

传统AI质检系统经过大量缺陷样本训练后,能够精准识别已知缺陷类型。那么,如何让AI质检系统在产线上具备“举一反三”的能力,不仅能认识已见过的缺陷,更能高效识别从未见过的新型缺陷?第六镜科技的基于云边端架构的开集目标检测技术专利(CN 119046890 B),为这一问题提供了创新性解答。

一、AI质检两道坎:闭集检测的盲区与开集检测的落地困境
闭集检测盲区在哪?
传统AI目标检测技术属于闭集检测范畴,该模型的测试样本和应用场景均来自训练阶段已知的类别。因此闭集检测模型无法识别训练数据中从未出现的缺陷类型,新缺陷出现后还需要重新采集数据、标注、训练、部署,响应周期长,维护成本也因其场景适应性差持续攀升。
➤典型场景:某钢铁企业引入新型合金材料后,生产线上出现了一种从未见过的表面裂纹。由于该裂纹形态与已知缺陷差异较大,传统AI质检系统完全无法识别,导致批量质量问题。

开集检测常见的落地困境
开集目标检测技术近年来取得了突破性进展,只需用自然语言描述,如“找表面发黑的裂纹”,AI就能在图像中定位到它,理论上完美解决了闭集检测的痛点。
然而,开集检测落地时也存在困境:这些视觉语言模型通常包含数亿甚至数十亿参数,边缘跑不动;视觉语言模型的视觉处理单元和语言处理单元紧密耦合,难以拆分部署,但如果全部放云端,带宽压力大,延迟可能达到数秒。

那么,如何让开集检测从实验室能力变成产线能力?答案就在于云边端协同架构。
二、第六镜方案:云边端协同,让开集检测真正落地工业场景
为什么需要云边端协同?
针对开集检测的计算资源瓶颈,第六镜科技的解决方案是:基于任务特性进行分层处理,在云端与边缘端之间实现计算负载的优化分配。
边缘设备的优势在于“近”:部署于产线现场,能够实时采集图像并进行快速响应。
云端服务器的优势在于“强”:具备充足的GPU算力资源,能够运行复杂的视觉语言模型。

云边端协同如何让开集检测落地?
具体怎么协同落地?第六镜科技采用了“知识库检索+智能路由”机制。
边缘设备上部署了轻量级的视觉检测模型,体积小、速度快,专门用来处理已知缺陷;云端维护着一个预设类别表,记录了所有已知缺陷类型。
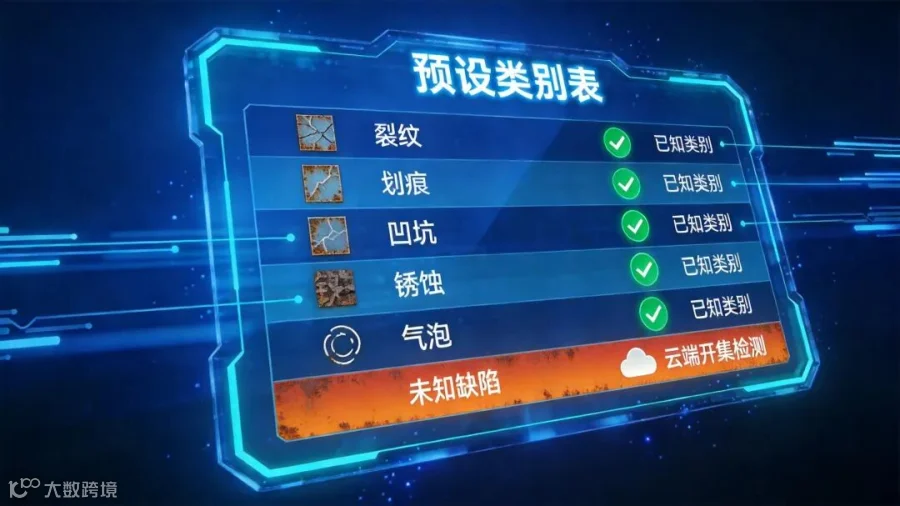
检测开始后,云端优先检索“常见缺陷知识库”:若存在该缺陷类型,边缘设备直接调用本地模型实现毫秒级检测响应,无需网络通信往返;若知识库中不存在(如某种新型裂纹),则判定为开集识别场景,云端用大模型进行推理,并将结果返回至边缘端。
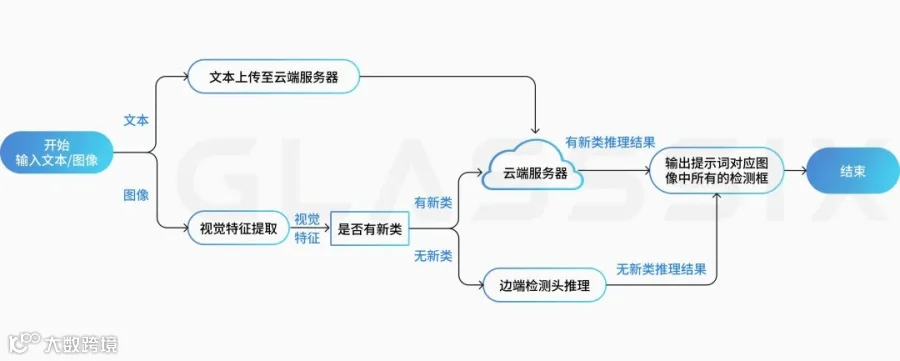
日常90%以上的检测任务在边缘端就完成了,只有少数“疑难杂症”才需要云端介入,对于企业来说,无需持续扩容网络带宽和云端算力,即可同时获得毫秒级常规检测能力与开集缺陷识别能力。
三、落地效益:基于云边端协同的开集检测能带来什么?
1、降低部署门槛
传统检测方案需要在边缘设备部署完整的视觉语言模型,对硬件算力要求较高,中小型工厂难以承受。
第六镜科技云边端协同方案下,边缘设备只需部署轻量级视觉检测模型,大幅降低了边缘端的硬件要求。同时,云端大模型只在出现新缺陷时才会被调用,优化了资源使用,减轻了边缘设备的负担,企业整体部署成本下降。
2、降低企业运维成本
传统方案需要逐台更新边缘设备的模型,工作量大且容易出错。本专利将语言特征提取器部署在云端,云端集中更新比逐台更新边缘设备更高效、更经济。这种架构确保了所有边缘设备能同步最新的模型改进,大大降低了企业后期运营成本和复杂性。
3、模型迭代周期缩短,检测效率稳定在线
传统方案中,发现新缺陷后需要经历采集样本、人工标注、模型训练、部署上线等流程,往往需要数周时间。而开集检测方案下,视觉语言模型通过文本提示词就能改变检测的输出方向,无需重新训练即可适应新的检测需求,模型更新优化的频次大幅降低,检测能力稳定发挥。
4、保障端侧检测精度
传统轻量化模型往往因为规模小导致效果不佳。而本专利通过优化视觉语言模型架构和算法,让部署在边缘设备的端模型在保持轻量的同时,仍能达到较高检测精度。

第六镜科技专利技术通过云边端协同架构与视觉语言模型的创新结合,促进了工业质检范式的进一步升级——
让机器具备真正的理解能力,而不仅仅是模式匹配能力,开集检测技术的落地是工业AI视觉向更智能、更实用方向迈进的重要一步。第六镜科技将持续深挖AI视觉的多模态融合算法能力,始终以技术创新赋能中国制造业高质量发展。
