

就在最近,Google DeepMind正式发布了Gemma 4 12B模型。消息一出来,不少开发者社区直接炸锅了。原因很简单——这可能是目前最接近“人人都能用得起的多模态AI模型”之一。更重要的是,它还带来了一个新概念:统一无编码器(Encoder-Free)架构。
听起来有点绕,但它背后代表的变化,可能会影响未来几年的AI发展方向。

AI为什么越来越像“乐高积木”?
目前大多数多模态AI模型,其实都是“拼装”出来的。比如你给AI上传一张图片,图片先经过一个视觉编码器(Vision Encoder)翻译成机器能理解的数据,再交给大语言模型分析。
如果是语音,还要先经过音频编码器处理。整个流程有点像:图片→翻译员→AI;语音→翻译员→AI;文字→AI。虽然这种方式已经用了很多年,但问题也很明显:组件越来越多;部署越来越复杂;运行成本越来越高;延迟也会增加。
于是Google开始尝试新的思路。既然最后都是给AI理解,为什么不让AI直接学会理解图片、声音和文字?Gemma 4 12B就是在这个思路下诞生的。它取消了独立视觉编码器和音频编码器,采用统一Transformer架构处理各种信息。
简单理解就是:以前需要三个部门协作,现在直接让一个全能员工自己完成。对于开发者来说,这意味着部署更简单,资源占用更低,效率更高。
12B参数,为什么大家这么激动?
如果放在前几年,12B参数根本算不上什么大模型。毕竟动不动就是几百亿、几千亿参数。但现在行业开始明白一个道理:参数越大,不一定越好。真正有价值的是:性能和成本之间的平衡。
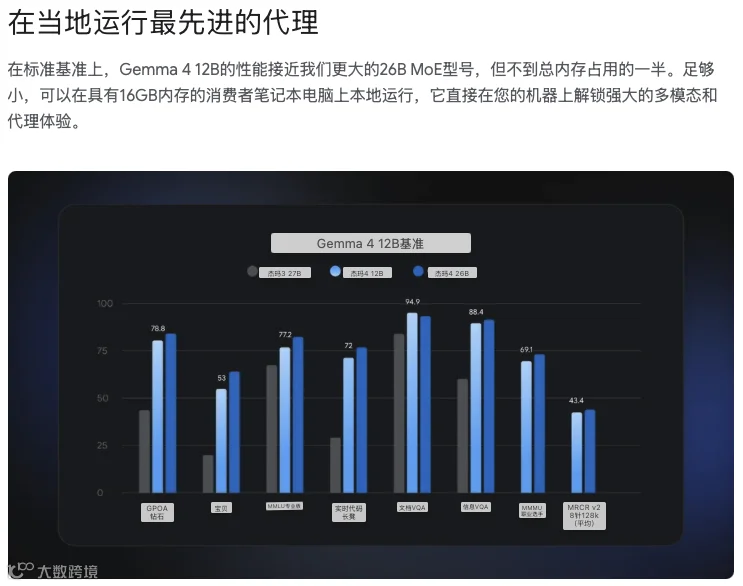
Google官方数据显示,Gemma 4 12B在多个基准测试中的表现已经接近甚至超过上一代27B级别模型。换句话说:以前需要27B模型完成的任务,现在12B就能搞定。而且部署成本直接下降了一大截。这就好比以前需要一辆大卡车拉货,现在一辆小货车就能完成同样工作。

对于企业来说,这意味着更低的服务器投入。
对于个人开发者来说,这意味着普通电脑也有机会跑高性能AI。
普通笔记本也能运行AI了?
这可能是Gemma 4 12B最吸引人的地方。Google官方表示:16GB内存设备即可运行。很多人看到这里可能没概念,简单来说就是,MacBook Air、MacBook Pro、Windows轻薄本这些都已经达到这个配置。
过去部署一个多模态AI模型,往往需要昂贵显卡,现在很多开发者直接在自己的电脑上就能体验。这也是为什么社区评价非常高。因为AI正在从“云端专属”逐渐走向“人人可用”。
未来很多企业内部知识库、客服机器人、文档分析工具甚至自动化Agent,都有机会在本地完成部署。数据不用上传云端,隐私和安全性也更容易保障。
AI越来越强,但网络环境依然重要
这里其实有一个很多企业容易忽略的问题。现在越来越多团队开始接触海外AI工具,比如ChatGPT、Gemini、Claude、Perplexity等,模型本身越来越强大,但如果网络环境不稳定,依然会影响实际使用体验。
尤其是跨境电商、外贸公司、海外广告投放团队以及跨境运营团队,经常会遇到:账号风控;IP频繁变动;访问速度慢;地区识别异常;多人协同办公困难等问题。对于需要长期稳定使用海外AI工具和海外平台的企业来说,选择合规、稳定的跨境网络环境同样重要。
我们推出的E SD-WAN跨境网络解决方案,提供独享IP、SD-WAN智能选路以及企业级跨境专线服务,支持多团队协同办公,不限流量,能够满足AI办公、海外广告投放、跨境电商运营等场景需求,让企业在使用海外数字化工具时更加稳定高效。有需要的朋友可以后台私信添加客服咨询哦~
Google在下一盘什么棋?
如果只看参数规模,Gemma 4 12B并不算行业最大的模型,但如果看技术路线,它可能代表着Google未来的重要方向。
过去几年行业竞争主要集中在:谁更大。而未来几年竞争重点很可能变成:谁更高效、谁更容易部署、谁更适合落地。
从Gemma 4 12B身上可以看到一个明显趋势:AI正在从实验室走向企业;从云端走向本地;从专业玩家走向普通开发者。对于Google来说,这不仅仅是发布一个新模型,更像是在推动下一代AI生态建设。
很多人第一次看到Gemma 4 12B时,会觉得它只是又一个开源模型,但实际上,它真正值得关注的地方并不是12B参数,而是Google首次把统一无编码器多模态架构带到了一个普通电脑就能运行的开源模型上。这意味着未来的AI可能不再需要复杂的模块拼接,也不一定需要昂贵的硬件支持。
对于开发者来说,这是一个更低门槛的新时代;对于企业来说,这是AI真正开始普及的信号,而对于整个行业来说,Gemma 4 12B或许会成为多模态AI从“堆参数”走向“拼效率”的一个重要转折点。