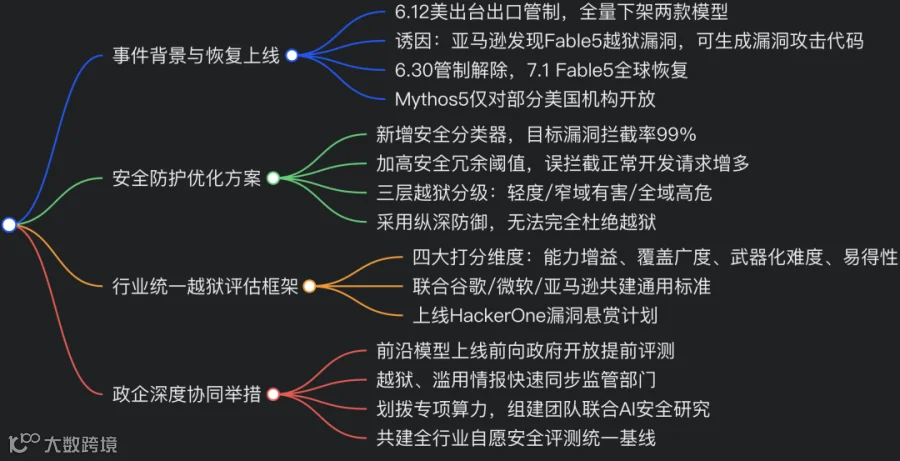
编者摘要:2026 年 6 月 12 日美国对 Anthropic 的 Claude Fable 5、Mythos 5 实施出口管制,因亚马逊研究发现可绕过 Fable5 防护诱导生成漏洞利用代码,官方无实时国籍核验,临时全球下架两款模型。6 月 30 日管制解除,7 月 1 日 Fable5 全球恢复开放,短期附赠免费额度;Mythos5 仅对部分美国机构重开。团队训练全新安全分类器,99% 拦截该越狱手段,但会增加正常代码需求误拦截。公司提出四层维度行业统一越狱分级框架,联合谷歌、微软、亚马逊共建标准,方便厂商、政府统一研判风险。同时深化与美国政府合作,开放模型前置评测、建立情报快速共享通道、投入算力开展联合安全研究。官方承认无法彻底杜绝模型越狱,采用高冗余安全阈值做纵深防御,区分轻度、窄域有害、全域高危三类越狱,降低攻击危害,并上线漏洞悬赏渠道收集安全漏洞。
发布时间:2026 年 6 月 30 日
6 月 12 日(周五),美国政府针对我们两款最新模型 Claude Fable 5 与 Claude Mythos 5 出台出口管制规定。根据新规,我们必须限制境外人士使用两款模型,无论使用者身处美国境内还是海外。由于该管制令即刻生效,且我们当时缺少可靠的实时国籍核验手段,因此我们暂停了全球所有用户对两款模型的访问权限。
截至今日 6 月 30 日,针对 Fable 5 和 Mythos 5 的出口管制已解除。
Fable 5 将于明日(7 月 1 日,周三)面向全球用户开放,可在 Claude 平台、Claude.ai、Claude 代码助手(Claude Code)以及 Claude 协同工具(Claude Cowork)中使用。付费版(Pro、Max、团队版)及指定企业套餐用户,在 7 月 7 日前可免费使用 Fable 5,额度为每周总用量上限的 50%;7 月 7 日后需消耗用量积分方可调用。我们也会尽快在亚马逊云、谷歌云与微软 Foundry 平台恢复该模型访问权限。
6 月 26 日我们已获美国政府许可,重新向一批美国本土机构开放 Mythos 5 使用权限。我们正持续与政府沟通,争取让更多国内外 “玻璃翼计划” 合作方解锁该模型。
本文后续将从四大板块,详细说明事件经过与最新进展:
-
事件时间线与安全防护机制升级:梳理本次出口管制指令的来龙去脉,介绍我们新增的安全防护方案; -
网络安全防护整体思路:详解我们如何借助安全分类器,识别模型被用于高危网络攻击的潜在场景; -
行业通用评估框架:尽管本次事件已妥善解决,但也暴露出全行业缺少统一标准,用以评判、修复 AI 模型 “越狱”(绕过模型安全防护机制)漏洞。一套统一的越狱漏洞严重程度判定标准,能够帮助 AI 开发者分级处置新漏洞、更安全地推出高性能大模型,并与政府、行业伙伴统一风险口径。我们已联合亚马逊、微软、谷歌及其他玻璃翼计划合作方搭建这套框架,下文将完整说明; -
深化政企协同机制:我们将与美国政府在模型上线前测试、情报互通、安全联合研究等层面深化合作,最后一部分将介绍相关举措。
一、事件时间线与安全防护升级
我们于 6 月 9 日(周二)正式发布 Fable 5 与 Mythos 5。两款模型底层基座完全一致,但 Fable 5 搭载了高强度安全防护机制,适配通用场景;Mythos 5 防护限制更少,仅对少数受信任的 “玻璃翼计划” 合作方开放,仅限防御性网络安全工作使用。
6 月 12 日出口管制令出台的背景,是美国政府收到一份亚马逊研究团队的报告:研究人员找到了绕过 Fable 5 安全限制的提示词方法,可诱导模型批量识别软件漏洞,其中一例还生成了利用该漏洞实施攻击的代码。过去两周,我们联合美国政府、亚马逊等多方机构,完整复盘了这份报告与相关测试证据。
我方复测证实:多款性能低于 Fable 5 的主流模型(包括 Claude Opus 4.8、GPT-5.5、Kimi K2.7),均能像报告中 Fable 5 一样识别同类漏洞;针对报告中那套漏洞利用演示代码,所有参与测试模型均可生成完全一致的攻击示例,涵盖 Claude Haiku 4.5、Sonnet 4.6、Opus 4.6/4.7/4.8、GPT-5.4/5.5、Kimi K2.7。
关键结论:这份报告披露的绕过手段,并未解锁 Mythos 级别的独有网络攻击能力。该场景仅属于 Fable 5 安全防护的边界灰色地带 —— 出于极致审慎,我们会拦截一批本身风险极低、但存在微小滥用可能的请求,报告中的手段只是突破了其中一类仅用于常规网络防御的限制。
即便如此,我们仍第一时间针对该绕过漏洞完成修复。在政府部门协同指导下,我们训练了全新安全分类器,专门拦截报告中提到的诱导逻辑。若用户向 Fable 5 发起的请求被拦截,系统会自动切换至 Opus 4.8 模型处理,并向用户发送拦截通知。
这套新分类器可拦截报告中提及的漏洞诱导手段,拦截成功率超 99%;极少数漏拦场景下,模型输出信息也不足以支撑攻击者实施有效攻击。下文会说明:我们的安全防护机制并非要阻断所有低风险常规网络防御功能,仅拦截具备明确危害性的操作。美国商务部 AI 标准与创新中心(CAISI)研究人员对新旧两套防护体系完成独立测试,确认新版防护强度极高。
但新版分类器存在一定副作用:日常代码编写、调试等正常需求更容易被误拦截。和所有安全防护工具一样,我们会持续迭代优化分类器,精准区分恶意滥用与合法开发需求,降低误判率。
二、我们的网络安全防护设计思路
Claude Mythos 5 识别、利用软件漏洞的能力,远超市面所有其他大模型,甚至优于绝大多数资深人类安全专家。极强的网络攻防能力,也让它极易被不法分子滥用发起网络攻击。
而 Claude Fable 5 不存在这类独有攻击性能力 —— 上线前我们为它配置了公司史上最严苛的全套安全防护。发布前一个月,我们从内部各团队抽调人力,将安全防护研发团队规模扩充一倍。
Fable 5 采用多层纵深防御安全机制:单一防护手段无法实现完美拦截,但多层叠加可大幅抬高滥用门槛。防护分为两类:一类通过模型训练,让 AI 主动拒绝高危请求;另一类事后复盘、识别滥用行为规律。
其中核心防护组件为安全分类器:一类轻量化自动化 AI 系统,在对话过程中实时识别两类风险 —— 用户要求模型执行高危网络安全操作、模型即将输出有害内容;一旦触发风险,分类器会直接阻断模型应答。分类器的核心目标,是杜绝模型生成具备独特高危破坏力的内容。
和所有安全工具一样,分类器存在缺陷:既可能漏判危险内容,也会被人为 “越狱”—— 用户通过特殊提示词欺骗分类器,诱导模型输出本应被拦截的有害信息。
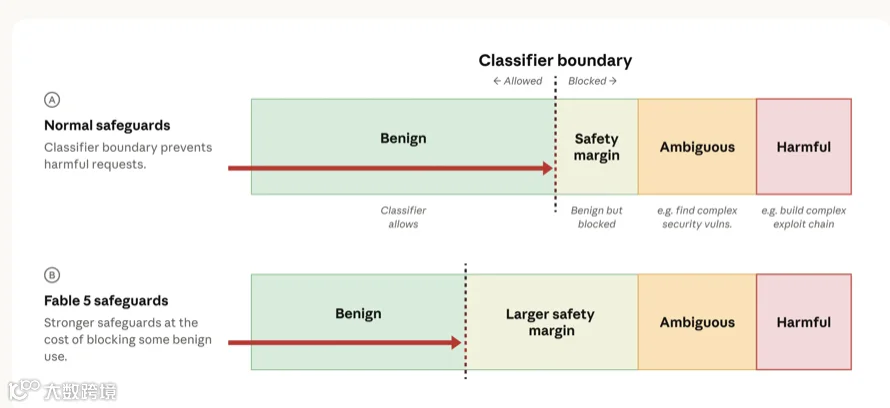
为此,我们刻意为分类器设置了较宽的安全冗余阈值:即便请求大概率无害,只要存在极小滥用风险,就会直接拦截(见下文示意图 A 栏)。对用户而言,直观感受就是部分合理、无危害的正常提问会被拒绝。
针对 Fable 5,我们将安全冗余阈值调到历代模型最高一档(示意图 B 栏),这意味着更多无害请求会被拦截。我们清楚高频误判会影响用户体验,但为保障模型其余通用功能安全开放,做出了这项取舍。
网络安全分类器原理示意图说明
用户提交提问后,分类器会判定两种结果:无害(放行)、存在潜在风险(拦截)。所有模糊请求(明确涉及网络安全、但可能用于防御,例如查询漏洞)与明确高危请求(例如生成一套链式攻击漏洞)都会被拦截。如图 A 栏所示,我们额外设置安全冗余区间:但凡存在微小危害可能性、即便大概率无害的请求,一律拦截,以此确保高危请求 100% 拦截。Fable 5 对应 B 栏,冗余区间进一步扩大,误拦截更多正常请求,但漏放真正高危内容的概率无限降低。注:Vulns = 软件漏洞
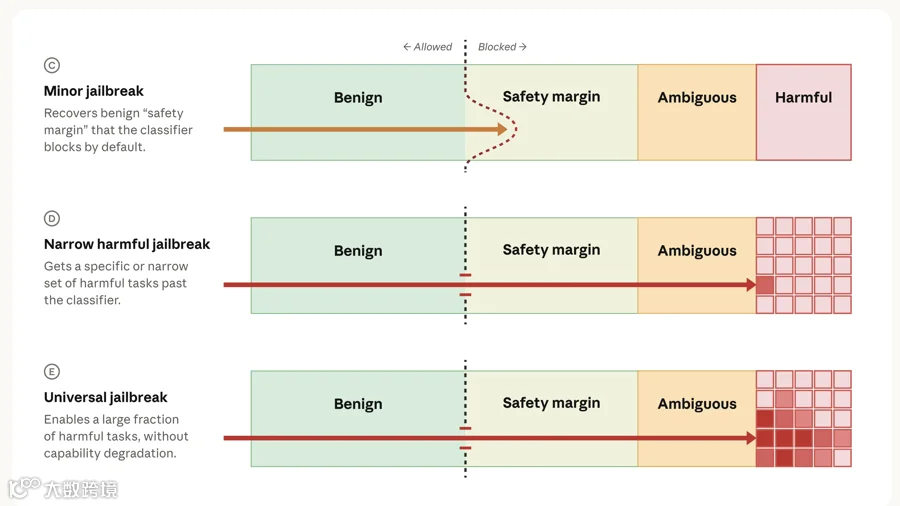
安全冗余机制同样能削弱越狱攻击效果。绝大多数越狱手段覆盖范围极窄,仅能解锁某一项特定功能,无法触及核心高危能力。攻击者即便通过轻度越狱突破分类器,也仅能触及安全冗余区间或模糊风险区,无法获取我们重点封堵的攻击性能力(示意图 C 栏)。目前公开披露的 Fable 5 越狱漏洞,均属于这类轻度漏洞。
越狱漏洞按严重程度分为三档:
-
轻度越狱(C 栏):绕过分类器,但仅触及安全冗余区间,几乎无攻击风险; -
窄域有害越狱(D 栏):突破防护、解锁单一特定高危操作,危害中等偏低,攻击手段受限; -
全域通用越狱(E 栏):一套提示词即可解锁全类别高危攻击功能,风险最高。
正如我们发布 Fable 5 时所述:不存在完全免疫越狱攻击的 AI 模型。我们预计后续仍会持续发现各类越狱漏洞,风险层级参差不齐,其中轻度漏洞占绝大多数、窄域有害漏洞少量存在;截至本文发布,尚未出现针对 Fable 5 的全域通用越狱,但专业安全团队仍在持续开展红蓝对抗渗透测试。我们的核心目标是:我方与合作安全机构率先发现重大越狱漏洞,并在不法分子利用前完成修复。
这套保守防护设计,让绝大多数越狱手段无法解锁高危攻击能力。分类器大幅抬高了越狱攻击的人力、技术门槛;即便攻击者成功越狱,多层纵深防御仍能进一步降低危害。针对层出不穷的新型越狱提示词,我们会持续迭代更新分类器规则。
三、统一行业越狱漏洞评估框架
当前 AI 行业尚未形成客观、统一的标准,用以界定越狱漏洞严重程度。每当新型越狱手段曝光,全行业都会陷入标准混乱:开发者缺少优先级判定依据,政府监管机构也无统一标尺判断是否需要介入管控。
未来数月,具备强网络攻防等高危能力的大模型会批量研发、落地、上线,该矛盾会愈发突出。一套通用越狱评估标准,既能帮助各大厂商安全发布新模型,也能让用户安心使用模型先进能力。
因此我们联合亚马逊、微软、谷歌及玻璃翼计划全体合作方,起草一套行业通用框架,统一越狱漏洞分级标准与厂商处置流程,并欢迎全行业模型厂商参与共建。
当前草案从四大维度对越狱漏洞打分,前两项衡量攻击者可获取的能力收益,后两项衡量漏洞转化为现实攻击的速度与门槛:
- 能力增益度
越狱带来的能力是否远超现有工具?若市面上已有普通工具 / 低配 AI 可实现同等效果,得分低;若该漏洞能大幅提升专业攻击者效率,得分高。 - 能力覆盖广度
同一套越狱提示词可实现多少种不同攻击?仅针对单一攻击目标得分低;一套提示词适配多种攻击场景得分高。 - 武器化难度
将漏洞转化为真实攻击需要多少专业操作?需大量专业提示词、反复调试得分低;单条提示词、一两次尝试即可成功得分高。 - 传播易得性
普通攻击者获取这套越狱手段的门槛?需要深厚专业知识得分低;全网公开、随手可查得分高。
我们计划依托这套分级框架,标准化处置各类新曝光越狱漏洞。针对最高风险等级漏洞(例如已被用于攻击电网、银行等关键基础设施、造成严重破坏),一经定级将立刻上线临时防护措施。同时我们将组建 7×24 小时专项团队,全天候监控各类漏洞提交通道。
任何打分框架都无法做到绝对完美,但统一标准能让全行业、监管机构清晰同步漏洞风险等级。该框架仍在完善阶段,我们会吸纳各合作方反馈持续迭代优化。
后续我们会公开框架完整细则;同步上线 HackerOne 漏洞悬赏计划,安全研究员可提交 Fable 5(上线后)相关越狱漏洞供我们核验。
四、携手美国政府共建前沿 AI 安全体系
过去十周,我们深度参与美国政府《促进先进人工智能创新与安全行政令》(6 月 2 日发布)配套政策制定,对接机构包括国家网络总监办公室、科学技术政策办公室、财政部、商务部(含 CAISI)及各国家安全部门。
我们将持续深化政企协作,此前我们已与美国政府开展近两年模型上线前联合测试评估,下文承诺均基于既有合作,并配套全新扩容举措,待行业越狱评估框架定稿后落地:
- 上线前政府专属评测权限
针对在国家安全相关领域实现能力跨越式突破的前沿模型,我们向指定政府机构开放提前完整测试权限,同步提供全套安全防护机制。官方评测团队可在模型公开发布前独立验证模型能力、测试安全围栏;测试周期内,我方专职技术人员全程配合政府评测。 - 安全漏洞情报快速互通
一旦发现重大越狱漏洞或大规模滥用行为,我们第一时间排查分级并同步对应政府部门;同步交付修复后的新版防护机制,供官方独立复测。相关威胁情报会在对外发布前提前报送政府,并接入行政令 2 (d) 条款设立的跨部门网络安全漏洞共享中心。 - 专项联合安全研究资源投入
大幅扩容政企联合 AI 安全研究项目,设立专属团队对接政府安全重点课题,划拨专项算力资源支撑官方测试与科研,并开放我方安全红蓝对抗技术积累,推动全球 AI 评测技术发展。 - 共建全行业统一安全基线
联合政府与同业厂商,制定前沿大模型厂商自愿遵守的统一安全评测标准,向监管机构开放自研评测工具、流程与最佳实践,供全行业落地参考。
我们希望这套政企协同机制,搭配行业通用越狱评估框架,成为全行业标准化管理体系基础,也能为全球 AI 风险协同治理提供范本。
相关规则最终需落地为完善监管法案,平等适用于所有前沿大模型开发企业。政府参与模型上线评估需建立长期、透明的标准化流程,保障网络防御从业者等群体稳定使用高性能 AI 工具。
我们期待按上述方向持续深化政企安全合作。同时感谢所有用户在本次服务中断期间的包容,也致谢全程协同、推动 Fable 5 与 Mythos 5 恢复上线的科研人员与行业合作伙伴。
脚注
-
标准企业版席位不含 Fable 5 免费额度,调用全部消耗用量积分;若未开通积分功能,企业用户将无法使用 Fable 5。高端企业席位用户 7 月 7 日前可免费调用,消耗席位基础周额度、无额外扣费;7 月 7 日后团队需开通积分方可继续使用,未开通则无法访问。 -
业内有时用 “绕过” 替代 “越狱”,本文二者视为同义;正文统一使用 “越狱”,一是行业通用术语,二是与我方过往技术文档用词保持一致。 -
类比参考:不存在完全无漏洞的软件(但软件漏洞的挖掘、修复流程,通常比大模型越狱漏洞更简单)。 -
网络安全领域已有成熟通用分级标准,例如通用漏洞评分系统(CVSS),用于统一判定软件漏洞严重等级。