

全球食品供应链日益脆弱,凸显了对快速、准确且无损的真实性检测技术的需求。在本研究中,我们开发并验证了一种工作流程,该流程将傅里叶变换红外光谱(FTIR)、近红外光谱(NIR)和X射线荧光光谱(XRF)与基于机器学习的数据融合技术相结合,用于红茶的真实性鉴别。
研究共分析了532份真实的阿萨姆(Assam)、大吉岭(Darjeeling)、锡兰(Ceylon)和祁门(Keemun)红茶样品,并使用了五种监督学习模型。我们开发并比较了一系列信息级、特征级和决策级融合策略,其中决策级融合在校准集、验证集和测试集中均达到了100%的F1分数,其性能优于单一光谱方法及其他融合方法。
该工作流程进一步应用于89个市售红茶样品,识别出6.74%的不合规率,且所有问题样品均来自在线平台。该方法无需昂贵的质谱或稳定同位素仪器,非常适合在非专业实验室(尤其是在发展中国家)进行准确、经济的食品真实性检测。
01
研究背景
问题严峻性:全球化、疫情、气候变化等因素使全球食品供应链变得脆弱,经济利益驱动的食品欺诈(如用普通茶冒充高价值的地理标志茶)问题日益严重。
现有技术局限:传统的高精度鉴别技术(如同位素质谱、电感耦合等离子体质谱、高分辨液相色谱-质谱等)虽然准确,但成本高昂、操作复杂、样品前处理繁琐,难以在常规实验室,特别是资源有限的发展中国家普及。
新方法机遇:快速、低成本、无损的光谱技术(如FTIR, NIR, XRF)结合人工智能(AI)和大数据,为开发适用于一线筛查的真实性检测工具提供了可能。
02
主要方法
核心策略
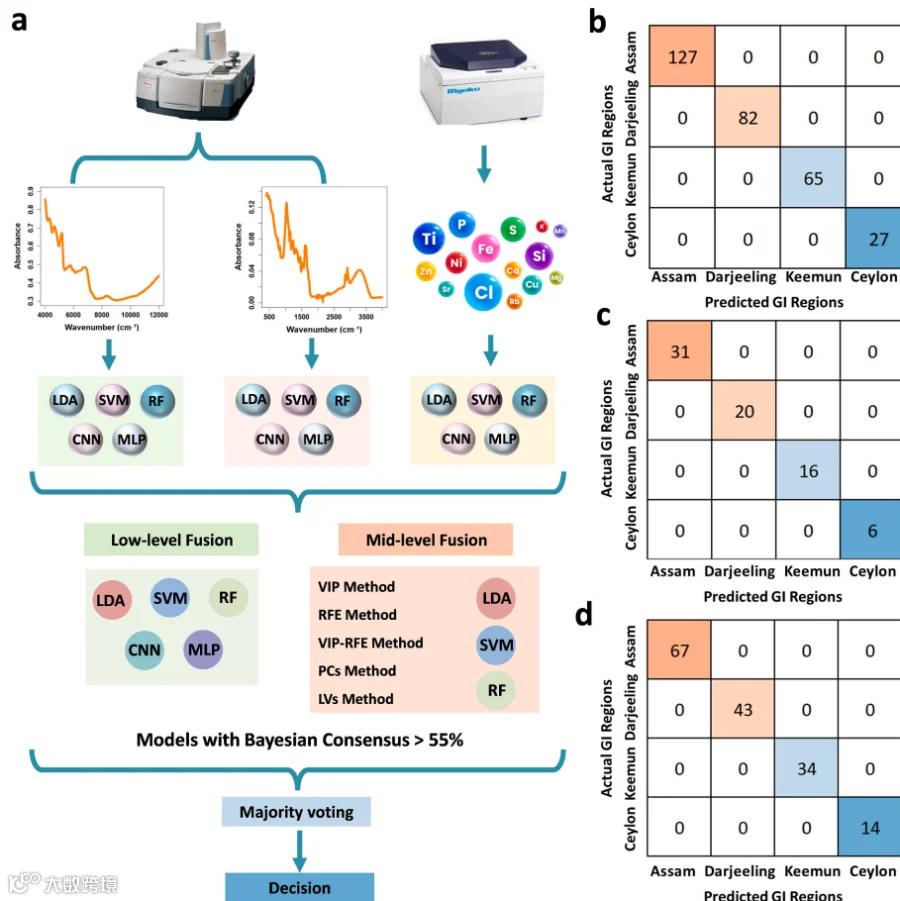
采用“多平台光谱 + 机器学习 + 多层次数据融合”的综合策略。
数据采集
样本:收集了532份来自四大知名产区(阿萨姆、大吉岭、锡兰、祁门)的真实认证红茶样品作为模型训练和验证的基础。
光谱:对所有样品分别进行FTIR(提供分子官能团信息)、NIR(提供有机成分信息)和XRF(提供元素指纹信息)分析。
机器学习与融合
模型:构建了五种监督学习模型,包括传统模型(LDA, SVM, RF)和深度学习模型(1D-CNN, MLP)。
融合层级:
信息级融合:直接拼接三种光谱的原始数据。
特征级融合:从各光谱数据中提取关键变量(如通过VIP、主成分等方法),再进行拼接。
决策级融合:让多个独立模型分别做出预测,再通过一个“投票”机制(结合贝叶斯共识阈值)整合所有预测结果,得出最终分类。
验证与应用
在严格的独立校准、验证和测试集上评估模型性能,并将最优模型应用于89个市售红茶样品进行真实性筛查。
03
主要发现
1、单一光谱技术的性能
XRF分析:通过元素指纹(如K、Ca、Mn)区分产地,1D-CNN模型在验证集F1分数达99.0%,但阿萨姆与大吉岭因地理邻近易混淆。
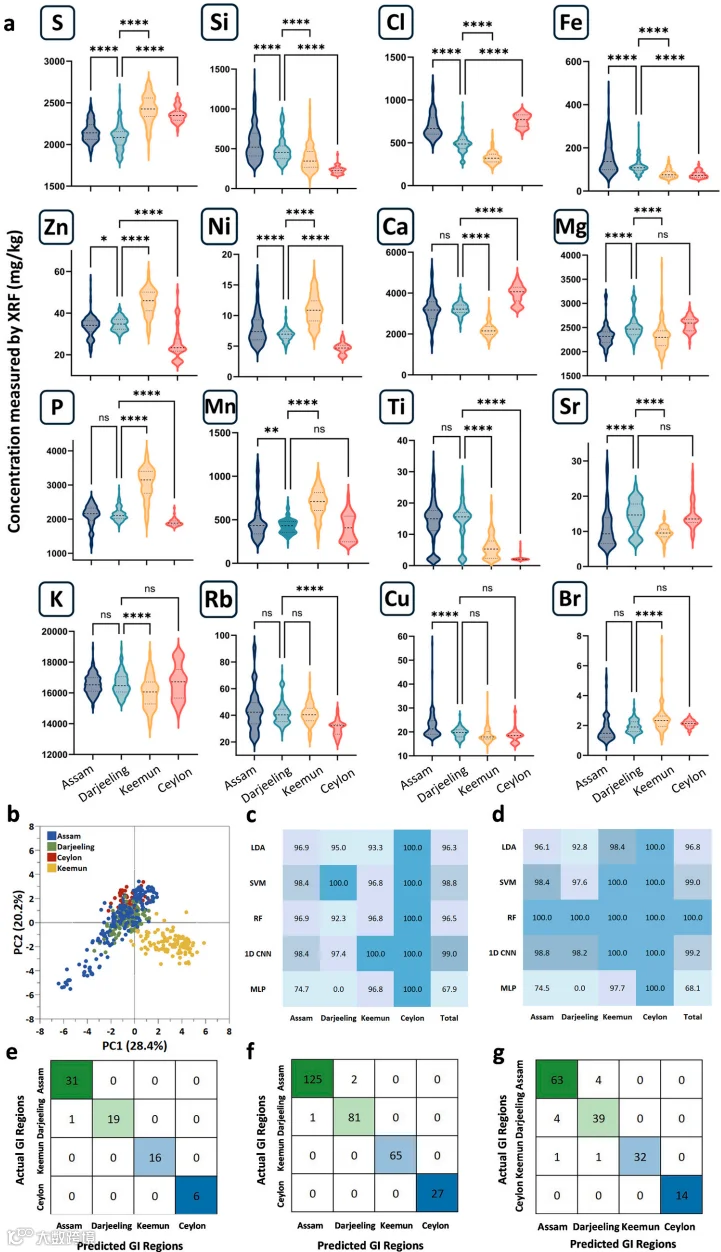
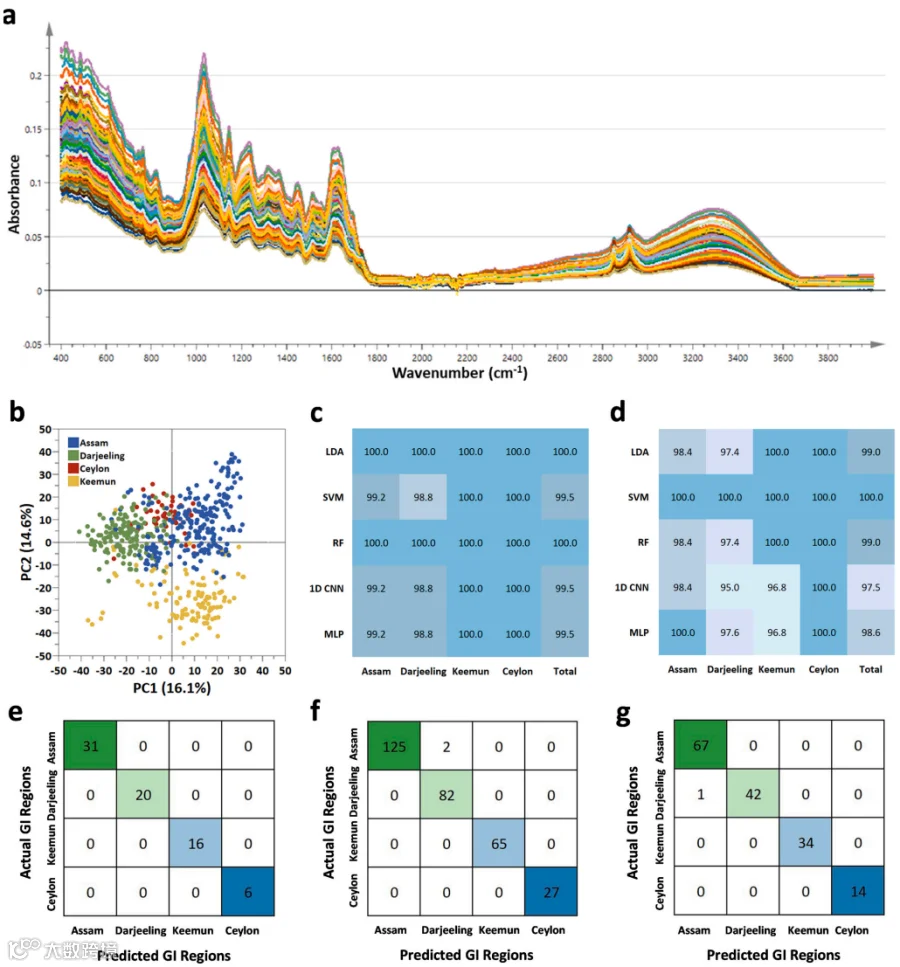
FTIR分析:捕获分子结构信息(如糖类、蛋白质),SVM模型在验证集实现100%准确率。
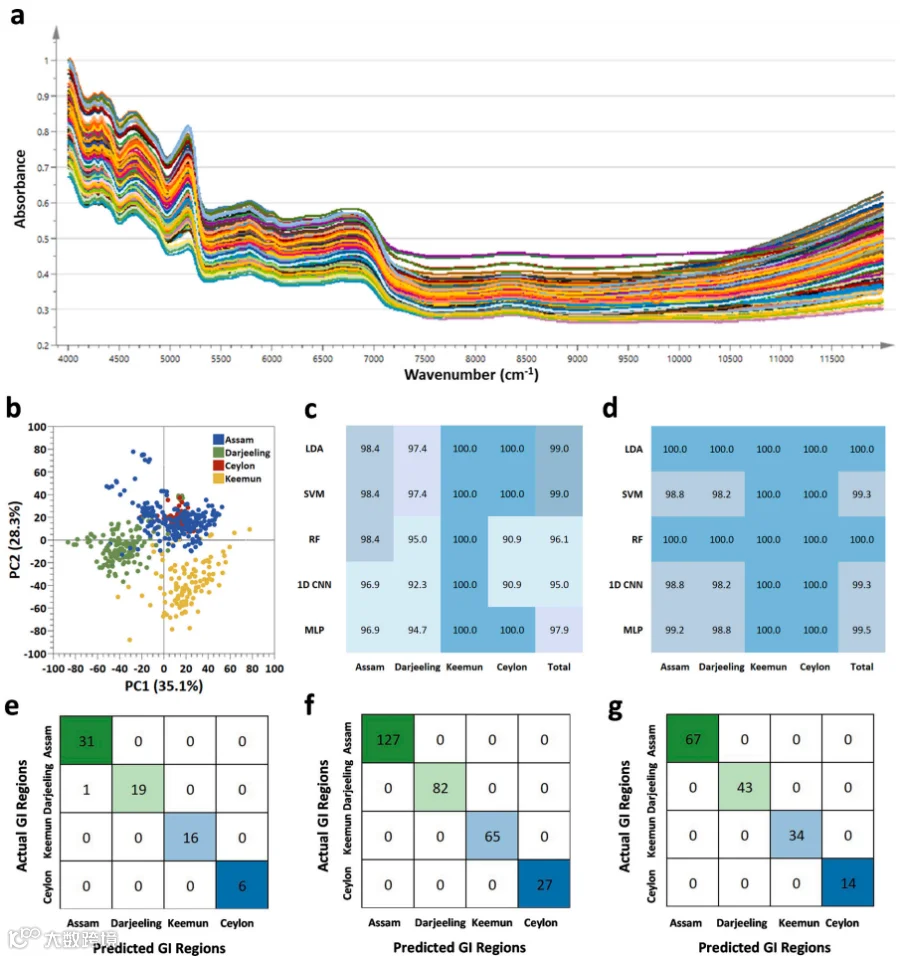
NIR分析:反映官能团振动,LDA模型在测试集达到100% F1分数。
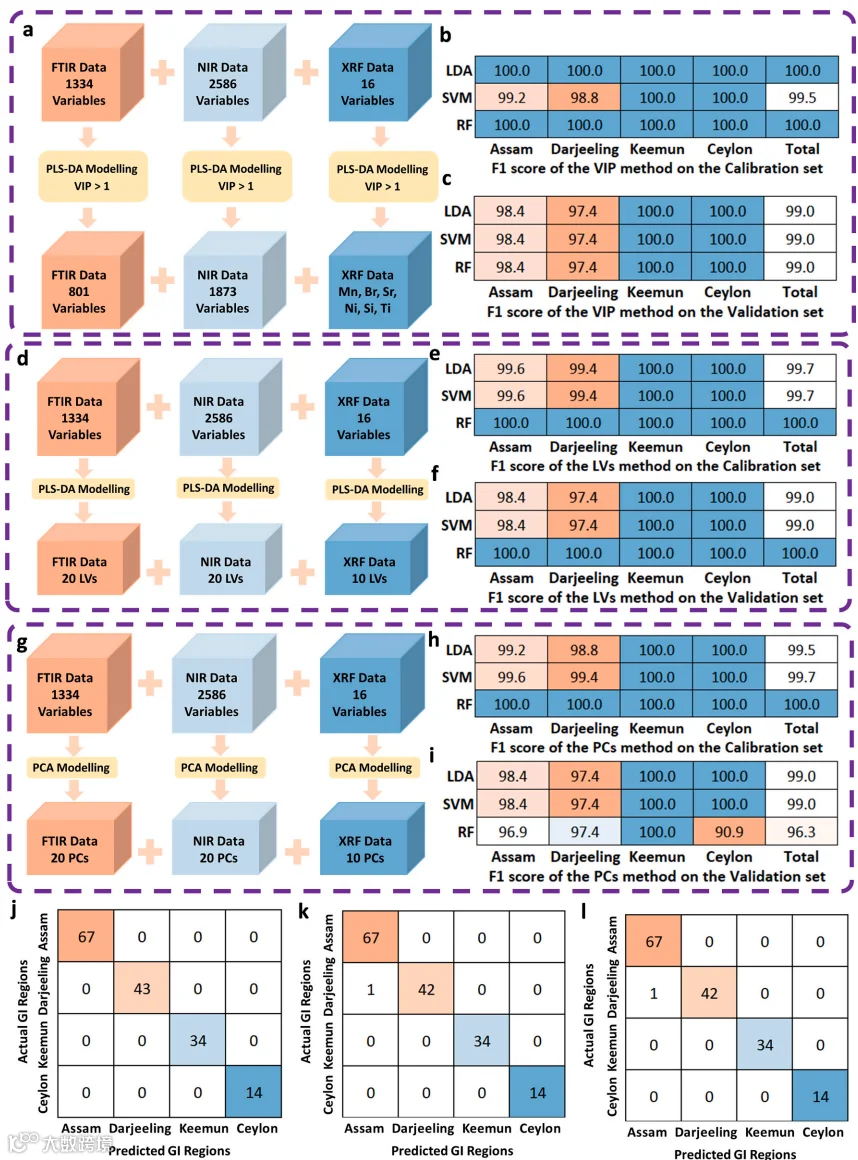
2、数据融合策略的优化效果
信息级融合:提升弱模型性能(如1D-CNN对Keemun的F1分数从96.8%增至100%),但未超越最佳单一模型。
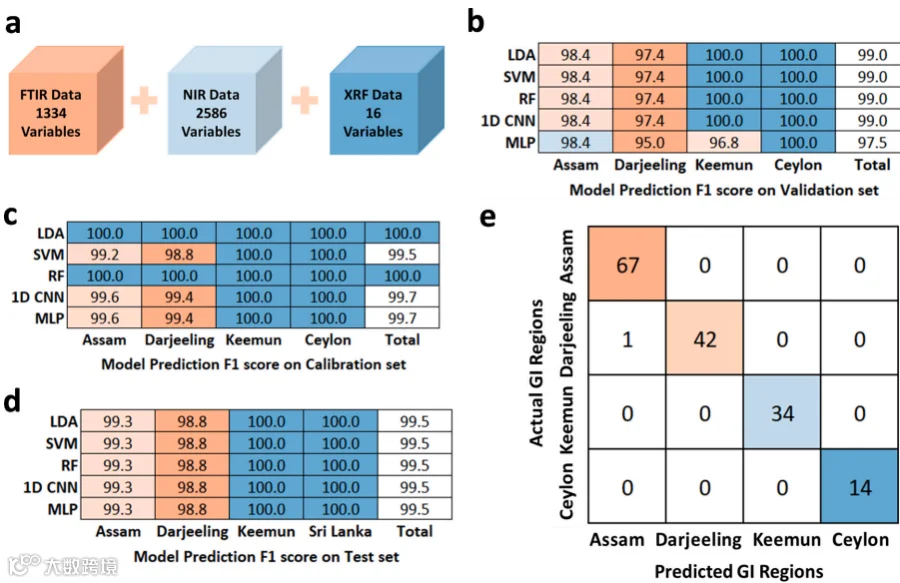
特征级融合:VIP-LDA方法在测试集实现100%准确率,关键变量如FTIR的1659 cm⁻¹(糖环振动)和XRF的Mn元素显著提升区分度。
决策级融合:集成35个模型预测,在校准、验证和测试集均达到100% F1分数,显著增强鲁棒性。
3、实际应用与市场调查
89个市售茶样中,6.74%存在标签不符(如锡兰茶误标为阿萨姆),全部来自在线平台,凸显线上市场欺诈风险。
04
研究意义
本研究成功开发了一套基于机器学习和决策级数据融合的红茶产地鉴别工作流程。
该方法仅需使用FTIR、NIR和XRF这三种快速、低成本、无损的光谱仪,便能以100%的准确率区分四大高价值红茶产区。
在实际市场抽查中,该方法有效识别出了6.74%的标签欺诈产品(均来自线上平台),证明了其强大的实战能力。
这项技术为食品真实性检测提供了一个准确、经济、可推广的解决方案,尤其适合在全球范围内,特别是在发展中国家的常规实验室中部署,以加强消费者保护。
(部分内容来自AI,仅供参考)


「三茶统筹发展」聚焦茶文化、茶产业、茶科技融合发展,旨在服务茶叶全产业链从业者。
我们持续解读政策趋势,追踪科技创新,剖析产业实践,传承茶道精神,让我们携手同行,共同把握时代机遇,推动中国茶业高质量发展。

三茶统筹发展
以情怀为本 与时代同行
以科技为源 与产业共进
