
⭐ 设为星标 · 第一时间收到推送

这次一个是模型发布,一个是产品发布。值得分开看:Sonnet 5 到底比上一代强在哪、为什么有人拿它和 Opus 4.8 对比后不买账;Claude Science 又到底是不是“科研版新模型”,还是一个把数据库、代码、计算资源和论文流程接起来的工作台。

先把两件事说清楚
Anthropic 这次先发的是 Claude Science,官方 X 主线程发布时间是 2026 年 6 月 30 日 17:02 UTC,换到北京时间大约是 7 月 1 日 1:02。随后又发 Claude Sonnet 5,官方 X 主线程发布时间是 6 月 30 日 18:00 UTC,也就是北京时间大约 7 月 1 日 2:00。
两个更新看起来都叫 Claude,但性质不一样。Sonnet 5 是一个新模型,进入 Claude Chat、Claude Code 和 Claude Platform;Claude Science 则是一个新的科研 App,目前是 beta,不是单独训练出的“Claude Science 模型”。
| 项目 | 官方定位 | 现在谁能用 | 读者最该关心什么 |
|---|---|---|---|
| Claude Sonnet 5 | Sonnet 系列新模型,主打 agentic coding、工具使用、长链路执行 | Free / Pro 默认;Max、Team、Enterprise 可用;Claude Code 和 API 可用 | 比 Sonnet 4.6 强,但不等于全面超过 Opus 4.8;价格要结合 tokenizer 和 effort 看 |
| Claude Science | 面向科研人员的 Claude App,把文献、数据库、代码环境、计算资源和可复现 artifact 放进一个工作台 | Pro、Max、Team、Enterprise beta;Team/Enterprise 需要管理员启用 | 它不是新模型,重点是科研工具链、数据/计算位置、可复现和 reviewer agent |
先说几个实用信息:Sonnet 5 已经可以直接用;Claude Science 也已经开放 beta,但它更像给科研团队试水的专业工具,不是普通用户随便问论文摘要时必须换的新入口。
Sonnet 5:官方说它是最会自主执行的 Sonnet
Anthropic 给 Sonnet 5 的第一句话很直接:这是目前最具 agent 能力的 Sonnet。它可以制定计划,使用浏览器、终端等工具,并且在更长链路里自主运行。
换成人话说,Sonnet 5 不是单纯“回答更聪明一点”。Anthropic 想强调的是:它更适合让模型自己拆任务、跑工具、检查结果、继续推进。这也是为什么官方文章里大量例子都围绕 coding agent、自动化任务、浏览器/终端工具使用,而不是普通聊天问答。
官方给的 benchmark 图,是理解 Sonnet 5 的第一层信息。
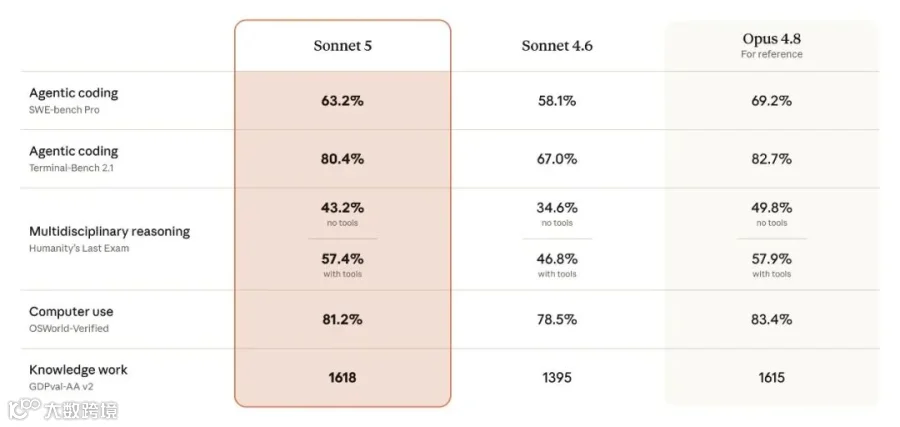
| 评测 | Sonnet 5 | Sonnet 4.6 | Opus 4.8 |
|---|---|---|---|
| SWE-bench Pro | 63.2% | 58.1% | 69.2% |
| Terminal-Bench 2.1 | 80.4% | 67.0% | 82.7% |
| Humanity's Last Exam,无工具 | 43.2% | 34.6% | 49.8% |
| Humanity's Last Exam,有工具 | 57.4% | 46.8% | 57.9% |
| OSWorld-Verified | 81.2% | 78.5% | 83.4% |
| GDPval-AA v2 | 1618 | 1395 | 1615 |
这张表可以分两句话看。
第一,Sonnet 5 相比 Sonnet 4.6 是明显升级。Terminal-Bench 2.1 从 67.0% 到 80.4%,HLE 有工具从 46.8% 到 57.4%,GDPval-AA v2 从 1395 到 1618,这些都不是小修小补。
第二,它不是 Opus 4.8 的全面平替。SWE-bench Pro、Terminal-Bench、HLE、OSWorld-Verified 这些项目里,Opus 4.8 仍然更高;GDPval-AA v2 上 Sonnet 5 是 1618,Opus 4.8 是 1615,Sonnet 5 略高,但差距很小。
所以,如果你问“Sonnet 5 是不是比 Sonnet 4.6 强”,答案是强。如果你问“是不是比 Opus 4.8 更强”,答案就没那么简单,至少官方这张表并不支持“全面更强”。
可用范围、价格和迁移成本
普通用户最关心的是能不能直接用。官方说,从发布当天起,Sonnet 5 已经在所有计划里上线:Free 和 Pro 默认模型切到 Sonnet 5;Max、Team、Enterprise 用户可用;Claude Code 和 Claude Platform 也同步支持。
开发者更需要看几个具体字段。
| 维度 | Sonnet 5 信息 |
|---|---|
| API model id | `claude-sonnet-5` |
| introductory pricing | 到 2026 年 8 月 31 日:输入 $2 / 百万 token,输出 $10 / 百万 token |
| 标准价格 | 2026 年 8 月 31 日后:输入 $3 / 百万 token,输出 $15 / 百万 token |
| tokenizer | 新 tokenizer,同样输入可能映射为 1.0-1.35 倍 token |
| effort | 支持不同 effort level,在成本和任务成功率之间取舍 |
| rate limits | 官方称已经提高 Chat、Cowork、Claude Code、Claude Platform 的 Sonnet / Haiku rate limits |
这里最容易被忽略的是 tokenizer。官方明确说,Sonnet 5 是 Sonnet 4.6 的升级,但更新了 tokenizer;同一段输入,可能变成原来 1.0 到 1.35 倍 token。Anthropic 把 8 月 31 日前的 introductory pricing 设低,是为了让迁移期大体成本中性。
这也解释了为什么“每百万 token 单价更低”不等于“每个 agent 任务一定更便宜”。Agent 任务的真实成本通常由几件事一起决定:token 单价、token 数变化、effort level、工具调用次数、模型走了多少步、任务最后有没有成功。
官方文章还特别提到 cost-performance 图,比较 Sonnet 5、Sonnet 4.6 和 Opus 4.8 在不同 effort level 下的 BrowseComp 和 OSWorld-Verified 表现。官方的口径是:Sonnet 5 比 Sonnet 4.6 严格更好,并提供了比 Opus 4.8 更宽的成本-性能选择空间;中等 effort 下成本效率更好,高 effort 在一些任务上可以接近或匹配 Opus 4.8。
但这句话要读完整:接近或匹配一些任务,不是全面超过 Opus 4.8。
安全和限制:更强,也默认加了 cyber safeguards
Sonnet 5 的安全部分也值得看。Anthropic 说,Sonnet 5 相比 Sonnet 4.6,整体不良行为率更低,幻觉和迎合更少,在 agent 场景里更能拒绝恶意请求,也更能抵抗 prompt injection。
但官方也承认,和更强的 Opus 4.8、Claude Mythos Preview 比,Sonnet 5 在自动化行为审计上的 misaligned behavior rate 更高。也就是说,它比上一代 Sonnet 更安全,但不能简单理解成“越新越安全、所有维度都更好”。
网络安全相关限制也要单独说。Anthropic 表示没有刻意训练 Sonnet 5 做 cyber 任务,它可以处理一些常规、非恶意的网络安全工作,但在危险 cyber 能力评测里明显弱于 Opus 4.8 和 Mythos 5。由于 Sonnet 5 比 Sonnet 4.6 更强,官方默认开启实时 cyber safeguards。
如果你做的是普通 coding、debug、内部自动化,Sonnet 5 很可能会成为默认选择。如果你做的是需要低限制能力的安全研究,官方仍然建议用 Opus 4.8。
社区争议:大家主要卡在“为什么不用 Opus 4.8”
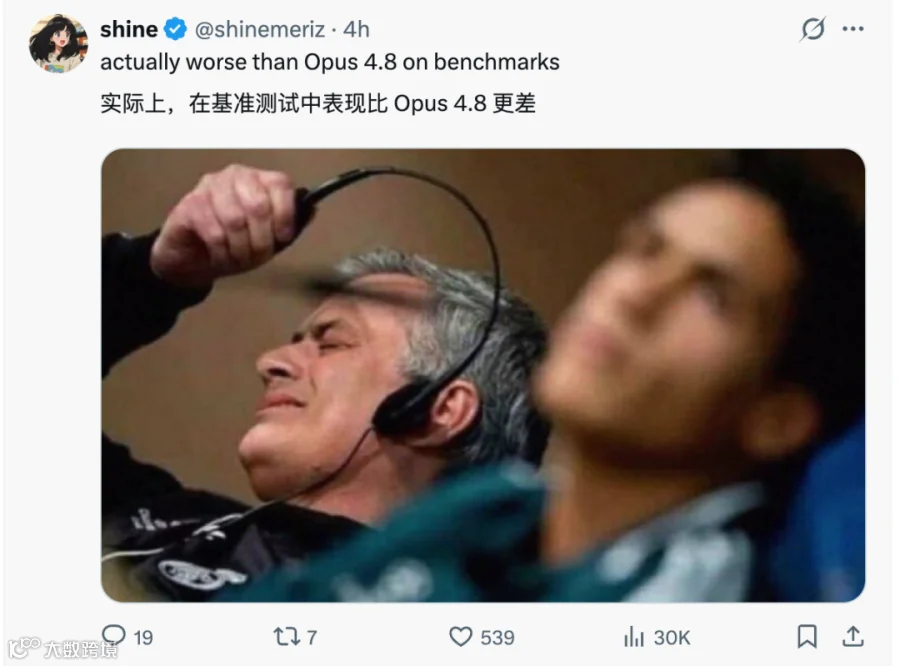
你给的几张截图很有代表性:社区里这次不是单纯欢呼,很多人第一反应是在问同一个问题:如果 Sonnet 5 在不少 benchmark 上低于 Opus 4.8,为什么我要用 Sonnet 5?
先看最直接的一类反馈:有人把官方 benchmark 截出来,指出 Sonnet 5 实际上在不少指标上比 Opus 4.8 更低。
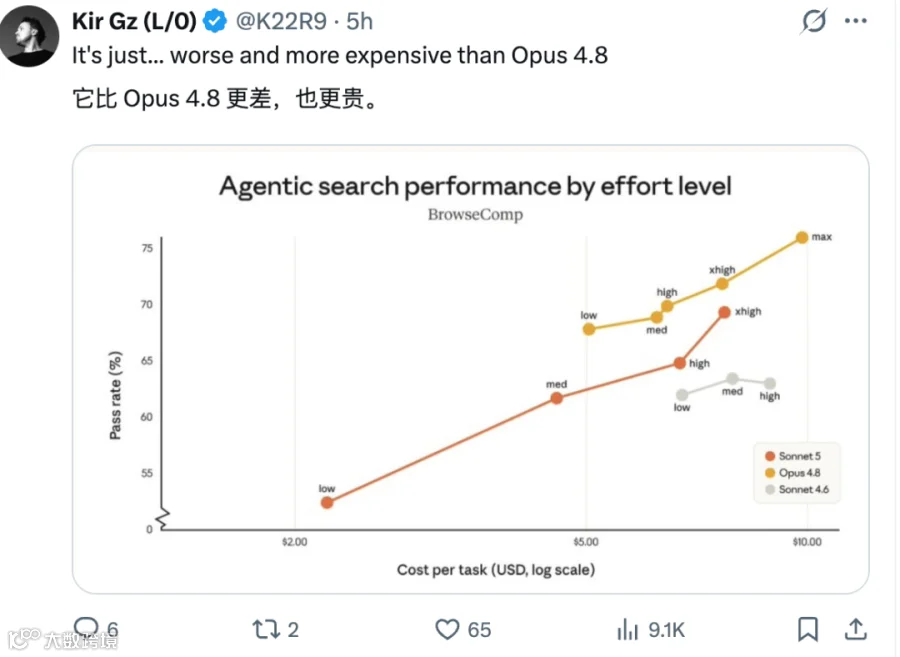
第二类质疑集中在成本上。有人拿 agentic search 的 cost-performance 图说:Sonnet 5 可能不只是更弱,在某些 effort level 下还可能更贵。这个说法未必能一概而论,但它戳中了一个关键点:agent 成本不能只看 token list price。
还有更口语化的反应,就是“我有点困惑,改进在哪里?”以及“为什么不用 Opus 4.8?Sonnet token 更便宜吗?”
这些反馈不算杠。因为 Anthropic 这次的叙事确实容易让人期待“Sonnet 5 接近 Opus 4.8,而且更便宜”,但官方表格又显示它不是全面接近。更准确的读法应该是:
- 拿 Sonnet 4.6 做参照:Sonnet 5 是明确升级,尤其是 coding、工具使用、长链路 agent 任务。
- 拿 Opus 4.8 做参照:Sonnet 5 多数 benchmark 仍然落后,只有部分任务接近,个别项目略高。
- 拿 API 成本做参照:Sonnet 5 的 token 单价低于 Opus 档,但 tokenizer、effort 和任务步数会影响真实 cost-per-task。
- 拿产品默认值做参照:Sonnet 5 成为 Free / Pro 默认模型,这对日常用户的实际影响比“是否打赢 Opus”更直接。
所以这次社区争议不是“Sonnet 5 烂不烂”,而是“它的定位到底是什么”。如果你把它当成 Sonnet 4.6 的升级,信息是清楚的;如果你把它当成 Opus 4.8 的替代品,疑问就会很多。
Claude Science:这不是新模型,是科研工作台
再看 Claude Science。
它最容易被误会成“Anthropic 发布了一个科研专用模型”。但官方 FAQ 写得很清楚:Claude Science 是 public beta App,不是一个新模型。它使用的是你账号计划里已有的 Claude 模型,新的部分在模型外面:科研工具、数据库连接、计算环境、可复现 artifact、reviewer agent。
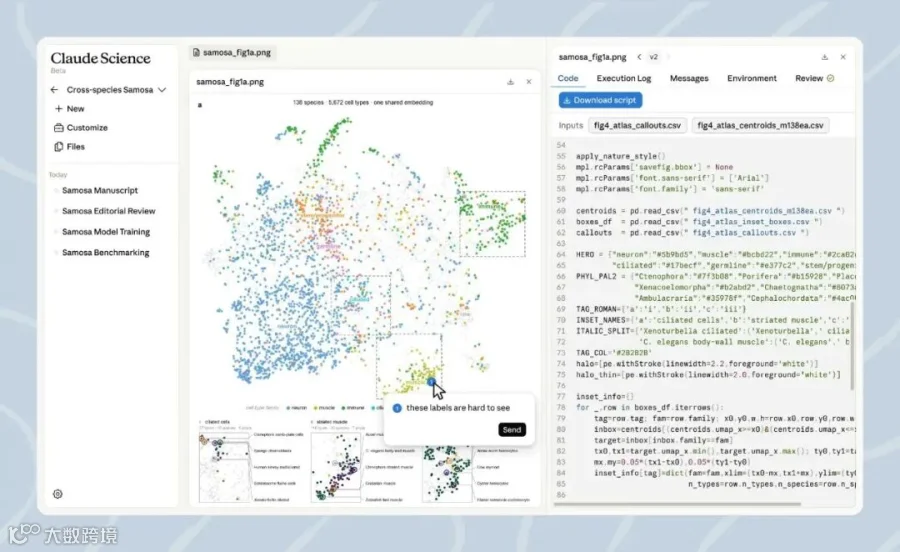
Anthropic 对 Claude Science 的描述是 AI workbench for scientists。这个词比“聊天助手”更准确。科研人员的工作本来就不是只问一个问题:要查文献、拉数据库、跑代码、生成图、改图、写 manuscript、检查引用、管理计算资源,很多时间浪费在不同工具之间切来切去。
Claude Science 想做的,就是把这些环节放到一个环境里。
它的核心能力可以拆成几组:
- 可复现 artifact:图表、表格、notebook、manuscript 不只是结果,还带生成代码、运行环境、自然语言说明和对话历史。
- 内置科学渲染器:可以查看蛋白结构、基因组轨道、化学结构、PDF 等,不用每次另装一堆查看器。
- 图表自然语言迭代:比如让它去掉 gridline、把坐标轴改成 log scale,它会回到生成图表的代码里改。
- 科研 reviewer agent:后台检查引用、数字、图表和代码是否对得上,找不到证据的说法会被标出来。
- 可扩展技能和连接器:已有 pipeline 可以保存成 reusable skill,实验室内部工具、ELN、API 可以通过 connectors 接入。
这和普通 Claude 最大的区别,不是“更懂生物学”,而是它能跑流程,并且保留 provenance。所谓 provenance,就是每个结果从哪里来、用什么代码生成、在哪个环境跑、前面怎么讨论出来的,都能追溯。
科研里这个很关键。一个看起来漂亮的图,如果三个月后没人知道它对应哪份数据、哪段代码、哪个环境,那就很难复现,也很难给论文或团队评审用。
它能接计算资源,也能尽量让数据留在原处
Claude Science 另一个重点是计算环境。
官方说,它可以运行在你的 laptop、Linux box、HPC login node,或者云上的 VM;任务可以跑在本地 kernel、实验室自己的 Slurm 集群、SSH 连接的机器,或者 Modal 账号上。需要大算力时,它会先起草计划,在触达新资源前询问用户,用户可以审查或撤销决定,然后再提交 job。
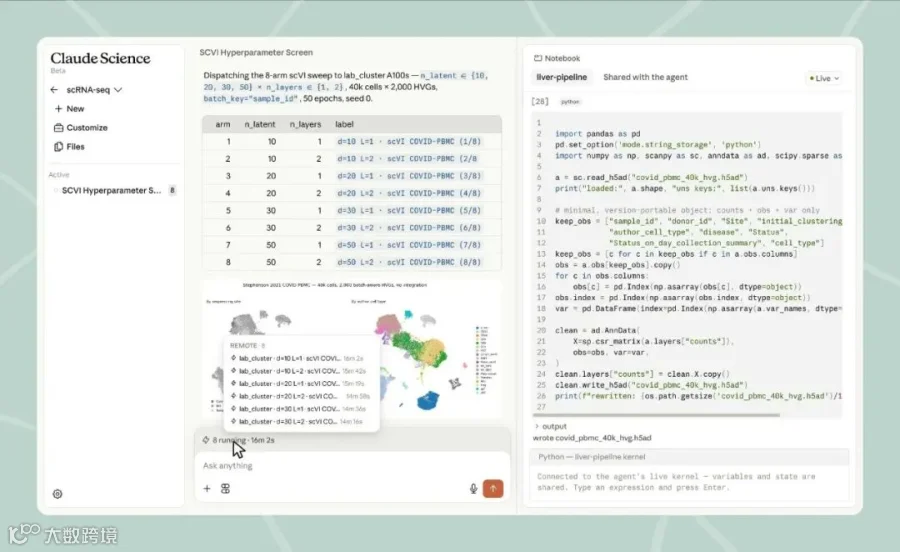
这一点对科研团队很重要,因为很多真实科研数据不适合随便上传。官方 FAQ 里的说法是:Claude Science App 运行在你的基础设施上,raw datasets 和 compute stay local;但放进 prompt 和 model response 里的内容,仍然会按 Anthropic 标准 retention 处理。企业或团队有特殊要求,需要联系 sales。
换句话说,它不是“所有数据都不离开本地”。更准确的说法是:原始数据和计算可以留在你自己的机器或集群里,但模型每一步需要看到的上下文,还是会被送去 Claude 处理。这个边界对医学、生物、企业研发尤其重要,不能含糊。
预配置方向:生命科学优先,但不只是一堆插件
Claude Science 目前明显偏生命科学。官方说,它预配置了 genomics、single-cell、proteomics、structural biology、cheminformatics 等方向,并且可以查询 60+ 科学数据库。
产品页列的例子也比较具体:
| 方向 | 官方示例 |
|---|---|
| Single-cell RNA-seq | 聚类和注释数百万细胞,找 marker genes,并把每张图追溯到代码 |
| Evolutionary analysis | 对 orthologs 做 alignment,推 maximum-likelihood trees,把功能残基映射到 phylogeny |
| Protein structure | 拉取预测结构,叠加 domains 和 clinical variants,在 3D 里交互查看 |
| Cheminformatics | 搜 bioactivity data,计算性质和相似性,绘制或优化分子结构 |
它还接入 NVIDIA BioNeMo Agent Toolkit,连接 BioNeMo 里的生命科学模型和库,包括 Evo 2、Boltz-2、OpenFold3。对普通用户来说,这些名字可能不重要;对科研团队来说,关键是 Claude Science 不是只在网页上检索,它试图把已有数据库、开源模型、实验室 pipeline 和计算环境都纳入同一个 session。
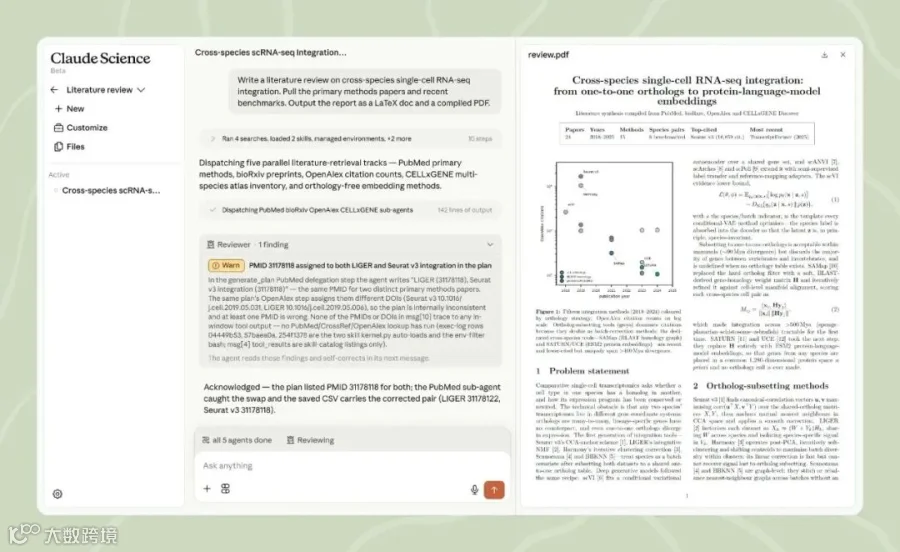
官方案例里也基本围绕生命科学:Manifold Bio 用它为新实验筛选组织靶向药物的候选 target;Allen Institute 的 Jérôme Lecoq 用它搭了一个包含约 20 个自定义 skills 的 computational review template;UCSF 的 Stephen Francis 用它支持 glioma 分子流行病学分析,官方文章称综合 germline workups 大约提速到过去的十分之一。
这些案例可以说明方向,但不能直接当成普遍效果。科研工作最后还是要独立验证、专家评审、实验确认。Claude Science 更像是把“找资料、跑分析、做图、检查引用”这些环节压缩到同一个工作台里,而不是替代科研判断本身。

Claude Science 现在怎么用,哪些人适合试
Claude Science 现在是 beta,支持 macOS 和 Linux。Pro、Max、Team、Enterprise 用户可以用;Team 和 Enterprise 需要管理员先启用。官方也提供面向学术机构和非营利科研组织 active scientific labs 的折扣 Team plan,优先覆盖 biomedical、basic science,以及 chemistry、math、computer science、physics 等硬科学方向,资格通过 PI 验证。
还有一个项目支持计划:Anthropic 表示会支持最多 50 个 Claude Science AI for Science projects,每个项目最高 $30,000 credits;Modal 也会给部分项目最高 $2,000 compute。申请截至 2026 年 7 月 15 日,通知在 7 月 31 日发出,项目周期是 2026 年 9 月 1 日到 12 月 1 日。
这说明 Claude Science 现在更适合几类人:
- 真的有数据和代码的科研团队:尤其是生命科学、结构生物学、单细胞、蛋白质组、化学信息学相关团队。
- 需要复现和审计的项目:结果不只是给自己看,还要给团队、PI、审稿人或合作方解释。
- 已经有 HPC / Linux / Python / R 工作流的实验室:Claude Science 的价值在于接现有工具链,不是从零替你建实验室。
- 想先做低风险试点的团队:比如公开数据复现、文献 evidence database、图表生成和 reviewer 检查。
不太适合的人也很明确:如果你只是偶尔问论文摘要、让 Claude 帮你解释一个概念,普通 Claude 已经够用。Claude Science 的价值在于长期项目、可复现流程和工具集成,不在于多一个聊天入口。
这次发布可以怎么用
如果你是普通 Claude 用户,最直接的变化是默认模型换成 Sonnet 5。你可以先拿日常写作、资料整理、代码解释、长任务执行试一下,重点观察它是不是更愿意把任务做完,而不是中途停住。
如果你是开发者,建议别只看“每百万 token 价格”。更实际的测试方式是拿自己真实任务做 A/B:同一个任务分别跑 Sonnet 5 和 Opus 4.8,记录成功率、总 token、工具调用次数、耗时和需要人工接管的次数。对于 agent 任务,跑通一次比单价便宜一点更重要。
如果你是科研团队,Claude Science 可以关注,但最好从可验证的小项目开始。比如公开数据分析、文献综述 evidence state、图表复现、已有 pipeline 的自然语言封装。涉及敏感数据、临床数据、未发表结果时,要先把数据边界、retention、管理员权限和审计要求弄清楚。
到这里,两个更新可以分开处理:Sonnet 5 是 Sonnet 档位的一次明显升级,但不是 Opus 4.8 的全面替代;Claude Science 是一个面向科研流程的 beta 工作台,不是科研专用新模型。要不要用,还是回到具体问题:你的任务是追求最高成功率、追求成本效率,还是需要把复杂流程放进一个可复现的工作环境里。