
纵有武艺千百般,遇到中文全得完 。作为一个说普通话的R程序猿,今天给大家讲讲我遇到过的R与中文那些事儿。
简单整理了三个使用R初期遇到的问题:
· Ubuntu环境下Rstudio不能使用中文输入法;
· 数据文件读取中的中文乱码问题;
· 执行R script 中文乱码问题。
这三个问题看似简单,解决时却历经了一番周折,在这里整理出来与大家分享。
(一)Ubuntu环境下Rstudio中文输入
Rstudio是目前最受欢迎、用户最多的R集成开发环境,支持windows/Linux/Mac等多平台使用。Windows环境下Rstudio中文输入没有问题,但是在Linux环境下遇到了坑。下面简单说说Linux系统下Rstudio中文输入法配置问题。
本人使用的是Ubuntu16.04中文版操作系统,系统默认中文输入法是fcitx,Rstudio版本是1.0.136。
首先,Rstudio官方社区提供了一种解决方案(https://support.rstudio.com/hc/en-us/articles/205605748-Using-RStudio-0-99-with-Fctix-on-Linux)。官方工程师给出的解释是RStudio配套的Qt 5不支持fcitx,需要将系统fctix的Qt 5配置文件ln到RStudio的输入配置文件夹下,具体操作如下:
$ sudo ln -s /usr/lib/$(dpkg-architecture -qDEB_BUILD_MULTIARCH)/qt5/plugins/platforminputcontexts/libfcitxplatforminputcontextplugin.so /usr/lib/rstudio/bin/plugins/platforminputcontexts/
经测试,该方法并不能解决问题。
在网上查了一些资料,了解到Ubuntu有两种输入框架ibus和fcitx,都支持中文输入。从Ubuntu 16开始,如果安装时语言环境选择中文,会默认安装fcitx框架。这样就确定了两个解决思路,一种是卸载fcitx,安装ibus;一种按照官方给出的思路使RStudio自带的Qt 5支持fcitx。
第一种方法比较简单,安装方法如下:
1.安装ibus框架
sudo apt-get install ibus ibus-clutter ibus-gtk ibus-gtk3 ibus-qt4
2.安装pinyin引擎,我用的是ibus-pinyin
sudo apt-get install ibus-pinyin
3.设置系统输入法
sudo im-config
看别人的教程,这里都是用im-switch来切换输入框架。然而在我实践的时候,一直提示“im-switch: command not found”,找了好多教程都无法解决,于是改用im-config了。
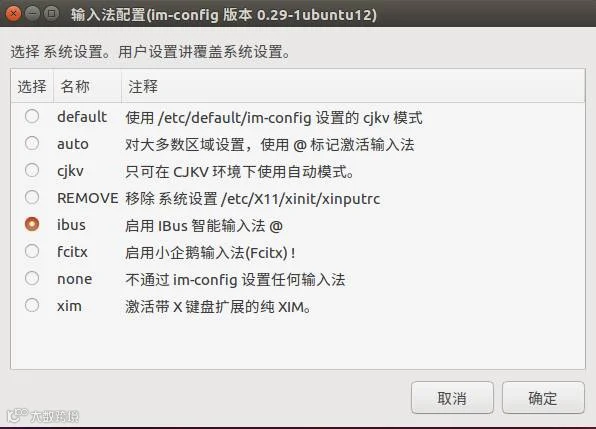
选择ibus为默认输入法。
4.卸载fcitx
sudo apt-get --purge remove fcitx
sudo apt-get auto remove
经测试,现在可以在Rstudio中输入中文,但操作过程中应注意:一定要先安装ibus再卸载fcitx,若顺序搞反会出现系统无法启动!无法启动!无法启动!(重要的事说三遍)
第二种方法
由于本人不懂Qt 5,第二种方式在网上找了好久,最终找到了一个日文博客(http://blog.goo.ne.jp/ikunya/e/8508d21055503d0560efc245aa787831)阅读日文无能,只能看懂命令,就把命令贴在这里吧:
wget http://ikuya.info/tmp/fcitx-qt5-rstudio.tar.gz
tar xf fcitx-qt5-rstudio.tar.gz
cd fcitx-qt5-rstudio
sudo apt install ./fcitx-frontend-qt5-rstudio_1.0.5-1_amd64.deb ./libfcitx-qt5-1-rstudio_1.0.5-1_amd64.deb
经测试,此方法完美支持fcitx-pinyin输入。
现在Ibus框架和fcitx框架都支持中文输入,Ibus框架和fcitx框架下有不同中文输入引擎。Ibus除ibus-pin外,有ibus-googlepinyin/ibus-souhupinyin ; fcitx除fcitx-pinyin还有fcitx-sougoupinyin ,大家可以根据个人喜好选择输入引擎。本人习惯使用搜狗输入法所以采用了第二种方法。
(二) 数据文件读入中文乱码问题
在用R处理中文数据时,经常遇到数据文件中,中文字符读入乱码的情况,这是由于数据文件的编码格式和R运行环境默认的编码格式不兼容所导致。
举个例子,本人使用的是Ubuntu16.04中文版操作系统,系统默认编码格式为UTF-8,R-core为3.2.5,Rstudio版本为1.0.136。下面是一个GB2312编码的txt文件:
time
V1
V2
2013/7/1 星期一 上午 0:00:02
FALSE
8.11
2013/7/1 星期一 上午 0:00:10
FALSE
8.1
2013/7/1 星期一 上午 0:00:15
FALSE
8.23
2013/7/1 星期一 上午 0:00:23
FALSE
8.06
2013/7/1 星期一 上午 0:00:30
FALSE
8.22
2013/7/1 星期一 上午 0:00:38
FALSE
9.14
2013/7/1 星期一 上午 0:00:45
FALSE
8.32
2013/7/1 星期一 上午 0:00:53
FALSE
7.51
2013/7/1 星期一 上午 0:01:00
FALSE
7.42
代码及结果如下:
> y <- read.table("/media/cpf/TimCui/sanwen/test.txt",sep="\t",header=TRUE,stringsAsFactors = FALSE)
> y$time
[1] "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:00:02" "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:00:10"
[3] "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:00:15" "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:00:23"
[5] "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:00:30" "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:00:38"
[7] "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:00:45" "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:00:53"
[9] "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:01:00" "2013/7/1 \xd0\xc7\xc6\xdaһ \xc9\xcf\xce\xe7 0:01:08"
>
可以看到文件中的中文字符在读入时变成乱码,这个问题在只有少量数据文件的情况下,可使用文本编辑器如notepad++等将文件保存为UTF-8。
若是对批量文件进行处理,用文本编辑器显然不可行,查看了read.table帮助文档,发现其中的两个参数设置可以解决这个问题。具体如下:
fileEncoding
character string: if non-empty declares the encoding used on a file (not a connection) so the character data can be re-encoded. See the ‘Encoding’ section of the help for file, the ‘R Data Import/Export Manual’ and ‘Note’.
encoding
encoding to be assumed for input strings. It is used to mark character strings as known to be in Latin-1 or UTF-8 (see Encoding): it is not used to re-encode the input, but allows R to handle encoded strings in their native encoding (if one of those two). See ‘Value’ and ‘Note’.
从文档说明看出,fileEncoding可以控制数据源文件的编码格式,encoding控制R运行环境的编码格式,只需将这两个参数设置为数据文件的编码格式(GB2312)就可以解决这个问题,具体代码及结果如下:
> y <- read.table(file = "/media/cpf/TimCui/sanwen/test.txt",sep="\t",header=TRUE,stringsAsFactors = FALSE)
> y <- read.table("/media/cpf/TimCui/sanwen/test.txt",sep="\t",header=TRUE,stringsAsFactors = FALSE,encoding = "GB2312",fileEncoding = "GB2312")
> y$time
[1] "2013/7/1 星期一 上午 0:00:02" "2013/7/1 星期一 上午 0:00:10" "2013/7/1 星期一 上午 0:00:15"
[4] "2013/7/1 星期一 上午 0:00:23" "2013/7/1 星期一 上午 0:00:30" "2013/7/1 星期一 上午 0:00:38"
[7] "2013/7/1 星期一 上午 0:00:45" "2013/7/1 星期一 上午 0:00:53" "2013/7/1 星期一 上午 0:01:00"
[10] "2013/7/1 星期一 上午 0:01:08"s
(三)R script 执行中文乱码问题
关于中文编码遇到的另外一个问题是,R script编码格式与R运行环境编码格式不一致。因为我会在Windows 10和Ubuntu 16之间切换编写R script,Rstudio保存R script的默认编码格式与系统的默认编码格式,而Windows 10和Ubuntu 16的编码格式并不相同(Windows为CP936、Ubuntu为UTF-8)。
为了解决跨系统打开R script乱码问题,我将R script统一保存为UTF-8格式,但是这样在windows 10 下会导致另外一个问题——R script 执行中文乱码。
1.编写一个 R script 保存为UTF-8,内容如下:
#编码测试
testFun <- function(){
print("编码测试")
print("编码测试")
}
2.Source这个文件,然后调用testFun函数会出现中文输出乱码
testFun()
[1] "缂栫爜娴嬭瘯"
[1] "缂栫爜娴嬭瘯"
此问题是由于R script 与 R运行环境编码格式不一致所导致,只需R script 与 R运行环境编码格式一致就能解决这个问题,由于上面的描述我不想修改R script编码格式,所以我修改了R运行环境的默认编码格式,可以使用option() 修改R环境变量,具体命令与结果如下:
> options(encoding = "UTF-8")
> getOption("encoding")
[1] "UTF-8"
> source("file:///C:/Users/17652/Desktop/test.R")
> testFun()
[1] "编码测试"
[1] "编码测试"
总结
简单将上面讲的问题总结一下,如下表所示:
问题
解决方法
Ubuntu环境下Rstudio中文输入
1)安装ibus框架,卸载fcitx框架
2)安装fcitx-qt5-rstudio补丁
数据文件读入中文乱码问题
通过设置read.table的encoding参数 和fileEncoding参数解决
R script 执行中文乱码问题
将R script 编码格式与R运行环境的编码格式设置一致即可
R中的中文乱码问题还有很多(如Rnotebook中文乱码问题等),其根源在于R运行环境字符流处理逻辑,以后有机会再和大家详聊。
来源:@昆仑数据K2Data