

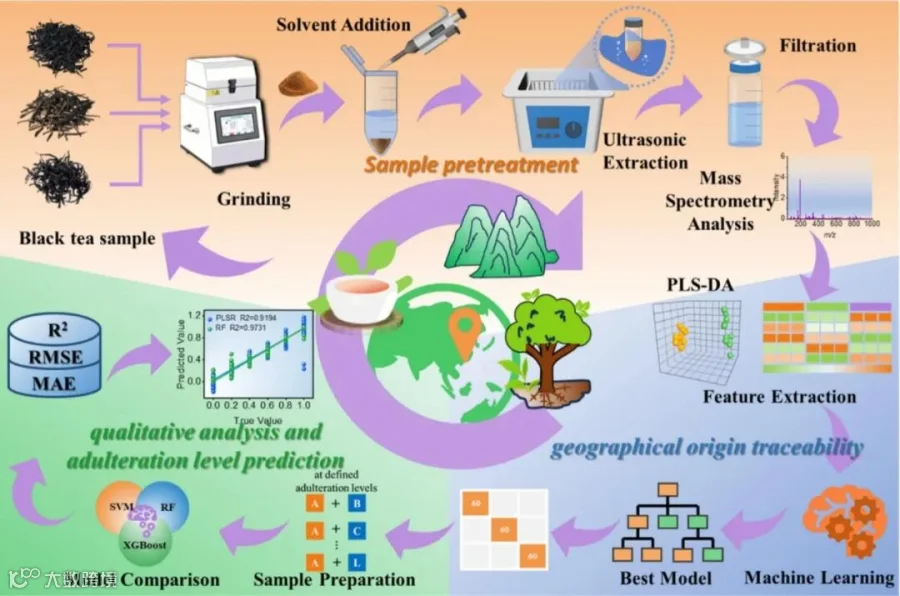
准确的红茶地理溯源和全面的掺假评估对于质量控制和市场监管至关重要,但由于代谢差异细微以及掺假手段复杂,这一任务仍具有挑战性。本研究开发了一个统一的分析框架,将环境质谱技术与先进的数据驱动算法相结合,以快速实现产地溯源、掺假物识别及掺假比例的定量预测。为了快速获取丰富的代谢组学图谱,研究采用了一种细胞破碎辅助溶剂直接提取策略,有效表征了不同地理来源红茶之间的化学变异。此外,系统筛选并验证了用于区域区分的明确生化证据。为了实现准确的地理分类,研究采用随机森林(RF)模型从复杂的代谢组学数据集中提取信息模式,其分类准确率范围在95.00%至100%之间。更重要的是,研究构建了11个标准化的掺假体系以模拟真实的混合场景,并生成用于机器学习建模的代表性数据集。通过集成XGBoost分类模型,实现了可靠的掺假物定性识别,准确率在93.3%至100%之间。此外,利用RF回归模型完成了掺假水平的定量预测,该模型表现出高预测精度和稳定性,均方根误差(RMSE)低于6.78%,决定系数(R²)超过0.9606。总体而言,本研究提出了一个集产地溯源、掺假物识别和掺假定量于一体的综合分析框架,代表了红茶真伪鉴别和监管监督领域的重大进步。
01
研究背景
红茶作为全球消费最广泛的非酒精饮料之一,其地理起源和掺假问题日益突出。由于生长环境(如气候、海拔)和加工工艺的差异,红茶的代谢组成复杂多变,导致传统方法(如色谱质谱联用)在溯源和掺假检测中存在速度慢、成本高、灵敏度低等局限。
环境质谱技术(如PDESI-MS)能够快速获取代谢组学指纹,但需结合机器学习来提取非线性模式,以实现高效分类和预测。
本研究旨在开发一个统一框架,解决红茶质量控制的实时性、准确性和可解释性挑战。
02
主要方法
样品制备与前处理优化
收集来自中国、印度和斯里兰卡12个不同产区的480个红茶样本。
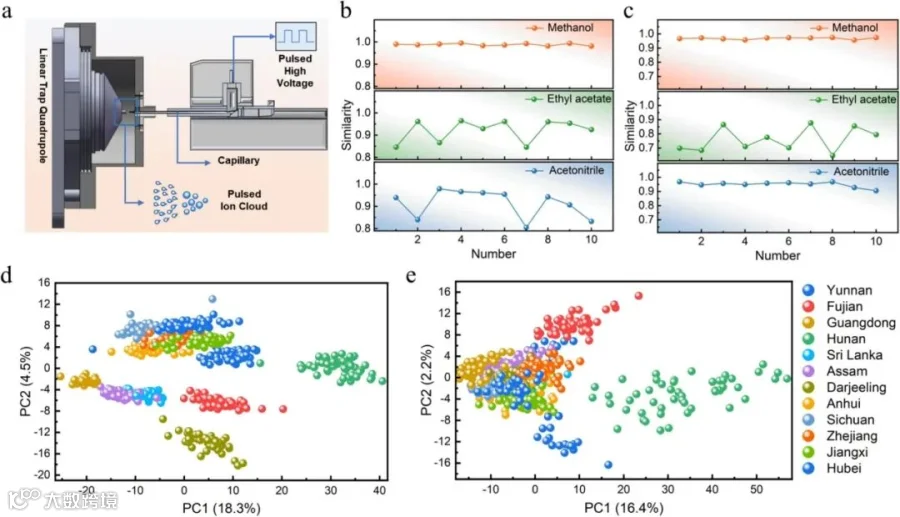
对比了甲醇、乙酸乙酯和乙腈三种溶剂的提取效果,最终确定甲醇为最佳提取溶剂,因其在负离子模式下产生的质谱信号最稳定(余弦相似度>0.98)。
采用细胞破碎辅助超声提取法快速获取代谢物。
数据采集
使用脉冲直流电喷雾电离源(PDESI)耦合线性离子阱质谱仪(LTQ-MS),在1分钟内完成样本分析,无需色谱分离。
数据分析与建模
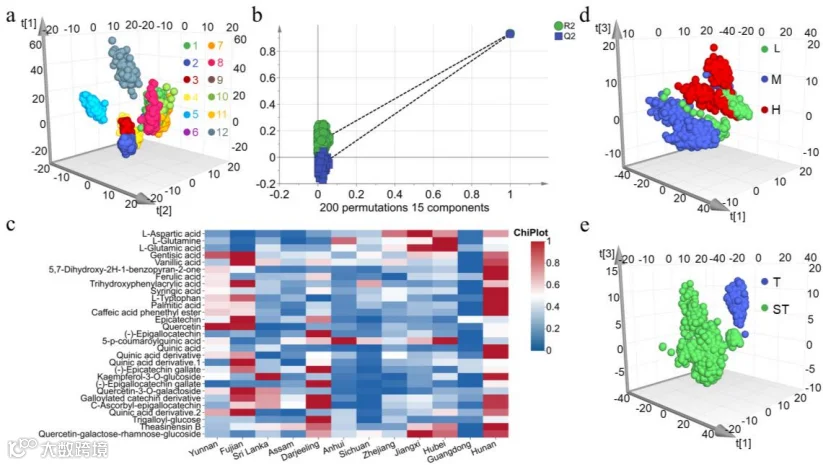
差异代谢物筛选: 利用偏最小二乘判别分析(PLS-DA)结合高分辨质谱(Q-TOF-MS)筛选并鉴定了与产地相关的关键差异代谢物(如L-谷氨酰胺、表儿茶素等)。
地理溯源模型: 比较了朴素贝叶斯(NB)、K近邻(KNN)和随机森林(RF)三种分类算法,利用RF模型进行产地分类。
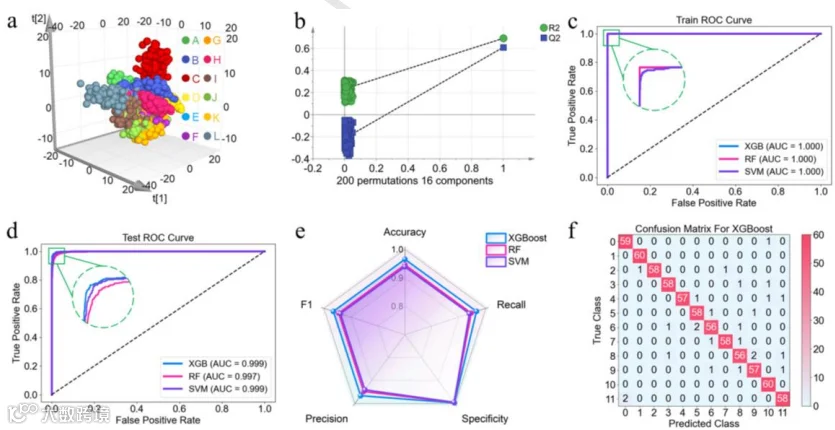
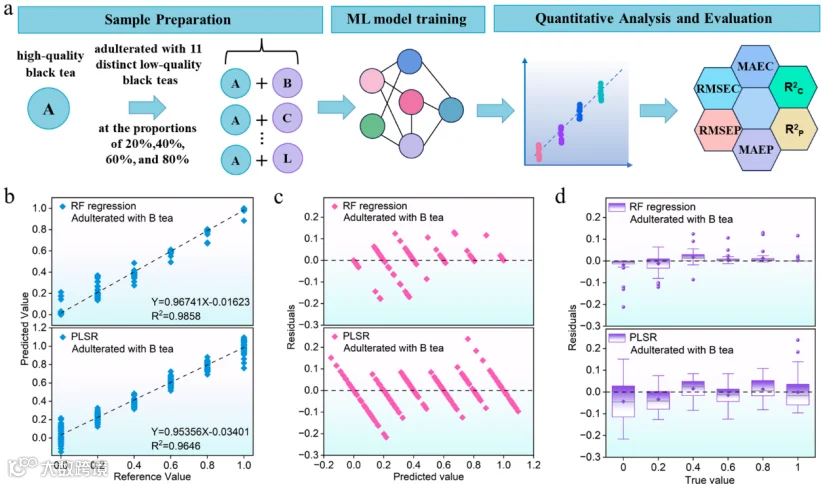
掺假检测模型: 以大吉岭红茶为基准,构建11种掺假体系(掺入不同低质茶,比例20%-80%)。对比了XGBoost、RF和支持向量机(SVM),选用XGBoost进行掺假物定性识别。
掺假定量模型: 比较了RF回归和偏最小二乘回归(PLSR),用于预测掺假比例。
03
主要发现
1、地理溯源准确率高
RF模型在12类红茶起源分类中表现最佳,测试集准确率达98.19%,AUC为0.999。
差异代谢物与海拔、气候带显著相关,如高海拔茶样中槲皮苷含量较高。
2、掺假识别可靠性强
XGBoost模型在11种掺假系统中定性识别准确率达93.3%-100%,显著优于PLS-DA。
模型稳定性高,交叉验证结果一致。
3、定量预测精度优
RF回归模型在掺假比例预测中RMSE<6.78%、R²>0.9606,误差分布集中,优于PLSR模型。
04
研究意义
技术整合:首次将环境质谱与机器学习结合,实现红茶“溯源-定性-定量”全链条分析。
应用价值:为红茶质量监管提供快速(1分钟内分析)、高精度(准确率>95%)的解决方案,可推广至其他食品认证领域。
局限性:需扩大样本量以提升模型泛化能力,未来可结合深度学习进一步优化。
(部分内容来自AI,仅供参考)


「三茶统筹发展」聚焦茶文化、茶产业、茶科技融合发展,旨在服务茶叶全产业链从业者。
我们持续解读政策趋势,追踪科技创新,剖析产业实践,传承茶道精神,让我们携手同行,共同把握时代机遇,推动中国茶业高质量发展。

三茶统筹发展
以情怀为本 与时代同行
以科技为源 与产业共进
