
Red Hat AI 今天放出了 GLM-5.2 的 DSpark 投机解码模型。这不是 DeepSeek,是第一个非 DeepSeek 前沿模型用上 DSpark 架构的投机解码器。
DSpark 是基于 DFlash 并行草稿骨干,加上一个 Markov logit-bias 头和一个逐位置置信度头。简单说,就是让一个小模型(3B 参数)快速生成多个候选 token,大模型(GLM-5.2-FP8)一次验证一批,省掉逐 token 串行解码的时间。
项目分两个阶段:先放了个 preview 检查点(3 epoch,50k UltraChat 数据),然后训练了更完整的 epoch-1 检查点。epoch-1 用全词汇草稿(154,880 token)和 Magpie+UltraChat 再生数据,效果直接拉高了一截。
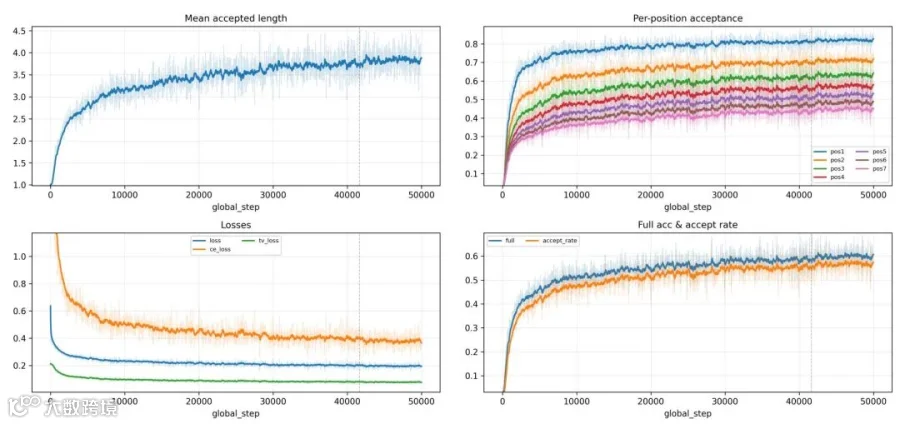
上图是 epoch-1 训练过程中的指标:平均接受长度(Mean accepted length)稳定在 3.4 左右,各位置接受率(Per-position acceptance)从 pos1 的 78% 平滑下降到 pos7 的 38%,说明 Markov 头有效抑制了后缀衰减。
实际加速多少?
在 4×B300 上,base model 无投机解码跑 102 tok/s。挂上 preview 检查点,提升到 139 tok/s(1.36x)。换上 epoch-1 检查点,直接干到 219 tok/s(2.15x)。平均接受长度从 2.18 涨到 3.49——意味着每次大模型前向传播能确认 3.49 个 token,而不是 1 个。
对比数据:
| 检查点 | 平均接受长度 | 解码速度 |
|---|---|---|
| 无投机 | 1.0 | 102 tok/s |
| preview | 2.18 | 139 tok/s |
| epoch-1 | 3.49 | 219 tok/s |
怎么用?
需要 vLLM nightly 版本:
uv pip install vllm --extra-index-url https://wheels.vllm.ai/nightly
vllm serve zai-org/GLM-5.2-FP8 \
--tensor-parallel-size 4 \
--max-model-len 16384 \
--trust-remote-code \
--speculative-config '{
"model": "RedHatAI/GLM-5.2-speculator.dspark",
"num_speculative_tokens": 7,
"method": "dspark",
"draft_sample_method": "probabilistic"
}'注意 --speculative-config 里的 model 路径指向 Hugging Face 上的仓库。如果只想尝鲜 preview,把模型名换成 RedHatAI/GLM-5.2-speculator.dspark-preview。
一点观察
投机解码这两年从学术玩具变成实用工具,但之前 DSpark 几乎只绑在 DeepSeek 上。Red Hat AI 这次把它移植到 GLM-5.2,说明架构本身是通用的——只要草稿模型训练到位,任何大模型都能白嫖 2x 加速。训练数据用 base model 自己生成的 response(self-play 思路),也降低了数据准备门槛。
epoch-2 和 epoch-3 还在训练中,按这个趋势,最终检查点可能把接受长度推到 4 以上。对于跑 GLM-5.2 推理的团队,这大概是近期最划算的优化——不用改模型,加个 3B 草稿模型就能省一半 GPU 时间。
模型和代码都是 MIT 协议,可以随便用。训练 pipeline 基于 speculators 库,也在 GitHub 上开源了。
关注公众号回复“进群”入群讨论