

全网都在吹大模型能炒股,但这篇论文在跨越10年、6大类资产、3次史诗级股灾的真实回测中发现:90%的大模型在组合优化时完全无视“协方差”,其实盘夏普比率(Sharpe)连最简单的等权配置(1/N)都跑不赢!本文提出的 PORTBENCH 彻底揭开了LLM在风控与仓位执行上的遮羞布。
【论文信息卡片】
Title: PORTBENCH: A Correlation-Aware, Full-Pipeline Benchmark for LLM-Driven Portfolio Management
Source: arXiv Preprint, 2026
Code: 已开源 (完整评测数据集与开源代码链接已打包)

🎯 评测维度创新:打破以往“大模型只做单票涨跌预测”的伪命题,首次引入跨资产相关性(Correlation)和 CEPS(跨阶段错误传播分数),评估大模型在“市场感知-信号-组合优化-执行-风控”全生命周期的误差级联放大问题。
📊 数据与极端回测:精选183个真实底层资产(股、债、大宗、加密币等6大类),跨越2015-2025十年周期,硬核加入了2015年A股异常波动、2020疫情熔断、2022加密币崩盘三大“压力测试(Stress Test)”。
💰 真实的超额(打脸)业绩:在真实摩擦与风控约束下,10个前沿大模型在90%的测试场景中,其风险调整后收益(Sharpe)全部败给简单的等权重基准(EqW, 1/N);且在保守型约束下,60%的大模型在极端行情中直接无视最大回撤红线,发生爆仓级回撤。

当前 AI+Finance 的论文多如牛毛,但大多是在自欺欺人。它们的测试往往集中在单一资产(如纯股票池),完全忽略了真实基金经理最核心的技能:“跨资产相关性(Cross-asset Correlation)”。更离谱的是,现有评测多为单步QA预测,没有任何基准去衡量“投资决策链路的级联崩塌”——即如果大模型第一步宏观信号看错了,后续的仓位分配和风控会跟着错到什么离谱的地步?
如果大模型连马科维茨(Markowitz)均值方差优化里的“协方差矩阵”都看不懂,它凭什么管实盘资金?为了戳破这个泡沫,作者构建了首个相关性感知、全流程的投资组合管理(PM)基准——PORTBENCH。

作者为了拷问大模型,搭建了一套极度逼近私募FOF基金经理视角的双层(Dual-Layer)测试场:
数据构造(全天候资产库):特征集包含183个大类资产的日频价量、宏观指标(如 VIX、美债利差)及新闻文本。标签根据未来实际收益率和协方差生成的最优最大夏普权重。
核心架构(PORTBENCH 评测管线):
静态 QA 层:6269个考察资产相关性、VaR(在险价值)计算、最优仓位求解的硬核金融计算题。
动态五阶段沙盒(Dynamic Pipeline):在连续时间轴上,强迫 LLM 依次执行 S1 市场解读、S2 信号生成、S3 权重优化、S4 真实执行模拟(扣除10bps滑点与5bps佣金)、S5 风险监控(VaR与回撤触发)。并首创了 CEPS 指标,专门惩罚阶段间的“连锁翻车”。

展示从底层数据到动态五阶段投资决策流水线的架构图

文章对 DeepSeek、Qwen、GLM 等 10 个前沿大模型进行了跑分,得到了非常扎心的实盘真相:
“纸上谈兵”的高分:
在静态问答(QA)中,大模型算算数挺溜,但在动态回测中,30个模型-投资者配置组合里,有27个连无脑的等权(1/N)配置都跑不赢!
执行层大崩溃(Execution Collapse):
大模型根本无法有效利用“协方差矩阵”进行分散化对冲配置。它们给出的多资产权重高度同质化(趋近于平均分配),导致在 S4 执行层(换手率偏差)得分极低,实际资金曲线等同于被动躺平。
压力测试现原形(Stress Resilience):
在遇到2020疫情熔断、2022加密币崩盘时,暴露了极大的尾部风险。在保守型投资者画像(要求最大回撤控制在10%)下,尽管大模型表面上满足了所有的配置红线规则,但在压力测试发生时,有6个模型直接遭遇系统性大幅回撤,风控形同虚设。
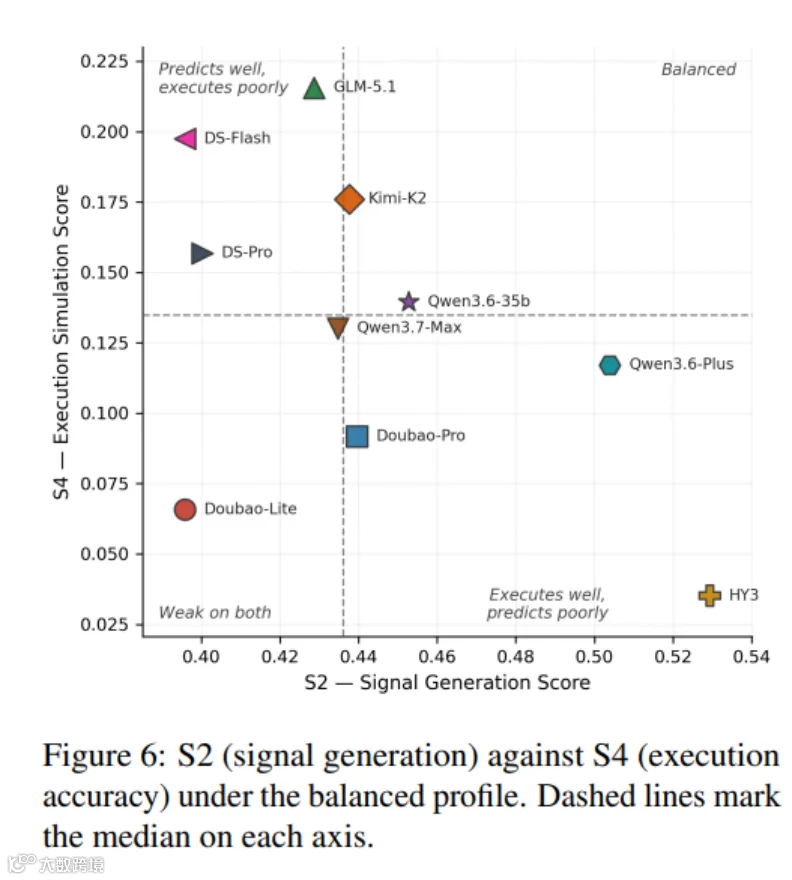
大模型信号准确率尚可,但执行层得分(S4)断崖式下跌,暴露信号生成与真实执行之间的巨大断层

🔥 落地价值评估(警惕 LLM 的 Alpha 幻觉):
这篇文章是对当前“盲目让大模型输出持仓权重”的一剂强力清醒剂。实盘中,大类资产配置(搞Beta)的真实难度远大于单票挖掘(搞Alpha)。大模型在处理非结构化文本(如新闻情绪提取)上很强,但对高维数值矩阵(协方差、相关性)极度缺乏数学直觉。在国内做宏观对冲(Macro/CTA),如果直接跳过传统优化器,让LLM直接生成端到端的持仓权重,无异于实盘自杀。LLM目前的定位只能是“约束条件转换器”或“风险状态预警器”。
⚠️ 避坑与局限性:
实盘摩擦可能被进一步低估:论文的测试环境设定为月频调仓,且只设定了单边总计 15 bps 的固定摩擦,这在流动性极好的美股ETF上尚可。但如果放在A股微盘股或高波动的加密市场,真实的冲击成本(Market Impact)与滑点远不止于此,LLM的实际表现只会更加惨烈。
缺乏领域强化微调(RLHF for Quant):参与测试的都是通用大模型。通用模型天生倾向于给出“中庸、平滑”的输出(导致持仓权重同质化)。如果不通过针对金融约束的专门强化学习(RLAIF)或引入外部传统的优化器(如 CVXPY)作为工具调用(Tool-use),单纯靠 Prompt Engineering 永远无法让 LLM 学会真正的现代投资组合理论(MPT)。
大模型写代码是一把好手,但真到了掏真金白银做仓位管理的实盘,连 1/N 等权基准都打不过?这篇论文的评测框架绝对是量化团队检验内部大语言模型是否真正具备“金融常识”的必备试金石!
本期论文原文 PDF 及完整评测数据集与开源代码链接已打包完毕。
获取方式:关注本公众号,后台回复【AI因子】,即可获取免费完整资料。
文案:Peom
编辑:孑孓乐



