
目前,DeepSeek团队在 Hugging Face 上开源了 DSpark 增强版的模型检查点(DeepSeek-V4-Pro-DSpark,DeepSeek-V4-Flash-DSpark),并在 GitHub 上发布了 DeepSpec 开源仓库,用于推测解码算法的草稿模型训练和评估。

-
github链接: https://github.com/deepseek-ai/DeepSpec
-
huggingface: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark/tree/main
https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash-DSpark/tree/main
01
DSpark整体架构
DSpark 的整体设计围绕推测解码的核心公式展开:单 token 平均延迟取决于草稿耗时、验证耗时和每轮可接受 token 数。
传统自回归草稿模型可以利用前文 token 逐步生成,因此接受率较高,但草稿时间会随候选块长度线性增加;并行草稿模型可以一次性生成多个候选 token,草稿延迟几乎不随块长增加,却因为每个位置独立预测,容易产生“of problem”“no course”这类跨模式混合,导致后缀 token 接受率下降。
DSpark 的方法就是让草稿“前半段像并行模型一样快,后半段像自回归模型一样懂上下文”。
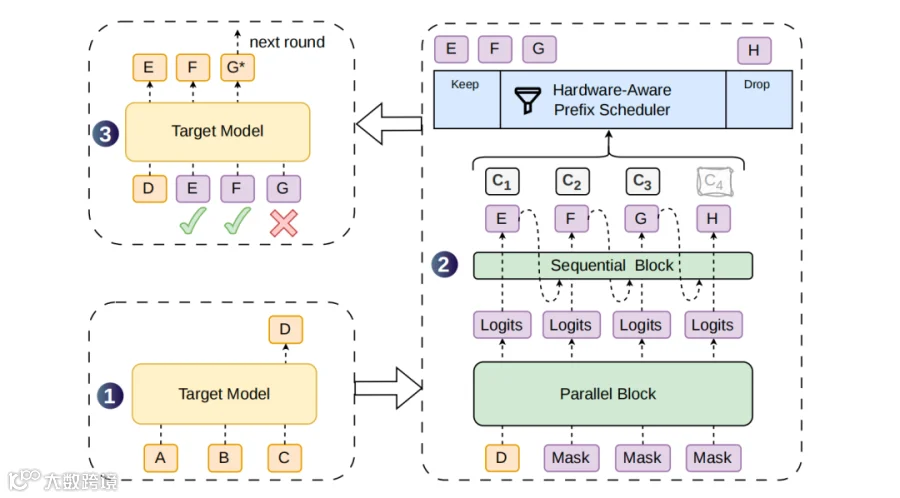
图 1|DSpark 架构与解码循环。 给定提示词 token ABC,目标模型先执行一步生成下一个 token D,该 token 会作为草稿生成阶段的锚点。随后,DSpark 以 D 作为输入,使用一个较重的并行主干网络和一个轻量级的顺序头,生成草稿 token EFGH,并同时给出它们对应的置信度分数 c1–c4。接着,硬件感知前缀调度器会评估这些置信度分数,保留前缀 EFG,并丢弃低置信度 token H。最后,目标模型会并行验证这个被调度后的前缀。如图所示,E 和 F 被接受,而 G 被拒绝,因此模型会生成一个校正后的 token G*,从而完成当前这一轮解码。
在半自回归生成中,DSpark 将草稿过程拆成两个阶段。
第一阶段是并行阶段,采用 DFlash 作为并行骨干网络,一次前向生成整个草稿块的隐藏状态和基础 logits。与原始 DFlash 不同,DSpark 不再使用“锚点 token + γ 个 mask token”来预测 mask 位置,而是把上一轮目标模型生成的 anchor token 本身也作为第一个预测位置,因此只需要输入“anchor + γ-1 个 mask”,即可得到 γ 个草稿 logits,从而减少草稿计算量并保持草稿质量。
第二阶段是轻量顺序阶段。并行骨干给出的基础 logits 只反映每个位置的边际预测,DSpark 进一步为每个位置加入一个与前缀相关的 transition bias,使当前位置不仅看并行骨干的输出,还能条件化于块内已经采样出来的 token。研究团队给出两种实现。默认使用 Markov head,它只依赖上一个 token,通过低秩矩阵分解近似完整的词表转移矩阵,默认秩为 256。这样,当前一个 token 采样为 “of” 时,顺序头会提高 “course” 的概率、压低 “problem” 的概率,从而缓解并行预测的多模态碰撞。另一种是 RNN head,它维护一个块内循环状态,将历史前缀、上一个 token embedding 和并行骨干隐藏状态拼接后做门控更新,能捕获更长范围的块内依赖。实验发现 RNN head 只有小幅额外收益,因此默认采用更简单、更适合部署的 Markov head。
除了生成更好的草稿,DSpark 还强调“验证得更聪明”。并行草稿可以轻松生成较长候选块,但不是每个候选 token 都值得交给大模型验证。尤其在高并发服务中,低置信度后缀 token 很可能被拒绝,却会占用目标模型 batch 容量。为此,DSpark 引入 confidence head,为每个草稿位置输出一个置信度分数,估计该 token 在前面所有 token 已被接受的条件下,继续通过目标模型验证的概率。训练标签不是人工标注,而是由草稿分布和目标分布之间的 total variation distance 解析得到:两者越接近,该位置被接受的概率越高。
由于调度器需要使用置信度的绝对数值,而不仅仅是排序,研究团队进一步提出 Sequential Temperature Scaling 做后验校准。它按位置从左到右校准累积前缀存活概率,使预测概率更接近真实接受率,并降低过度自信带来的调度误差。
在硬件感知前缀调度器中,DSpark 将验证长度选择建模为系统级吞吐最大化问题。算法如下所示:

对于一批 R 个请求,调度器先计算每个请求每个候选位置的前缀存活概率,即前面所有条件置信度的累乘;然后将所有候选 token 按存活概率全局排序。与此同时,系统会预先测量不同 batch size 下目标引擎的 steps per second 曲线 SPS(B)。调度器在增加验证 token 时,同时估计“多接受 token 带来的收益”和“batch 变大导致的吞吐损失”,最终选择使系统总吞吐 τ·SPS(B) 最大的验证预算。理论版本中,算法通过早停保证调度决策不依赖未来 token,从而保持推测解码的无损分布恢复;生产部署中,DSpark 又将调度改成异步形式,用两步之前的预测估算容量上限,避免阻塞 CUDA graph 和 Zero-Overhead Scheduling,同时仍按当前真实置信度做 top-K 选择。
训练方面,目标模型全程冻结,草稿模型共享并冻结目标模型的 embedding 层和语言模型头,只训练并行骨干、顺序头和置信度头。损失函数由三部分组成:交叉熵损失(cross-entropy loss)用于预测真实 token,分布匹配损失(distributionmatching loss )用于拉近草稿分布和目标分布,置信度损失(confidence loss)用于训练 confidence head。三项损失都按位置加权,越靠前的位置权重越高,因为前缀式验证中前面 token 对最终接受长度影响最大。默认权重为 CE 0.1、TV 0.9、confidence 1.0。
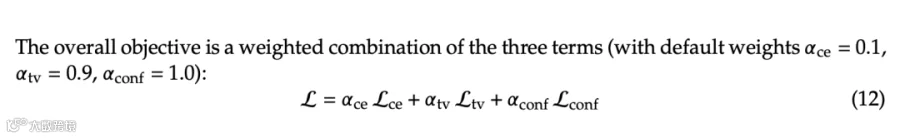
02
对比实验与结果分析
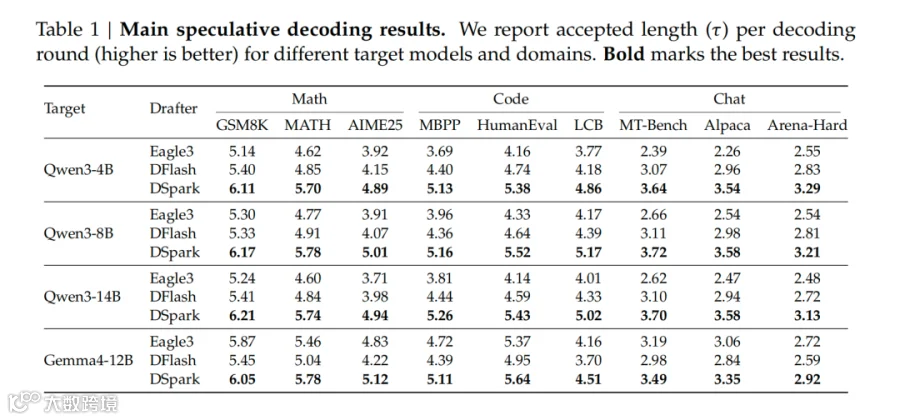
如表1所示,DSpark 在所有目标模型和所有任务域上都优于自回归基线(Eagle3)和并行基线(DFlash)。在Qwen3-4B、8B、14B 上,DSpark 相比 Eagle3 的宏平均接受长度分别提升 30.9%、26.7%、30.0%;相比 DFlash 分别提升 16.3%、18.4%、18.3%。
实验还显示任务类型会明显影响接受长度:结构化的数学和代码任务更容易维持较高接受率,而开放式聊天的后缀 token 更容易被拒绝,这也进一步证明固定验证长度会造成计算浪费。
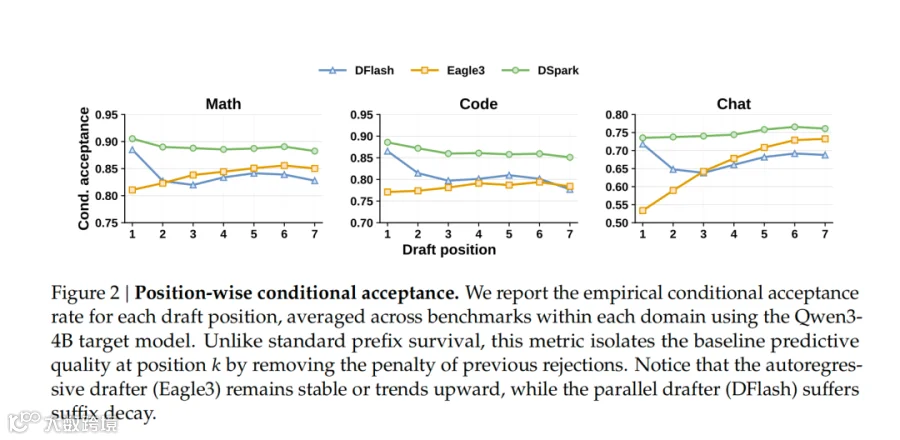
研究团队进一步用位置级条件接受率解释 DSpark 为什么有效。DFlash 虽然是并行模型,但由于可以使用更深网络,在第一个草稿位置上往往强于 Eagle3,例如 Qwen3-4B 上数学任务第 1 位接受率约 0.88 对 0.81,聊天任务约 0.72 对 0.53。然而 DFlash 后缀衰减明显,代码任务从约 0.87 降到 0.78,聊天任务从约 0.72 降到 0.63;Eagle3 则因为逐步条件化,后面位置反而更稳定,聊天任务可从 0.53 升到 0.74。DSpark 的优势在于同时继承二者长处:第一个位置具备并行骨干的高容量,后续位置又通过顺序头补充局部依赖,因此整体条件接受率更高、更平稳。
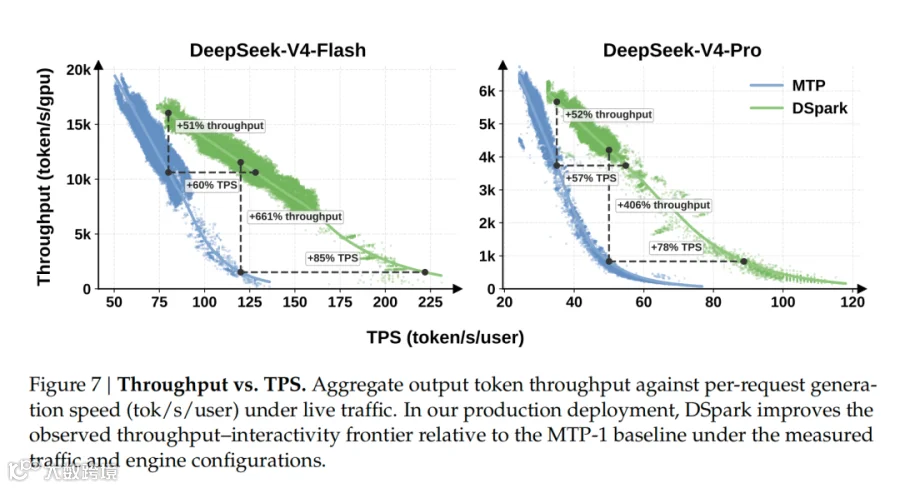
研究团队将 DSpark-5 (配置最大草稿长度 γ=5)部署到 DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 预览版服务中,与此前生产基线 MTP-1 对比。结果显示,在 V4-Flash 上,当服务等级要求为 80 tok/s/user 时,DSpark 聚合吞吐提升 51%;在更严格的 120 tok/s/user 下,MTP-1 已接近运行边界,DSpark 取得名义上 661% 的吞吐优势。更稳健的对比是,在相同实用吞吐水平下,DSpark 将单用户生成速度提升 60%–85%。在 V4-Pro 上也呈现同样趋势:35 tok/s/user 下吞吐提升 52%,50 tok/s/user 下名义吞吐优势为 406%,相同系统容量下单用户生成速度提升 57%–78%。
从并发负载分析看,DSpark 的硬件感知调度器会自动调整验证预算。在中等并发下,系统还有可用算力,调度器会把 MTP-1 固定的 2 token 验证扩展到约 4–6 token,从而提高每次前向的有效生成量;当并发继续升高、目标模型容量趋于饱和时,调度器又会平滑缩短验证长度,优先保留高置信度 token,避免低价值后缀挤占 batch 资源。
END
✦
✦
2026中国AI智能体大会
✦
智猩猩主办的2026中国AI智能体大会7月2-3日杭州举行,大会设有开幕式,企业级AI智能体、AI智能体产品创新2场论坛,以及Coding Agent、自进化智能体、深度研究智能体、Computer-Use Agent、多智能体协同、Agent Skills、Agent Harness7场技术研讨会。最终议程已公布。










✦
✦
入群申请
✦

关注+星标,获取AI前沿进展与优质开源项目