
编者摘要:本文是 NVIDIA 与华盛顿大学 2026 年发布的桌面操作智能体(CUA)数据集技术报告,针对现有人工数据集 AgentNet 微调模型产生负迁移的关键问题,推出大规模合成数据集 ProCUA-SFT。该数据集包含 93K 条合成轨迹、310 万步级微调样本,覆盖 2484 类软件组合,统一使用 Kimi-K2.5 视觉大模型完成任务生成、可行性校验与轨迹执行。
流水线有四大创新:一是加入前置条件闭环校验,过滤不存在文件、软件等无效任务;二是基于真实表格、开源 PPT、OSWorld 环境初始化虚拟机,支撑复杂跨应用任务;三是单模型统一规划与执行,消除能力断层,模型可自主判定任务成败;四是采用步前缀扩展,每条轨迹生成多组训练样本,训练与推理上下文格式完全匹配。
工程上采用推理与虚拟机解耦架构,支持本地 KVM 与云端 NVCF 双部署,可并行大规模采集数据。实验显示,UI-TARS 7B 经该数据集微调后,OSWorld 任务成功率达 45%,较原始基线提升 18.7 个百分点,远超 AgentNet 训练后的 8%-10%。对比发现该数据集轨迹更长、跨软件样本更丰富、键盘操作占比更高;消融实验证明软件组合多样性是提升智能体性能的核心。
论文还通过界面状态图分析轨迹复杂度,并补充稀有多软件样本优化长尾分布。相比现有人工与合成数据集,ProCUA-SFT 具备可行性校验、真实业务场景、超大规模三大独有优势,部分数据已用于 Nemotron 3 Nano Omni 模型,后续将拓展多系统、强化复杂任务生成。

附录:ProCUA-SFT 技术报告解读
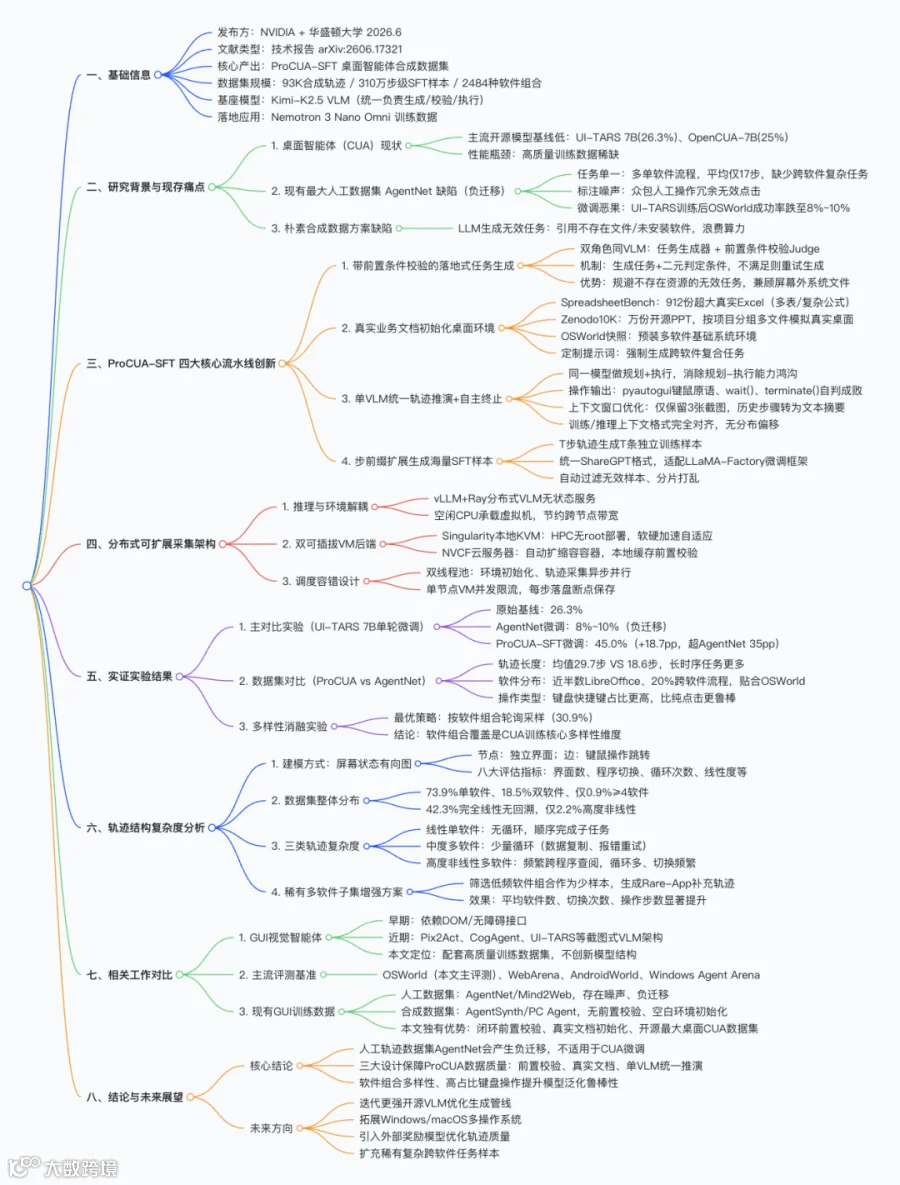
一、基础概述
本文由 NVIDIA、华盛顿大学团队于 2026 年 6 月发布,核心产出ProCUA-SFT—— 面向桌面计算机智能体(CUA,Computer-use Agents)的大规模全自动合成监督微调数据集,已开源上传至 Hugging Face,部分数据用于 NVIDIA Nemotron 3 Nano Omni 多模态模型,提升其桌面操作能力。现有开源桌面智能体(UI-TARS 7B、OpenCUA-7B)在 OSWorld 基准上基线性能仅 26.3%、25.0%,训练数据是性能瓶颈;此前最大公开人工轨迹数据集 AgentNet 存在负迁移问题:UI-TARS 7B 在 AgentNet 微调后 OSWorld 成功率从 26.3% 暴跌至 8%–10%,本文提出全自动合成数据流水线解决该痛点。
核心指标
-
数据集规模:93K 条完整合成轨迹,拆分得到310 万条步级 SFT 训练样本,覆盖 2484 种软件组合; -
模型效果:UI-TARS 7B 单轮微调后 OSWorld 成功率达 45.0%,较基线提升 18.7 个百分点,超 AgentNet 训练模型 35 个百分点; -
统一基座:整套管线仅使用单一视觉大模型 Kimi-K2.5,同时承担任务生成、前置条件校验、轨迹执行三大角色,消除规划器与执行器能力鸿沟。
二、现有方案痛点(AgentNet 人工数据集缺陷)
AgentNet 含 22.5 万人工标注跨系统轨迹,却引发负迁移,根源三点:
- 任务多样性不足:
绝大多数为单软件流程,单轨迹平均仅 17 步,缺少跨软件复杂推理任务; - 标注噪声:
众包人工操作存在大量冗余、无效点击; - 交互方式脆弱:
63% 操作为像素级点击,易受界面分辨率、窗口偏移影响,泛化差。
朴素合成数据方案同样存在缺陷:LLM 生成任务经常引用不存在文件 / 未安装软件,大量浪费虚拟机推演算力。
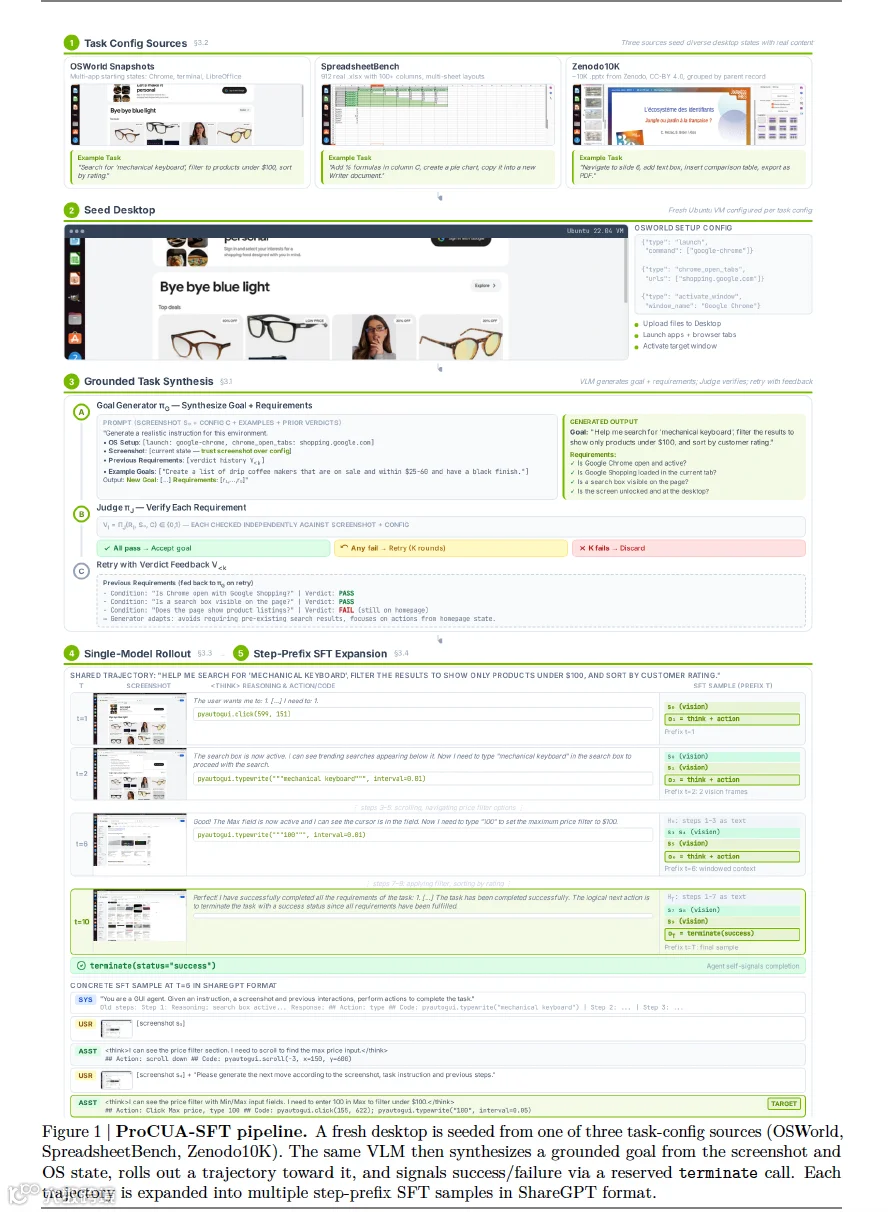
三、ProCUA-SFT 四大核心管线设计
整套数据生成流水线基于 KVM/NVCF 异构虚拟机集群,从桌面环境初始化到样本导出全自动化,四大关键创新:
1. 带前置条件校验的落地式任务生成(解决无效任务)
将任务生成设计为生成 + 校验闭环:
-
同一 VLM(Kimi-K2.5)生成目标任务 + 一组可二元判定前置条件(如 “桌面存在 Q3.xlsx”“LibreOffice Calc 已安装”); -
Judge 模块依据桌面截图、系统配置逐条校验前置条件,全部通过才执行推演;任意条件不满足则携带校验失败反馈重新生成任务,最多重试 K 轮; -
同时读取系统底层配置,识别未显示在屏幕但真实存在的文件 / 程序,拓宽任务范围。
2. 真实复杂业务文档初始化桌面环境(提升任务难度)
摒弃空白软件模板,用三类真实授权数据初始化虚拟机桌面,支撑多软件联动复杂任务:
- Zenodo10K:
约 1 万份 CC-BY 4.0 开源 PPT,按项目分组批量导入多份关联文档,模拟真实多文件桌面场景; - OSWorld 官方快照:
多软件预装基础环境,覆盖浏览器、终端、LibreOffice 全家桶。
基于不同数据源定制专属任务生成提示词,强制生成跨工作表汇总、网页查数写入幻灯片、文件导出等多步骤复合任务。
3. 单 VLM 统一推演执行,智能终止机制
任务确认后,同一 Kimi-K2.5 模型完整生成整条操作轨迹:
-
输入当前截图、全局任务、历史窗口上下文,输出思维链 + 鼠标 / 键盘操作代码(pyautogui 原语); -
内置 wait()等待加载、terminate(状态,结果)终止函数,模型自主判断任务成功 / 失败,无需外部评估器; -
上下文窗口优化:仅保留最近 3 张截图作为视觉输入,更早步骤转为文本摘要,训练与推理上下文格式完全对齐,无训练 - 测试分布偏移。
4. 步前缀扩展生成海量 SFT 样本(最大化轨迹监督价值)
单条 T 步轨迹不只用最终状态做样本,而是每一步都生成一条独立训练样本:
-
样本包含全局任务、分段视觉截图、历史操作文本摘要; -
统一输出 ShareGPT 对话格式,图片用<image>占位符嵌入,适配 LLaMA-Factory 等主流微调框架; -
自动过滤截图缺失的无效样本,分片打乱后用于模型训练。
四、分布式可扩展数据采集架构
解决大规模并行运行桌面虚拟机的算力瓶颈,推理与环境解耦:
- 模型推理侧:
vLLM+Ray 分布式 VLM 服务,GPU 张量并行,无状态 HTTP 接口供所有采集节点调用;空闲 CPU 资源运行虚拟机,节省跨节点带宽; - 双虚拟机后端(可插拔切换)
-
Singularity 本地 KVM:HPC 无 root 权限运行,支持硬件加速 / 软件模拟双模式; -
NVCF 无服务器云:本地缓存文件后调度 NVIDIA 云容器,自动扩缩容; - 异步调度:
虚拟机初始化、轨迹采集双线程池,单节点 VM 并发信号量限流,每步轨迹落盘断点保存,节点故障仅损失单条未完成轨迹。
五、实证实验结果
1. 主实验:AgentNet vs ProCUA-SFT 微调 UI-TARS 7B
统一训练参数:序列长度 32k、批次 512、学习率 2e-5、余弦衰减、权重衰减 0.1,单轮 epoch 训练:
-
原始 UI-TARS 基线:OSWorld 成功率 26.3%; -
AgentNet 微调:仅 8%–10%,性能大幅退化(负迁移); -
ProCUA-SFT 微调:45.0%,大幅超越基线与人工数据集。
2. 数据集统计对比(ProCUA vs AgentNet)
- 轨迹长度:
ProCUA 平均 29.7 步,AgentNet 仅 18.6 步,长时序复杂任务占比更高; - 软件分布:
ProCUA 近半数轨迹基于 LibreOffice 套件,20% 为跨软件流程,完美匹配 OSWorld 评测场景;AgentNet 大量 Windows/Mac 数据缺少软件标签; - 操作类型:
ProCUA 键盘输入、快捷键占比更高(59%),AgentNet 63% 为像素点击,键盘操作鲁棒性更强。
3. 数据多样性消融实验
固定训练预算对比四种数据采样策略,按软件组合轮询采样效果最优(30.9%),高于基线 26.3%;按操作类型、组合嵌套采样性能反而下降,证明:软件组合覆盖度是桌面智能体训练最关键的多样性维度。
六、轨迹图结构深度分析
将每条轨迹建模为屏幕状态有向图(节点 = 界面状态,边 = 操作跳转),提取 8 项复杂度指标:界面数量、切换次数、循环回溯、线性度、界面重访率等。
-
数据集整体分布:73.9% 单软件轨迹,18.5% 双软件,仅 0.9%≥4 软件;42.3% 轨迹完全线性无回溯,仅 2.2% 高度非线性; -
轨迹复杂度分层: -
纯线性单软件:无循环、顺序完成子任务; -
中度多软件:少量循环,多为数据跨软件复制、弹窗报错重试; -
高度非线性多软件:频繁跨程序来回查阅数据,循环多、界面切换频繁; -
稀有多软件子集增强方案:识别出现频次≤3 次的长尾软件组合,作为少样本提示生成新轨迹(ProCUA+Rare-App 子集)。该子集平均使用 3.3 款软件、4.8 次程序切换,操作步数提升至 35.2 步,弥补原数据集复杂跨软件样本稀缺问题。
七、相关工作对比
1. GUI 视觉智能体
早期依赖 DOM / 无障碍接口;近年 Pix2Act、CogAgent、OS-Atlas、UI-TARS 等基于截图 + VLM;ProCUA-SFT 不创新模型架构,而是提供配套高质量训练数据集。
2. 评测基准
OSWorld(本文主评测,多系统桌面真实任务)、WebArena、AndroidWorld、Windows Agent Arena 等。
3. 现有 GUI 训练数据
-
人工标注:AgentNet、Mind2Web、AITW,存在标注噪声、多样性差、负迁移; -
合成轨迹:AgentSynth、PC Agent、AgentTrek 等,多为事后过滤无效任务、无内置前置校验,仅使用空白初始化环境;ProCUA 三大差异化优势:闭环前置条件校验、真实复杂业务文档初始化、全开源最大规模桌面 CUA 合成数据集。
八、结论与展望
- 结论
-
人工众包桌面轨迹数据集 AgentNet 会引发负迁移,不适合监督微调桌面智能体; -
全自动合成管线 ProCUA-SFT 通过任务前置校验、真实文档初始化、单 VLM 统一推演三大设计,产出高质量长时序、跨软件训练样本; -
软件组合多样性是提升桌面智能体泛化能力的核心;大量键盘文本操作能降低界面点击带来的脆弱性。 - 未来方向
-
基于更强开源 VLM 迭代数据生成管线; -
拓展 Windows、macOS 等更多操作系统环境; -
引入外部奖励模型优化轨迹质量; -
扩充稀有多软件复杂流程样本,进一步提升跨应用推理能力。