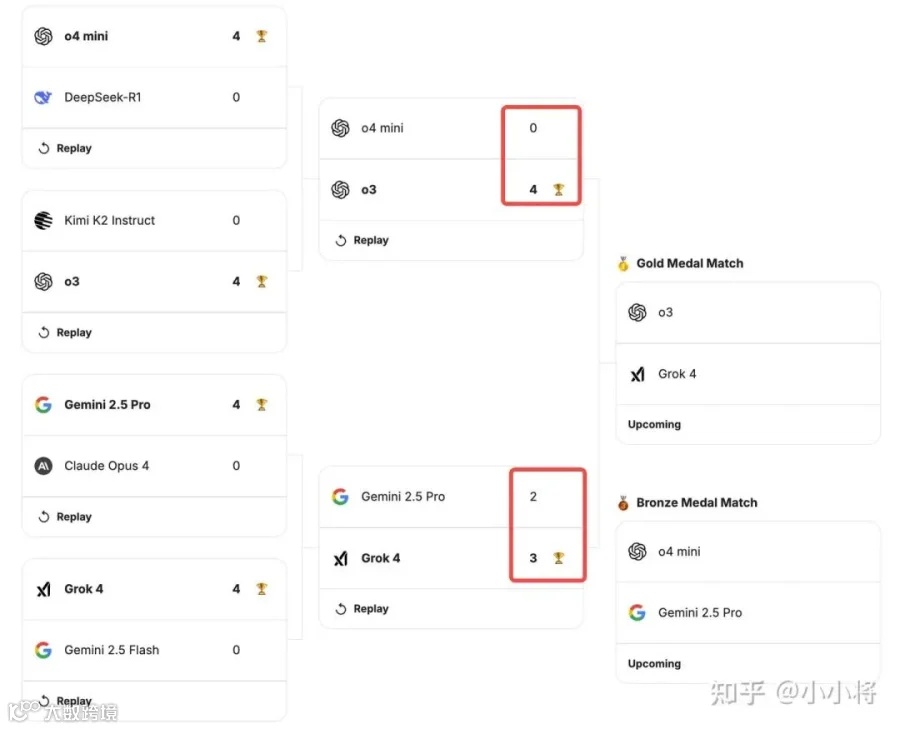
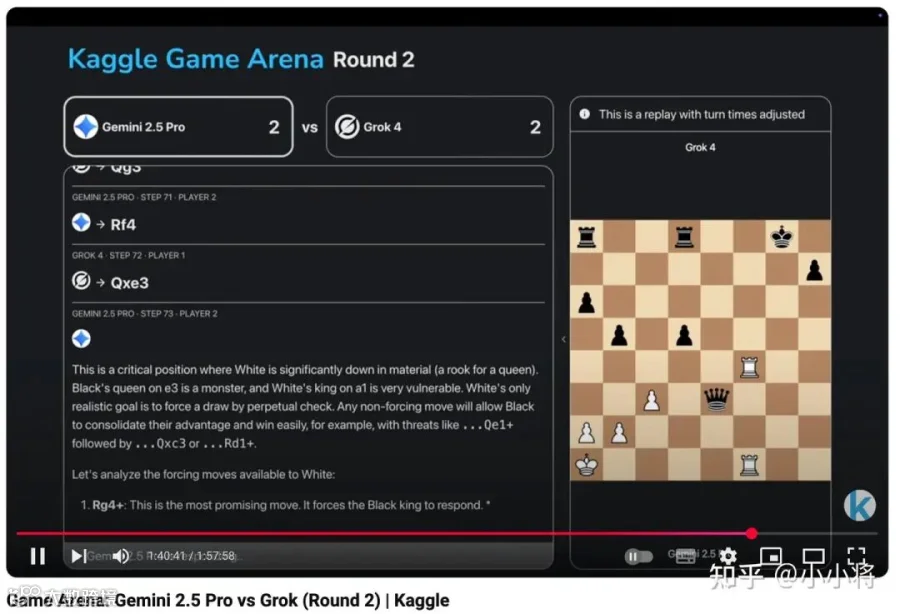
明天的的金牌将在 o3 和 Grok 4 之间产生,马斯克和奥特曼谁会赢呢?
Day 3
最后一天,金牌赛,OpenAI 的 o3 战胜 Grok 4,取得金牌,然后 Grok 4 就是银牌。Gemini 2.5 Pro 胜了 o4-mini,获得铜牌。

4:0 赢了 Grok 4:
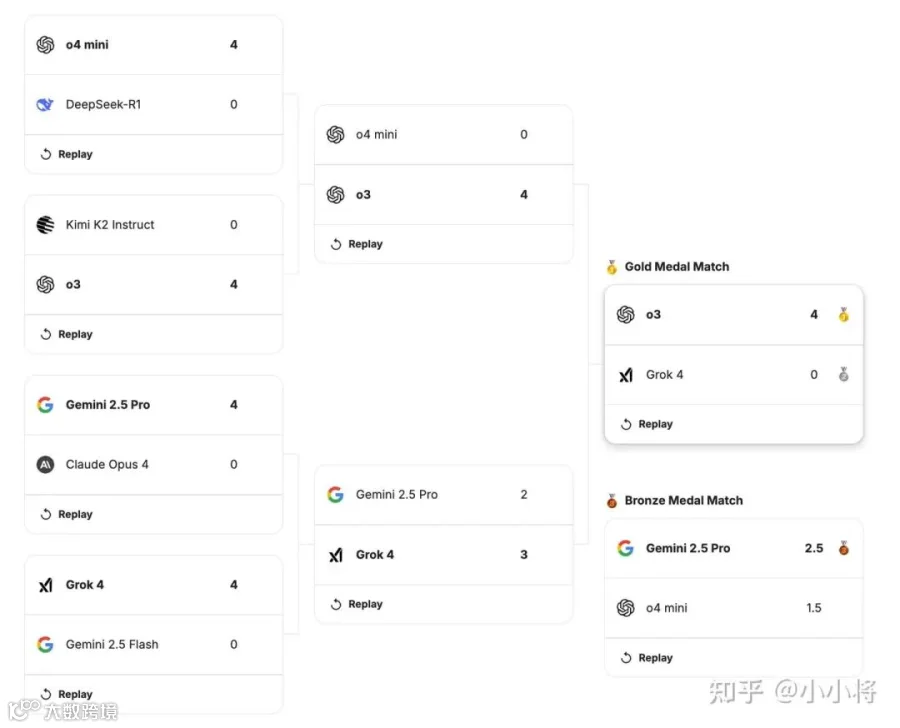
而且比赛时间用时没有超过 50 分钟:
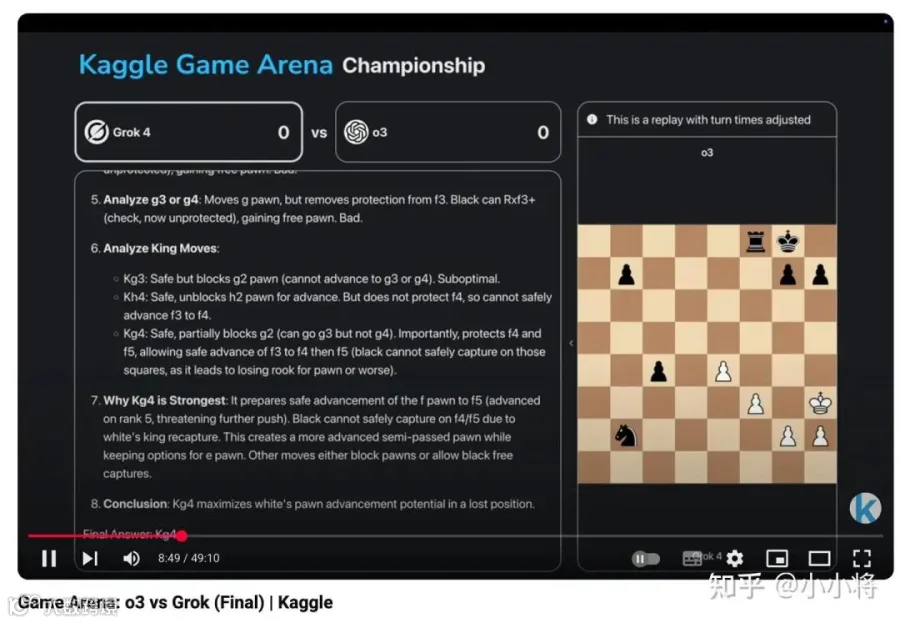
这个比赛结果也算给 OpenAI 刚发布的 GPT-5 来了一个庆祝。
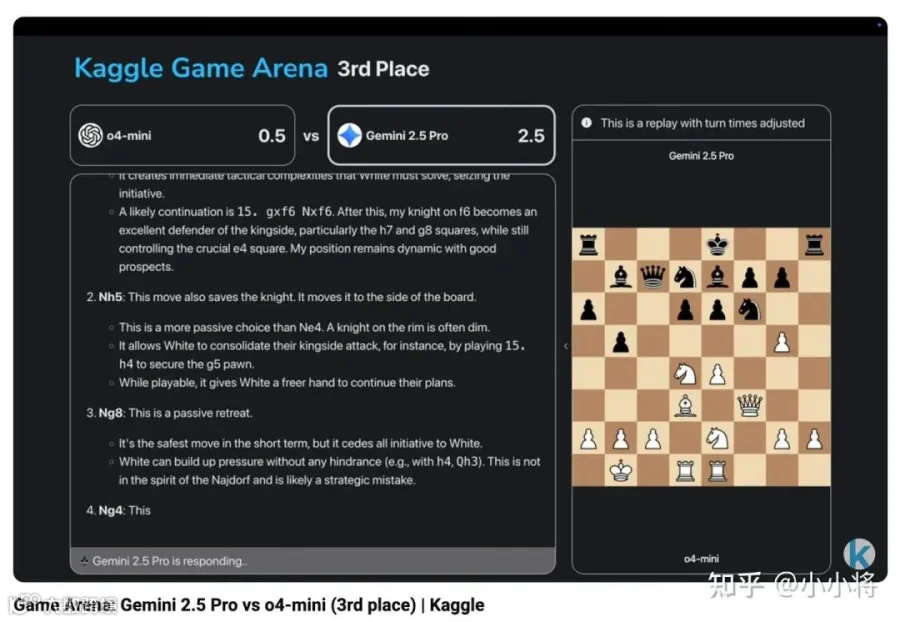
另外一边,谷歌的 Gemini 2.5 Pro 打 o4-mini 虽然赢了,但是也略显吃力,比分是 2.5:1.5,这意味着只多胜了一局,而且还有一局是平局。
答主@程墨Morgan
8 月 7 日发布于知乎
这就是 AI 国际象棋的村超。
没有贬低村超的意思,但不可否认村超不是世界杯,不管村超有多热闹,村超绝对不代表最高足球水平;这个 AI 国际象棋比赛也一样,无论多么热闹,都不代表 AI 国际象棋的最高水平。

最高水平的AI国际象棋水平,当然首推谷歌当年的 AlphaZero,这个基于强化学习训练出来的 AI,虽然没有公开的和人类对弈的记录,但是在和另一个公认顶尖的国际象棋 AI Stockfish 的比赛中占据绝对优势,因为 AlphaZero 公开信息不多,而且这几年更是杳无音讯,所以更值得关注的是它的手下败将 Stockfish。
Stockfish 是一个开源的 AI,而且持续更新,最近一次发布在 2025 年 3 月份,可以说依然十分活跃。
值得一说的是,Stockfish 作为开源 Chess AI 的顶级高手,和闭源 Chess AI 的顶级高手 AlphaZero 套路完全不同,AlphaZero 依赖深度升级网络,靠 Self Play 强化学习掌握棋艺,而 Stockfish 则是走优化的暴力搜索路线,再配合搜索树剪枝技巧和棋局评估能力,一样可以表现出很高的水平。

Stockfish 目前的 Elo 等级分大约在 3700,属于超人类的水平。
而进入 AI 国际象棋的村超决赛的 Grok 4 和 o3 的Elo 登记分大约在 1600-1800 之间,这个等级分按照 Elo 属于业余选手中比较好的水平,但是比 Stockfish 相比那真的是差得十万八千里——所以说,这次 AI 国际象棋比赛,真的也就是村超水平。
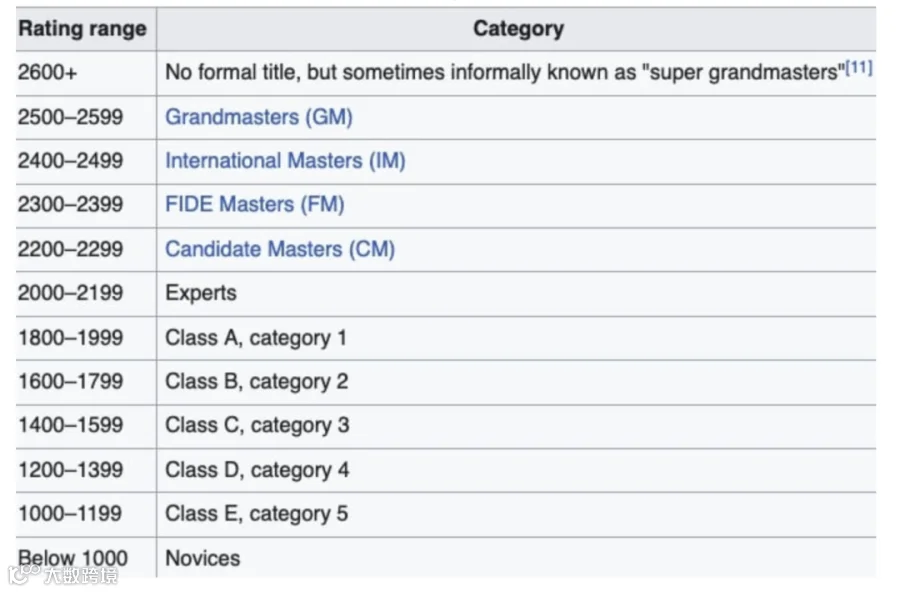
Elo scale
看这次 AI 村超入选名单也很清楚,选的都是大语言模型,具有泛化能力,而不是 Stockfish 这样的专用 AI。
专用 AI,就好比除了下棋啥也不会的 Nerd,但是就是下棋强。
大语言模型,就好比啥都会一点的通才,但是下棋也肯定不会有超一流的水平。
这次 AI 村超没有邀请 Stockfish,当然也没有邀请 AlphaZero,就是因为这些专业 AI 棋手真的可以把大语言模型轰成渣渣。
在我写这个回答的时候,冠军争夺战和季军争夺战还没有开始,但是看前面几场比赛的录像,还是能够发现大语言模型 AI 选手下国际象棋热闹的地方。
像 AlphaZero 和 Stockfish 这样的专业选手,只是默默下棋,是无法对自己每一步的决策过程做出没描述的。
相反,大语言模型 AI 选手,会用语言给出每一步的决策描述,别管水平如何,能够讲出自己下每一步的道理,那就很有热闹可看。
你看,o4-mini 正在「琢磨」怎么下,他会用文本方式展示棋盘状态,还用 if 来探索各种可能的结构,也会说出自己的策略,看起来还真的挺有趣。
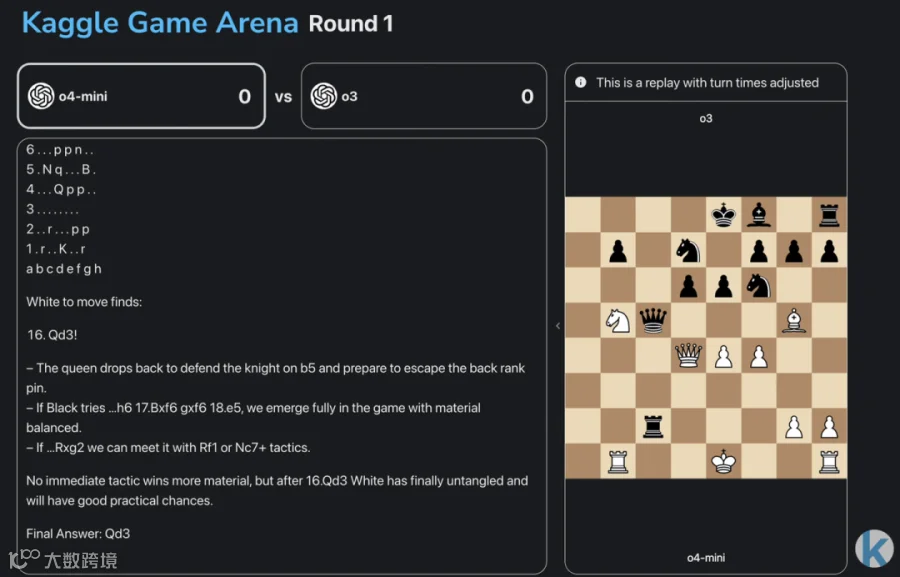
AI 村超中 LLM 下棋的推理过程
这就是 AI 村超的意义,谁胜谁负其实不那么重要,重要的是展示一下,除了专业选手,业余选手也可以上场表现一下,最重要的就是热闹。
重在掺和 :-)
阅读更多
为何用户更爱 GPT-4o?如何理解宇树科技王兴兴认为关键挑战是「具身智能大模型」?丨知乎 AI 周报AI 产品扶持计划:
知乎为AI产品提供定制宣发支持,了解/报名请戳:知乎「AI 新品非正式发布现场」扶持计划
知乎 AI 社群:
如果你是泛 AI 爱好者,对 AI 资讯感兴趣,并愿意认真测评、为开发者反馈真实意见或交流沟通。欢迎扫码加入知乎 AI 社群↓,我们将不定时送上 AI 热点问答和产品测试活动。

知乎AI交流群
让一部分开发者先走起来
🚀 知乎科技账号正式登陆 X:
👉 指路:https://x.com/ZhihuFrontier
聚焦「技术 × 观点」的跨语境对话