
⭐ 设为星标 · 第一时间收到推送
真正的变化:不是记笔记,而是少复述
如果你经常用 Claude、Codex 或其他 Agent,最烦的不是模型不聪明,而是每个新会话都要重新交代背景:我是谁、项目做到哪、哪些资料可信、上次为什么这么决定。
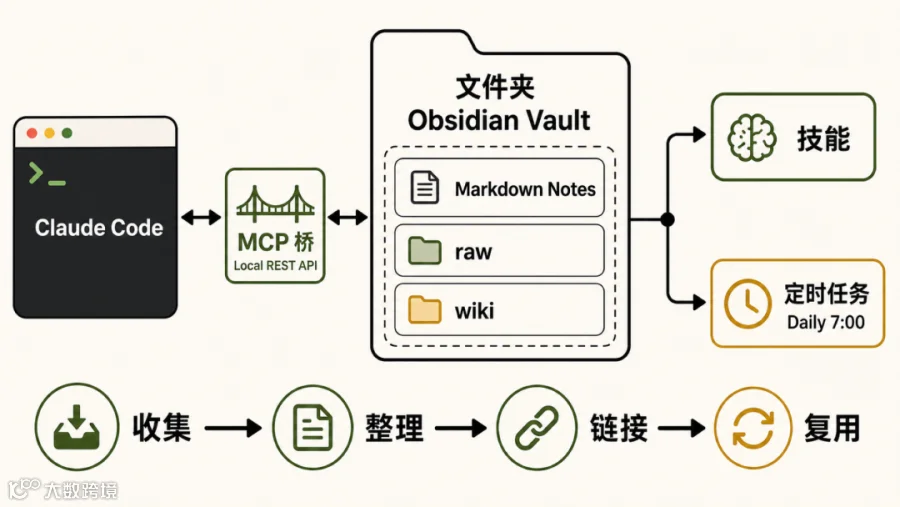
核心思路很直接:别再把人生和项目背景一段段粘进聊天框,直接把模型指向一个文件夹。这个文件夹用 Obsidian 管,因为它底层就是一堆 本地 Markdown 文件,链接、标签、目录都能被人和模型一起读。
这样做有两个好处。
第一,记忆不被某个模型或某个聊天产品锁死。今天是 Claude Code,明天也可以换成 Codex、Gemini 或另一个本地 Agent,只要它能读写这批 Markdown,知识就还在。
第二,AI 的工作对象从“聊天记录”变成了“项目文件”。它不只是回答你一句话,而是能整理新资料、更新旧笔记、补链接、找矛盾,最后把结果写回 vault。
说白了,这不是把 Obsidian 神化成第二大脑,而是把 Obsidian 当成一个 长期上下文硬盘。
最小搭法:先让 Claude 看见你的 vault
这套路径可以拆成 Claude Code + Obsidian + Local REST API + MCP。这里有个需要校准的小点:Claude Code 当前官方 quickstart 主推的是终端 CLI 安装,也支持 Web、桌面、VS Code、JetBrains、Slack 和 CI/CD 等入口。具体装法以官方文档为准。
最小可行版本可以这么理解:
| 步骤 | 做什么 | 目的 |
|---|---|---|
| 1 | 安装 Claude Code,并登录 Pro / Max / Team / Enterprise 或 Console 账号 | 让 Claude 能读写本机项目文件 |
| 2 | 在 Obsidian 新建一个 vault | 把长期知识放进普通文件夹 |
| 3 | 安装 Local REST API 插件 | 给 vault 开一个受 API key 保护的本地接口 |
| 4 | 用 MCP 把 Claude Code 接到接口上 | 让 Agent 可以列文件、读笔记、追加内容、搜索 |
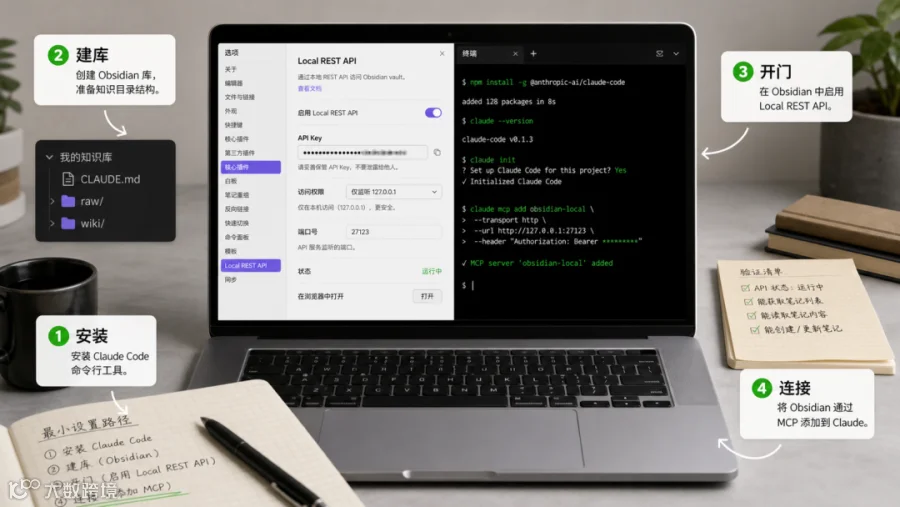
Local REST API 的官方 README 里已经给了更直接的 Claude Code HTTP MCP 配置方式,大意是把本地 MCP 地址和 Bearer token 加进去:
命令示意:
claude mcp add --transport http obsidian https://127.0.0.1:27124/mcp/ \
--header "Authorization: Bearer <your-api-key>"
如果你用的是 mcp-obsidian 这类 stdio 桥,也可以走 uvx mcp-obsidian 的方式。两条路的本质一样:Claude 不是“知道你有一个 Obsidian”,而是拿到了经过授权的工具,可以真正读写 vault。
我建议第一天只做三件事:确认 Claude 能列出 vault 文件,能读一篇笔记,能在指定目录新建一篇测试笔记。先别急着让它自动整理所有资料,工具能通比工作流好看重要得多。
值得抄的是结构:raw 和 wiki 分开
这套做法里最有价值的一层,是借了 Karpathy 的 LLM Wiki 思路:把原始材料和模型整理后的知识分开。
raw/ 放不动的东西:文章、PDF、会议纪要、网页摘录、截图、转写稿。这里像证据柜,Agent 可以读,但不要随便改。
wiki/ 放模型整理后的东西:概念页、项目页、人物页、问题页、交叉引用。这里才是会不断重写、合并、更新的部分。
这条边界非常关键。很多人的“第二大脑”失败,不是因为工具不够强,而是因为原始资料、临时想法、AI 总结、待办事项全混在一起。到最后你不知道哪句话是原文,哪句话是模型归纳,哪句话是过期判断。
Obsidian Skills 也在补这个缺口。Steph Ango 的 kepano/obsidian-skills 给 Agent 补了 Obsidian 方言:wikilinks、callouts、Bases、Canvas、CLI、网页提取。也就是说,Claude 不只是会写 Markdown,而是更懂 Obsidian 里那些“看起来像 Markdown、实际有语法约定”的东西。
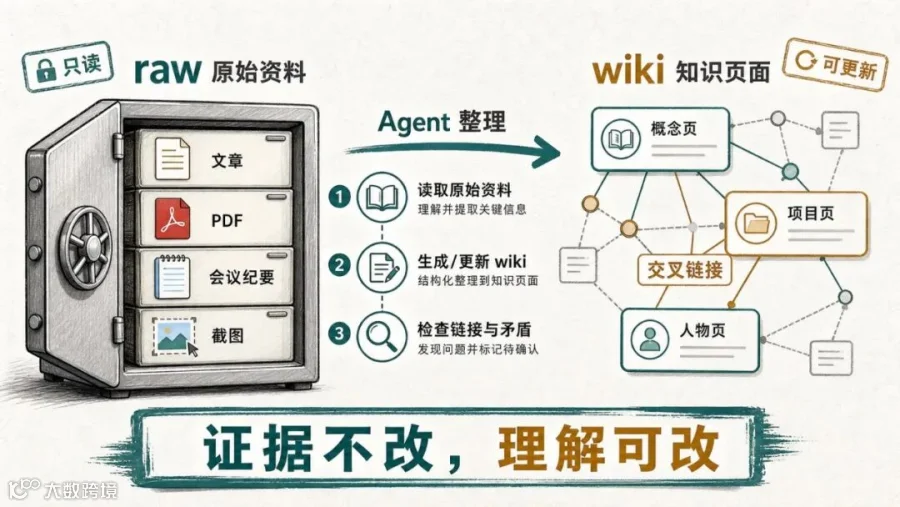
这里的判断是:别一开始追求“全自动第二大脑”。先让 Agent 学会一件小事,比如每次你丢进 raw/ 一篇文章,它只做三步:写摘要、抽概念、补 3 个相关链接。这个动作稳定以后,再加日程、任务、邮件、浏览器标签页。
权限边界,比提示词更重要
还有一个关键提醒:不要用“请不要删除我的文件”这种提示词来当安全策略。
提示词是建议,权限才是设置。如果一个 Agent 拿到了全盘读写和删除权限,它迟早会在某个误判、某个坏网页、某个注入内容里做出你不想要的动作。
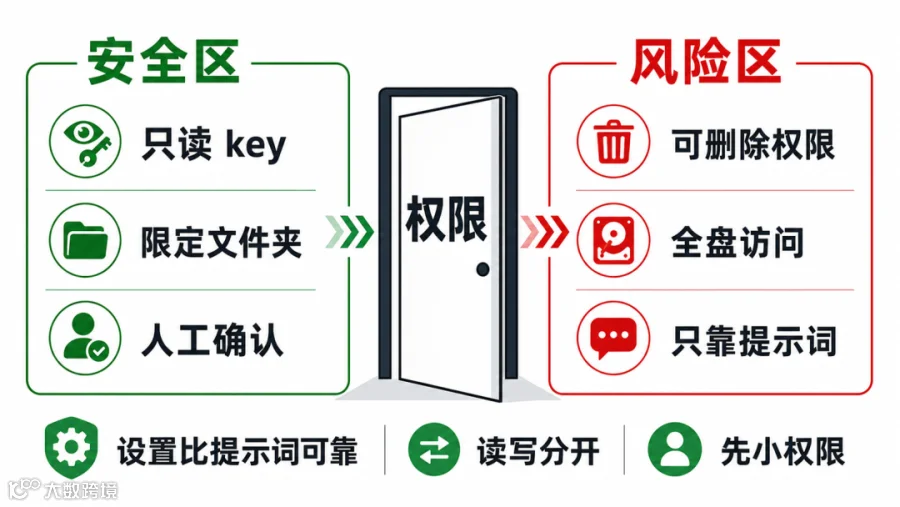
更稳的做法是三条:
- 先给 只读权限,确认检索和总结可靠后再开放写入。
- 写入只给限定目录,比如
wiki/、tasks/、inbox/,不要让它默认碰整个 vault。 - 删除、移动、批量重命名、外发消息这类动作,必须人工确认,或者单独做更窄的 key。
自动化最诱人的地方,是它能在你不看屏幕的时候继续工作。自动化最危险的地方,也正是它能在你不看屏幕的时候继续工作。
所以我的建议是:每天 7 点自动整理可以有,但第一版只让它“报告变化”,不要直接“修改世界”。等你看过一周日志,知道它会怎么判断,再把写权限一点点打开。
不想手搓,可以从社区方案改
如果你只是想试试这个方向,不一定要从零开始搭。
几个社区仓库正好对应不同入口:mcp-obsidian 更像连接桥,kepano/obsidian-skills 是格式技能包,AgriciDaniel/claude-obsidian 走自组织 vault,coleam00/second-brain-starter 则先让 Claude Code 生成一份个性化 PRD,再按阶段搭系统。

这里不要迷信“现成仓库一键拥有第二大脑”。第二大脑最难的部分不是安装,而是边界:哪些资料值得进来,哪些动作可以自动,哪些内容必须保留原文,哪些总结可以被覆盖。
最后说一句
这套玩法真正值得抄的,不是某个命令,而是一个朴素原则:把长期上下文放在你控制的文件系统里,再让 Agent 围着它工作。
模型会换,产品入口会换,但一批干净、可追溯、能被不断重写的 Markdown 文件,才是最不容易过期的资产。
一句话判断:第二大脑不是把资料都丢给 AI,而是先把资料放进你可控的文件系统,再把 AI 变成负责整理和连接的工作层。