

大家都想用大语言模型(LLM)写量化策略,但生成的代码不是带未来函数,就是年化指标算错。本文推出首个专门针对自动化量化回测的基准测试 BacktestBench,并提出基于“总结-检索-编码”的多智能体框架。大模型到底会不会算夏普比率?一测便知。
【论文信息卡片】
Title: BacktestBench: Benchmarking Large Language Models for Automated Quantitative Strategy Backtesting
Authors: Zhensheng Wang, Wenmian Yang, Qingtai Wu 等 (北京师范大学等)
Source: KDD 2026 / arXiv 2024
Code: 已开源 (提供详尽的 Python 多智能体调度与评估源码)

🎯 评测基准创新:终结了大模型金融评测缺乏真实回测环境的痛点,构建了包含 1.8 万个高质量问答对的 BacktestBench,涵盖指标计算、标的精选、策略选择、参数确认四大核心任务。
📊 数据与回测:底座数据绝非简单模拟,而是采用中国三大交易所(A股)654 万条真实日频行情数据(2020-2025),并硬性规定“无未来函数”、“T-1 获取信号”等真实交易约束。
💰 多智能体架构:提出 AutoBacktest 协同框架,将“大白话”灵感精准拆解为因子提取(BM25 检索)、SQL 提数、Python 回测代码生成三步,大幅提升了代码执行成功率和逻辑准确度。

Quant(量化研究员)们日常工作最繁琐的部分就是:将金融逻辑转化为因子、写SQL查数据库、最后用Python实现回测。大语言模型(LLM)虽然代码能力惊人,但在量化回测领域有其致命的“壁垒”:一旦涉及复杂的金融时序逻辑,LLM极易产生幻觉,或者引入未来函数(Look-ahead bias)(比如用今天的收盘价决定今天的买入)。
目前学术界和工业界严重缺乏一个大规模的、基于真实市场数据的标准基准,来检验大模型到底能不能胜任 Quant Researcher 的工作。为此,作者利用真实的A股数据,通过逆向工程(Code-to-Text),为大模型量身定制了一套量化“期末考试卷”。

BacktestBench 的核心价值,在于把真实量化回测任务拆成可评测、可执行、可复现的多智能体流水线:
数据构造:作者提取 A股 600 万+ 真实行情数据,将策略源码逆向解析为自然语言,并经过多模型交叉验证,最终生成 18,246 个包含自然语言策略、SQL 数据查询和 Python 回测代码的数据集。
核心架构(AutoBacktest 多智能体系统):
Summarizer(总结者):通过 LLM + BM25 检索,把用户的自然语言策略翻译成标准的“因子短码(Short Codes)”(如将“昨日收盘价”映射为 DELAY(CLOSE,1))。
Retriever(检索者):拿着因子短码写 SQL,从数据库里把精确的历史行情切片,且自带报错重试机制。
Coder(程序员):利用前置数据和标准化回测协议(硬性规定买开卖平、规避未来函数),生成可直接运行的 Python 评估代码。
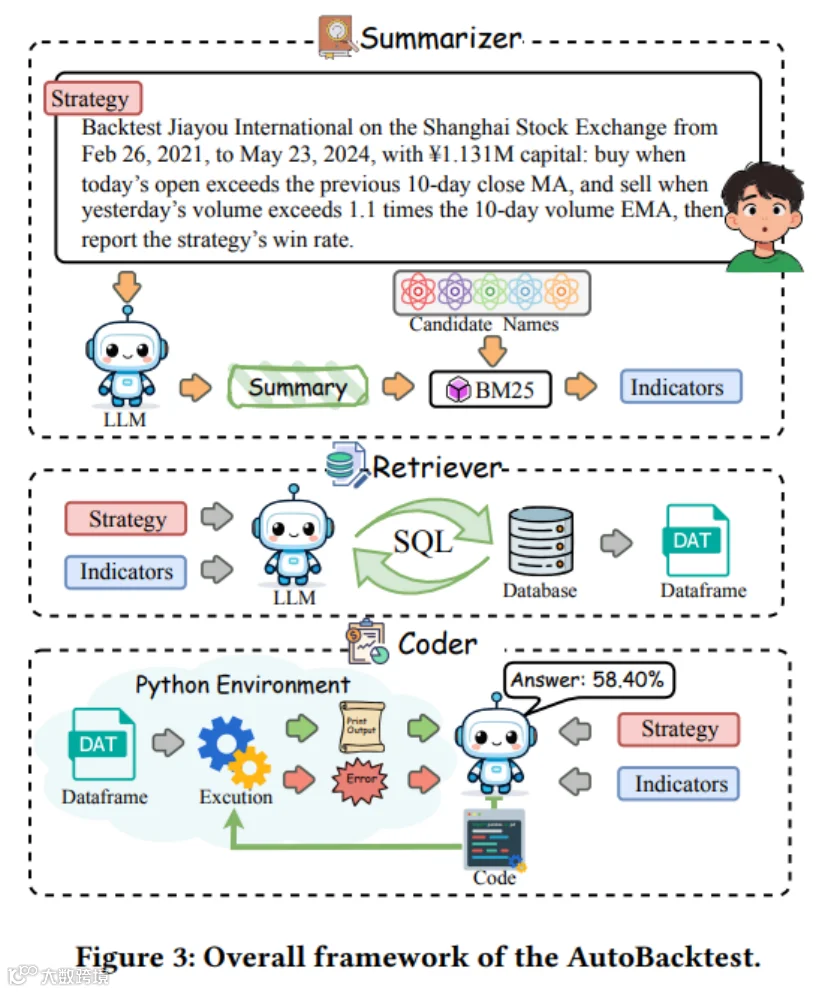
展示三个 Agent 如何串联完成从自然语言到代码回测的绝美流水线

作者对 23 个主流 LLM 进行了大规模自动化回测“拷问”,结果非常扎心:
逻辑越复杂,LLM 越崩溃:
计算胜率(Win Rate)这类简单指标还相对可控,一旦涉及年化波动率(Vol)和夏普比率(Sharpe),很多开源模型频繁把年化波动率算成日波动率,或者漏掉初始净值锚点。
闭源与开源的交锋:
Gemini 3 Pro 在综合逻辑推理上拔得头筹,准确率达到 67.41%;国内 GLM 4.7 准确率达到 56.83%,Qwen 系列也表现抢眼,但在复杂统计指标推导上仍有差距。
约束提示词至关重要:
消融实验证明,如果不给模型提供标准化的因子短码上下文,模型凭空捏造 SQL 的执行准确率会断崖式下滑。量化任务里,约束和上下文比“让模型自由发挥”更重要。
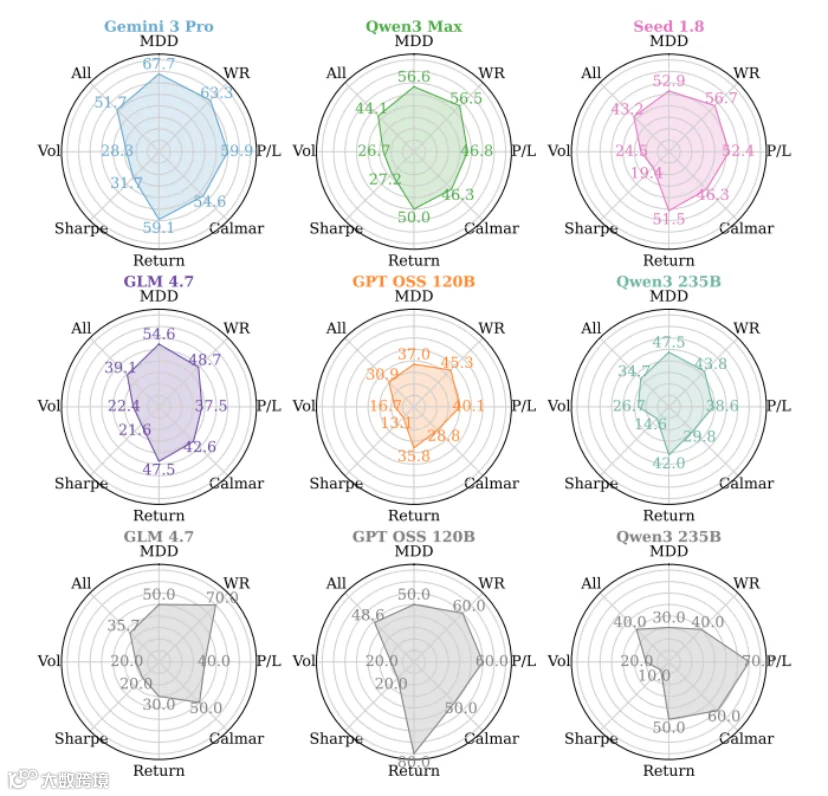
展示各类大模型在计算夏普和波动率时的“集体拉胯”表现

🔥 落地价值评估(解放量化研究员的双手):
这篇文章极其契合当前国内百亿私募打造 AI 投研中台的趋势。它把投研流程抽象为 NL → 提取因子(BM25)→ SQL 提取切片 → Python 回测,并用严格系统 Prompt 强制约束 T-1 信号和回测协议,显著降低了研究员验证策略灵感的摩擦成本。量化团队完全可以把这套代码作为内部 AI 投研基座的雏形。
⚠️ 避坑与局限性(回测环境过于“乌托邦”):
标准化协议牺牲真实细节:虽然文章在代码层面严格防止未来函数,但为了方便 LLM 理解,它设定了较理想化的标准回测协议,例如固定开盘买、收盘卖。这能提升评测一致性,却会牺牲不少真实交易细节。
交易成本与成交约束缺失:当前协议没有充分考虑滑点、印花税、佣金、涨跌停板导致的无法成交等问题。在 A股市场,如果不计入这些摩擦,哪怕模型写出了夏普 3.0 的漂亮代码,一上实盘也可能被交易成本迅速反杀。
与其沉迷于深度学习回测里虚幻的高夏普,不如静下心来用一套“不作弊”的框架拷问一下你的交易逻辑!这篇论文的开源架构甚至为未来接入 LLM(大语言模型)自动生成交易规则做好了底层铺垫。
本期论文原文 PDF 及作者完整的 Python 验证框架源码链接已打包完毕。

获取方式:扫码添加小助理,进入量化社群 ⬆️
文案:Poem
编辑:孑孓乐



