
大数据包含了海量、多维的数据,这些数据蕴含了巨大的价值。
大数据分析的任务就是从这些数据中发现其中隐含的价值。在处理大数据的应用场景中,我们需要根据分析任务的目标(即分析对象)建立大数据模型。
在本文中,我们简单将大数据模型抽象为如下的形式:
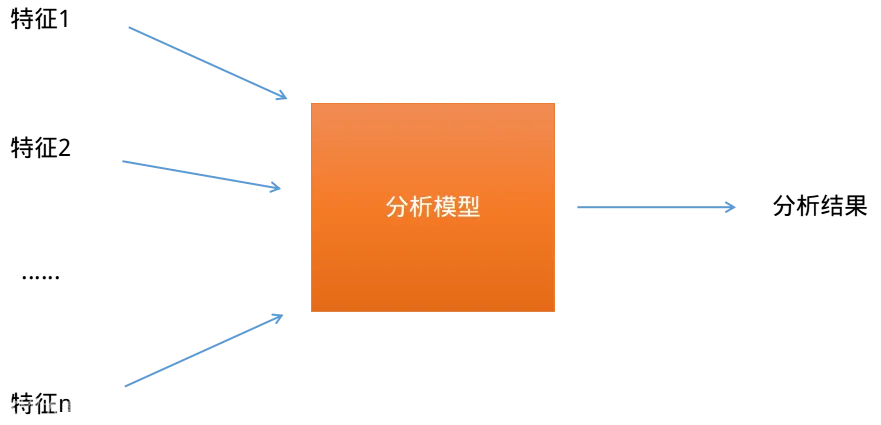
图一:大数据模型
大数据模型的输入部分是能够描述所分析对象的特征,这些特征来自于我们所掌握的海量、多维的大数据资源;分析模型能够以特征为输入,通过计算得到分析结果。在大数据的分析过程中,特征作为模型的输入,其数量、维度、组织形式等对于分析结果均起到关键作用。

本文将讲述大数据的应用场景中,从海量多维的大数据资源进行特征提取的过程,并对过程中所涉及到的相关因素进行介绍。
在图1的大数据模型中,分析模型包含了各种算法和计算模型,机器学习算法就是大数据模型中最常用的一类算法。基于机器学习的大数据模型的工作过程和人脑学习的过程类似,主要分为训练和分析两个阶段。训练阶段是根据已知的结果进行学习,建立模型的过程,就如同我们从事实经验中学习知识。分析阶段则是根据学习所得的模型,计算未知结果的过程。
例如,我们通过如下一组图片学习到各种图片所代表的事物类别(训练阶段)。当看到新的图片时,我们就可以得出图片中事物的类别(分析阶段)。机器学习算法的训练过程则是以图2中每个小图片作为输入,以图片所代表事物的类别作为输出,让图1中的模型不断的学习,使其能够具备判断同类事物的能力。分析阶段则能够基于上述能力判断新的图片所代表事物类别。

图二: 图片类别(数据来自于CIFAR-10 数据库)
在上述例子中,训练阶段和分析阶段所使用的数据输入为等尺寸的图片。在图片输入分析模型之前,我们需要对其中的特征进行提取。我们可以将图片“按像素展开”,每个像素点的颜色值均为一个特征,假设输入的小图片尺寸为30× 30像素,则一个小图片的特征就有900个,每个小图片代表1个样本。在图2所代表的图片库中共有100张小图片,通过特征提取我们能够得到100个样本,每个样本具有900个特征。每张小图片中像素(即特征)的内容方式不同,则其代表的事物就不同。
因此,对于大数据模型的特征,我们通常将其组织成为一个向量或矩阵,每个元素代表一个特征的数值。大数据模型的训练过程就是根据这些数据特征和其相对应的分类不断的迭代模型中的参数,直到存在一组参数,使模型的输入和输出对于特征和其对应的分类匹配的准确率达到要求。
特征提取更为通用的场景是,当我们描述某个特定的分析对象时,需要从相关的数据资源中获取能够描述分析对象的信息,其中的每个特征则类似于上述例子中的“像素点”,特征提取的任务就是要通过对多个来源、多个维度的数据的挖掘,描绘出能够表达分析对象的一张“特征图”。“特征图”中应该尽量多的包含与分析对象相关的信息,提升图的“分辨率”,同时,尽量去除与分析对象不相关的信息,减少“特征图”中的噪声,从而给分析模型一个正向的反馈,使其通过训练能够向接近“真相”的方向收敛。
大数据给我们描绘“特征图”提供了充分的素材。换句话说,在组织大数据资源时,我们应该尽量多的搜集与分析对象相关的数据,将不同来源的数据与分析对象关联起来,大数据的“多样性特征即体现于此。例如,在描述每月的商品销售量变化时,我们可以把当月的销售统计数据做为特征,同时,也可以引入外部的相关信息与每月商品销量关联,如当月的重大事件,当月的天气情况,微博中对于同类商品的关注度等。
除了从大数据的资源中提取特征之外,我们还需要从历史数据中提取到与分析对象对应的类别信息,给算法的训练确立“目标”。如图2中表示的数据集中,除了包含每张图片的像素信息之外,还包含每张图片所对应的分类。包含了完整的特征和分类信息的数据集合才能够用于算法的训练(无监督学习除外)。
我们可以使用各种统计学、业务(学科)知识,从大数据资源中提取特征。传统的数据挖掘的方法很多可以适用于对数据的特征提取,例如对分析对象的不同维度进行数据的钻取、旋转、回卷等操作。统计学中关于均值、方差、概率分布等知识也是特征提取的常用手段。事实上,特征提取并没有特定的方法,只要能够与分析对象关联,均可以用来作为特征。
然而,特征做为分析模型的输入,需要满足分析模型(机器学习算法)的要求。分析模型对于特征的要求主要有如下几个方面:
(1)特征的类型和取值范围:我们在提取特征时可能会采取不同的方法,对不同类型、来源的数据进行提取,会造成特征的取值范围不同和数据类型的差异。对于分析模型来说,取值范围不同代表着特征权重的差异,某些算法无法通过迭代消除这种差异,导致特征在权重上的误差(即在输入阶段就认为数值大的特征更重要);同样,分析模型对于数据的特征输入以及分类标签的数据类型有不同的要求,例如随机森林模型可以处理离散值和连续值类型的特征,SVM只能处理连续值类型的特征。因此,在特征输入模型之前,需要对其进行预处理,如归一化、连续化和离散化处理等。
(2)特征之间的关联性:由于我们在特征的提取过程中可能会使用到统计学的方法对原始的数据资源进行处理,在选取数据资源时也可能会有数据内容的重合,因此,特征之间可能会存在关联性。这种关联性可能会增加某个特征的权重,从而影响某些模型的训练过程和分析结果(例如线性回归算法对于特征之间的线性关联比较敏感)。因此,在特征提取的过程中,应尽量消除这种关联性。
(3)特征的维度和样本空间:在不提高特征关联性以及确保特征与分析对象相关的前提下,通常特征的维度越高,则代表了“特征图”的分辨率越大,能够更好的描述分析对象,对分析模型的训练过程有正向的影响。每一条完整的特征描述代表一个样本,样本空间指的是我们所能够从大数据资源中提取出的全部样本。对于机器学习算法,在样本分布均匀的情况下,通常样本空间越大,其训练的效果越好,得到的机器学习模型的准确率越高。
(4)特征的排列:对于一些通过局部感知进行分析的模型来说,特征的排列顺序至关重要。例如,在卷积神经网络进行图像识别时,如果图像分块排列顺序被打乱,在对边界附近的切片进行卷积时,会影响到其局部感知,导致准确率下降,如图3所示(除非所有的图片中分块都是以同样的顺序排列)。

图三:特征排列对算法的影响
特征提取是一个将原始数据(数据资源)映射到样本空间的过程,当映射建立起来后,我们就可以尝试使用训练样本对不同的机器学习算法进行训练,使用测试数据检验训练模型的性能,从而选取最优的算法和模型用于相应的场景。
来源:金智塔科技 作者:林琳
END
往期推荐:
[5] 马斯克警告:人类要想生存只有“人机合并”
不得不看的5本大数据热销书籍

+
2018工业大数据白皮书
+
工业大数据案例集
领取方式:关注公众号,对话框回复 118,即可免费领取
