

作为 AI 实践的基石,大模型输出的每句话在投研/交易链路中都有被放大的风险,是一个起点问题。
好在,现在有很多方式可以解决:
Harness 约束流程和边界
Skills 沉淀动作
RAG 让数据可溯源
但会不会从更基础的层面来处理,才更可靠呢?我们做了一次实践测试。

如果未来 AI 交易成为主流,必然会有如报单失败这类时间窗口极短的场景出现,这时候模型的初始输出效率、质量和语境也会更加很关键。
基于这个判断,我们会先看模型在金融解释和量化代码。
解释类任务:本质上是看模型处理上下文和概念边界的能力;
代码类任务:在看模型能不能把金融逻辑落到明确的代码里。

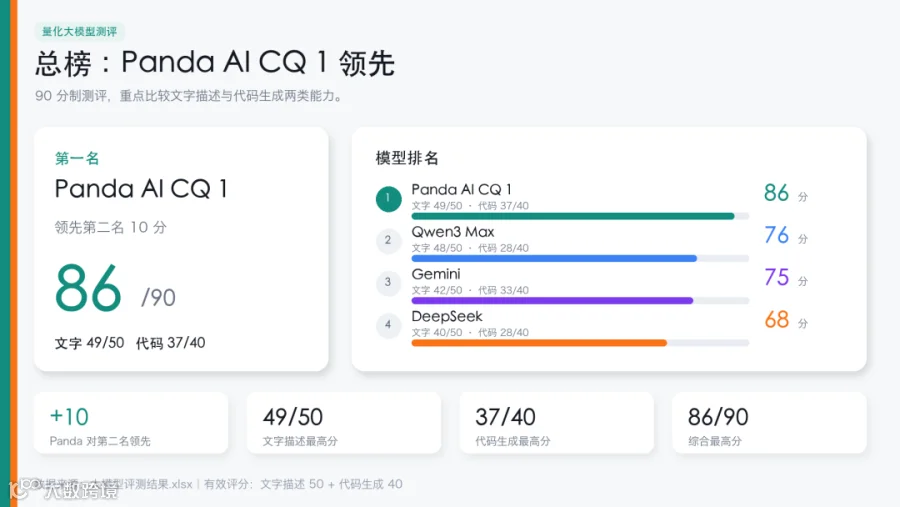
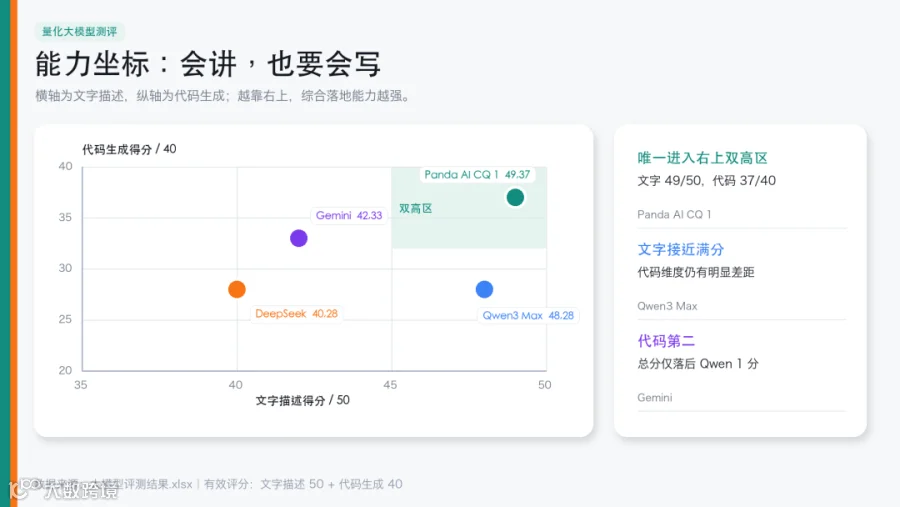
从结果看,CQ1 在金融解释类和量化代码类任务中都有较稳定表现;说明在这组金融任务中,CQ1 展现出了更强的垂类适配能力。

在这组任务中,PandaAI CQ1 的总分为86。
DeepSeek:金融解释类 40|量化代码类 28|总分 68
Gemini 3 Pro:金融解释类 42|量化代码类 33|总分 75
Qwen3 Max:金融解释类 48|量化代码类 28|总分 76
PandaAI CQ1:金融解释类 49|量化代码类 37|总分 86
具体包括以下测评任务:
第一组是金融解释类任务,共 5 项:
T1 指标解释
T2 滑点成因
T3 过拟合识别
T4 市场中性
T5 时间序列模型
第二组是量化代码类任务,共 4 项:
C1 因子实现
C2 策略实现
C3 因子修复
C4 策略修复


金融垂类模型的潜在价值,在于用更高的性价比提升链路的基础质量;让模型默认在金融语境中处理金融问题;用更低的算力、更快的速度,产出更稳定的内容。
在 AI 投研和 AI 交易里,很多环节都可以被拆开:
数据分析可以做成 Skills,
特征工程可以做成 Skills,
因子分析、多因子组合、组合优化,也都可以进入更标准的流程。
RAG 解决数据来源,Harness 约束流程和边界。
但这些机制仍然依赖于模型去理解任务、生成上下文、产出代码;如果每一次金融任务都要靠的提示词反复纠偏,链路当然也能跑,但成本会变高,响应会变慢,确权压力也会变大。
CQ 与 TQ 模型
CQ 之外,PandaAI 也在推进 TQ。
CQ 更偏向投研和策略构建节点,关注金融解释和量化代码;TQ 则更靠近交易状态,关注短窗口、强反馈、状态变化下的判断;它们会在同一条 AI 投研/交易链路里,处理不同位置上的模型能力。

回到开头的问题:怎么判断一个金融 AI 的回答是不是足够专业?
重要的是看它在金融任务里,能不能持续稳定的处理边界,理解金融含义,产出可检查的解释和代码。

未来的 AI 交易里,人和 AI 会不断确权。流程越长,提示词越长,Skills 和 Agent 编排越复杂,确权成本就越高。人要确认的不只是“它有没有回答”,而是“它的理解是不是我的交易理解”。
模型层先用更高效率、更稳定的金融语境,把基础输出质量做上去;RAG 再处理数据来源;Skills 沉淀成熟动作;Harness 约束流程和边界。它们组合起来,才更接近一个可持续演进的 AI 投研/交易框架。



