
背景:上下文膨胀的挑战
上一版本通过技能按需加载优化了初始上下文,Agent 仅在启动时载入目录摘要,需使用时再通过 tool_result 注入完整内容。然而,面对读取多文件、执行大量 bash 命令及代码迭代等复杂任务时,messages[] 数组仍迅速膨胀。尤其是工具调用的返回值(如测试套件输出)动辄数万字,几轮交互后便逼近上下文极限,导致 API 报错中断。
单纯扩大上下文窗口并非工程良策,核心痛点在于大量历史信息对当前推理已无价值,却仍在消耗 Token。解决之道不在于扩容,而在于精细化管理。
核心原则:cheap first, expensive last
压缩策略的成本差异显著:字符串替换仅需微秒级,而调用 LLM 生成摘要则耗时秒级且消耗配额。因此,管线设计遵循唯一原则:按成本从低到高排序,优先使用廉价手段,仅在必要时动用昂贵资源。
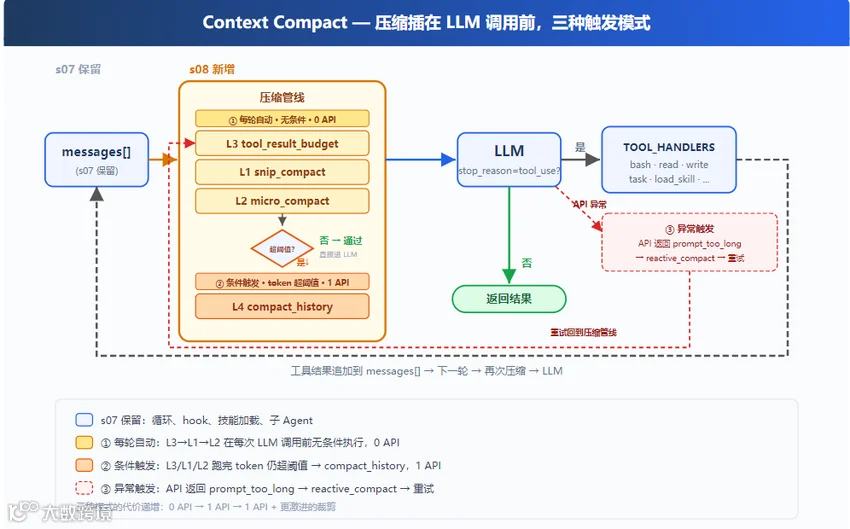
Claude Code 源码中的执行顺序为:tool_result_budget → snip_compact → micro_compact → auto_compact。前三层无需 API 调用,仅当处理后上下文仍超阈值时,才触发第四层的 LLM 处理。
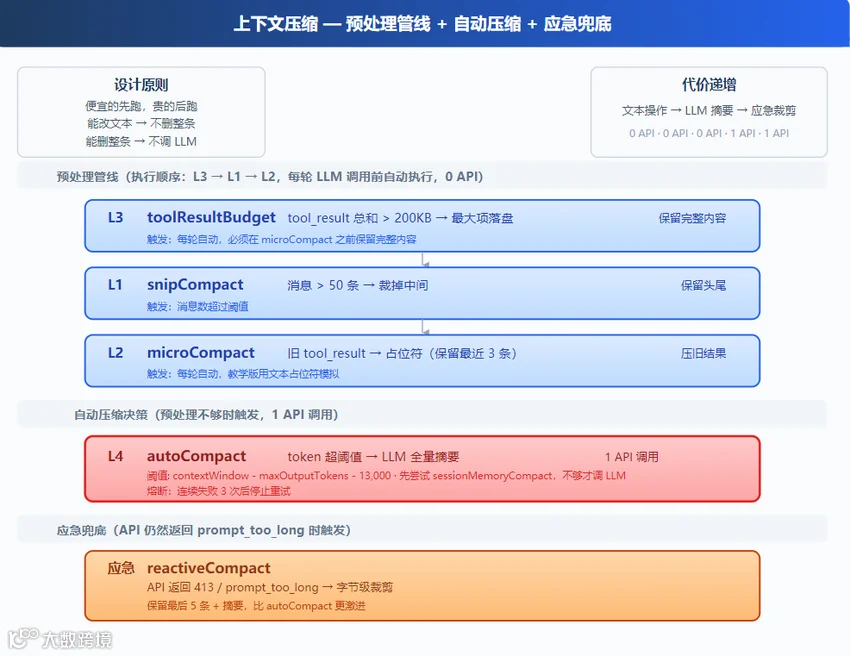
当前版本完整实现了该结构,并增设紧急兜底压缩机制。
L3:tool_result_budget — 大文件直接落盘
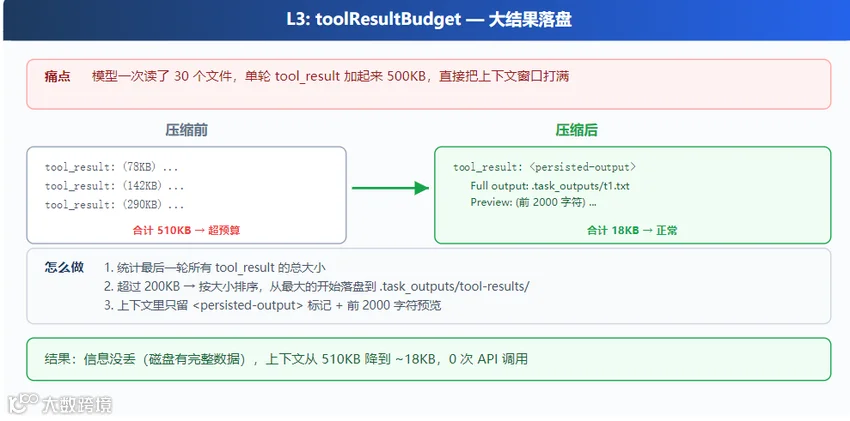
作为管线最先执行的层级,其目标是解决工具返回值导致的上下文暴增。逻辑如下:超过 30KB 的工具结果将完整内容写入磁盘(.task_outputs/tool-results/{tool_use_id}.txt),messages[] 中仅保留文件路径及前 2000 字符预览。若 LLM 需要完整内容,可通过 read_file 工具获取。
PERSIST_THRESHOLD = 30000 # 超过 30KB 的工具结果写磁盘
def persist_large_output(tool_use_id, output):
if len(output) <= PERSIST_THRESHOLD:
return output
TOOL_RESULTS_DIR.mkdir(parents=True, exist_ok=True)
path = TOOL_RESULTS_DIR / f"{tool_use_id}.txt"
if not path.exists():
path.write_text(output)
return (
f"<persisted-output>\n"
f"Full output: {path}\n"
f"Preview:\n{output[:2000]}\n"
f"</persisted-output>"
)此外,tool_result_budget 函数引入预算控制:若最新一批工具结果总大小超过 200KB,则按大小降序排列,从最大的开始依次持久化,直至总量降至预算内。
def tool_result_budget(messages, max_bytes=200_000):
last = messages[-1] if messages else None
if not last or last.get("role") != "user":
return messages
blocks = [
(i, b) for i, b in enumerate(last["content"])
if isinstance(b, dict) and b.get("type") == "tool_result"
]
total = sum(len(str(b.get("content", ""))) for _, b in blocks)
if total <= max_bytes:
return messages
ranked = sorted(blocks, key=lambda p: len(str(p.get("content", ""))), reverse=True)
for _, block in ranked:
if total <= max_bytes:
break
content = str(block.get("content", ""))
if len(content) <= PERSIST_THRESHOLD:
continue
tid = block.get("tool_use_id", "unknown")
block["content"] = persist_large_output(tid, content)
total = sum(len(str(b.get("content", ""))) for _, b in blocks)
return messages此层主要处理单次工具调用产生的数据峰值,在进入后续压缩前先行削峰。
L1:snip_compact — 裁剪中间历史消息
历史消息价值分布不均:首尾包含关键指令与当前推理依据,而中间大量的工具交互往往已过时。snip_compact 策略直接删除中间部分。
def snip_compact(messages, max_messages=50):
if len(messages) <= max_messages:
return messages
keep_head, keep_tail = 3, max_messages - 3
head_end = keep_head
tail_start = len(messages) - keep_tail
# 保证不在 tool_use / tool_result 配对中间断开
if head_end > 0 and _message_has_tool_use(messages[head_end - 1]):
while head_end < len(messages) and _is_tool_result_message(messages[head_end]):
head_end += 1
if (tail_start > 0
and _is_tool_result_message(messages[tail_start])
and _message_has_tool_use(messages[tail_start - 1])):
tail_start -= 1
if head_end >= tail_start:
return messages
snipped = tail_start - head_end
return (
messages[:head_end]
+ [{"role": "user", "content": f"[snipped {snipped} messages]"}]
+ messages[tail_start:]
)需注意 OpenAI 和 Anthropic API 要求 tool_use 与 tool_result 必须成对出现。代码包含两处边界检查以确保不截断配对消息:
- 头部边界:若保留的最后一条头部消息包含 tool_use,则向后扩展直至纳入配对的 tool_result。
- 尾部边界:若尾部第一条是 tool_result 且其前一条被截断,则将 tail_start 前移以保留对应的 tool_use。
当消息数超过 50 条时触发,用占位符替代被删部分,全程零 API 调用。
L2:micro_compact — 旧工具结果替换为占位符

snip_compact 解决了数量问题,但若剩余消息中 tool_result 文本量巨大,总体积仍可能超标。micro_compact 针对此情况,不删消息,仅替换早期工具结果内容。
KEEP_RECENT = 3 # 保留最近 N 个工具结果的完整内容
def micro_compact(messages):
tool_results = collect_tool_results(messages)
if len(tool_results) <= KEEP_RECENT:
return messages
for _, _, block in tool_results[:-KEEP_RECENT]:
if len(block.get("content", "")) > 120:
block["content"] = "[Earlier tool result compacted. Re-run if needed.]"
return messages逻辑为遍历所有 tool_result,对倒数第 3 个之前且内容超过 120 字符的结果,替换为一行占位符。LLM 若需详细信息可重跑工具。此过程为原地修改,无 API 或 IO 开销。
L4:compact_history — LLM 兜底摘要

前三层处理后,若估算上下文仍超 5 万字符,则进入 L4。此层是唯一消耗 API 调用的环节。
CONTEXT_LIMIT = 50000 # 字符数估算阈值
def compact_history(messages):
transcript_path = write_transcript(messages)
print(f"[transcript saved: {transcript_path}]")
summary = summarize_history(messages)
return [{"role": "user", "content": f"[Compacted]\n\n{summary}"}]第一步:保存转录文件
将完整 messages[] 序列化为.jsonl 存入.transcripts/目录,作为信息丢失后的回溯保险。
def write_transcript(messages):
TRANSCRIPT_DIR.mkdir(parents=True, exist_ok=True)
path = TRANSCRIPT_DIR / f"transcript_{int(time.time())}.jsonl"
with path.open("w") as f:
for msg in messages:
f.write(json.dumps(msg, default=str) + "\n")
return path第二步:生成摘要
调用 LLM 生成摘要,Prompt 明确要求保留目标、关键发现、文件变更、剩余工作及用户约束五个维度。
def summarize_history(messages):
conversation = json.dumps(messages, default=str)[:80000]
prompt = (
"Summarize this coding-agent conversation so work can continue.\n"
"Preserve: 1. current goal, 2. key findings/decisions, "
"3. files read/changed, 4. remaining work, 5. user constraints.\n"
"Be compact but concrete.\n\n" + conversation
)
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
# 提取文本内容
...生成摘要后,整个 messages[] 被替换为单条消息,Agent 基于摘要继续推进。
紧急兜底:reactive_compact
由于 estimate_size() 基于字符数估算,与实际 Token 数存在误差,可能出现四层处理后仍报 prompt_too_long 的情况。此时触发紧急兜底逻辑。
MAX_REACTIVE_RETRIES = 1
# agent_loop 里:
try:
response = client.chat.completions.create(...)
reactive_retries = 0
except Exception as e:
if ("prompt_too_long" in str(e).lower()
or "too many tokens" in str(e).lower()
and reactive_retries < MAX_REACTIVE_RETRIES):
print("[reactive compact]")
messages[:] = reactive_compact(messages)
reactive_retries += 1
continue
raisereactive_compact 与 compact_history 的区别在于:它在摘要后拼接最近 5 条消息,确保最新工具调用上下文不被吞掉,且限制最多重试一次。
def reactive_compact(messages):
transcript = write_transcript(messages)
summary = summarize_history(messages)
tail_start = max(0, len(messages) - 5)
# 同样要处理 tool_use/tool_result 配对边界
if (tail_start > 0
and _is_tool_result_message(messages[tail_start])
and _message_has_tool_use(messages[tail_start - 1])):
tail_start -= 1
return [
{"role": "user", "content": f"[Reactive compact]\n\n{summary}"},
*messages[tail_start:]
]agent_loop 集成与主动压缩
压缩管线嵌入 agent_loop 每轮迭代开头,并在 API 调用失败时提供异常捕获。
def agent_loop(messages: list):
reactive_retries = 0
while True:
# 每次调用 LLM 之前,先跑一遍压缩管线
messages[:] = tool_result_budget(messages) # L3:大文件落盘
messages[:] = snip_compact(messages) # L1:裁中间
messages[:] = micro_compact(messages) # L2:压旧结果
# 前三层之后还超阈值,才触发 LLM 摘要
if estimate_size(messages) > CONTEXT_LIMIT:
print("[auto compact]")
messages[:] = compact_history(messages)
try:
response = client.chat.completions.create(...)
reactive_retries = 0
except Exception as e:
# 紧急兜底
if "prompt_too_long" in str(e).lower() and reactive_retries < MAX_REACTIVE_RETRIES:
messages[:] = reactive_compact(messages)
reactive_retries += 1
continue
raise
# 处理工具调用...注意使用 messages[:] = ... 进行原地修改,确保外部引用同步更新。此外,LLM 也可主动调用 compact 工具触发压缩,随后 break 当前轮次,在纯净上下文中重新推理。
# agent_loop 工具调用处理里:
if tool_call.function.name == "compact":
messages[:] = compact_history(messages)
results.append({
"type": "tool_result",
"tool_use_id": tool_call.id,
"content": "[Compacted. Conversation history has been summarized.]"
})
messages.append({"role": "user", "content": results})
break # 结束当前轮,下一轮从压缩后的上下文重新开始整体执行流
完整管线逻辑如下:
messages[]
│
▼
[L3] tool_result_budget ── 大工具结果落盘,保留路径 + 预览
│
▼
[L1] snip_compact ── 消息数 > 50,裁中间,保头尾
│
▼
[L2] micro_compact ── 旧工具结果内容替换占位符
│
▼
estimate_size() > 50000?
├── No ──────────────────────────────────────────────→ LLM 调用
└── Yes → [L4] compact_history (1 API call) ↓
│ prompt_too_long?
▼ │
LLM 调用 ←───────────────────────── No
│
Yes
▼
reactive_compact
(1 API call, 最多 1 次)三层零成本操作前置,一层 LLM 操作中置,一层紧急兜底后置,层层递进。
估算误差与工程思考
当前实现使用字符数粗略估算上下文大小,未接入 tokenizer 精确计数。由于中英文字符到 Token 的转换率不同(中文约 1-2 字符/Token,英文约 4 字符/Token),50000 字符阈值在不同场景下对应的 Token 数差异较大。这也是保留 reactive_compact 兜底的重要原因。
Context 管理是 Agent 工程的核心挑战。盲目扩大窗口只会引入更多噪声并增加成本。真正的解法是主动管理:明确何时压缩、压缩何种内容以及付出何种代价。四层管线结构清晰,但在触发条件与边界处理上蕴含诸多工程细节。未来版本将进一步探索 Agent 在长任务中对全局目标的跟踪能力。