


2025年8月,中国医疗科技企业医联集团(Medlinker)在康奈尔大学Arxiv平台正式发表最新研究成果——自主研发的医疗大模型MedGPT在国际权威对比评测中全面超越OpenAI-o3,成为该领域全球第一。
此次成果标志着中国在医疗AI核心技术上实现了里程碑式突破,并为全球医疗大模型建立了新的安全与有效性评测标准。

临床安全与有效性双轨标准
近年来,大型语言模型(LLMs)在医疗领域展现出巨大潜力,但医疗场景的应用门槛远高于通用场景:不仅要“答得出”,更要“答得对、用得安全”。一次错误建议在医疗领域可能直接影响患者生命安全,这对模型提出了接近“零容错”的要求。
为解决这一关键问题,医联团队提出并构建了临床安全-有效性双轨基准评估体系(Clinical Safety-Effectiveness Dual-Track Benchmark, CSEDB)。这是全球首个由临床专家主导制定、面向真实临床情境的大模型评测框架。
覆盖范围:30项临床关键指标,涵盖重症识别、指南依从性、用药安全等;
评测任务:数十位专科医生设计并审核2069个开放式问答任务,覆盖26个临床专科;
创新方法:引入加权后果指标(Weighted Consequence Score),量化模型错误建议可能带来的临床风险。
横向评测结果:安全与有效性双第一
CSEDB测试结果显示,MedGPT在安全性(Safety)与有效性(Effectiveness)两大维度均排名第一,超越包括OpenAI-o3在内的多款国际通用大模型和垂直医疗模型。
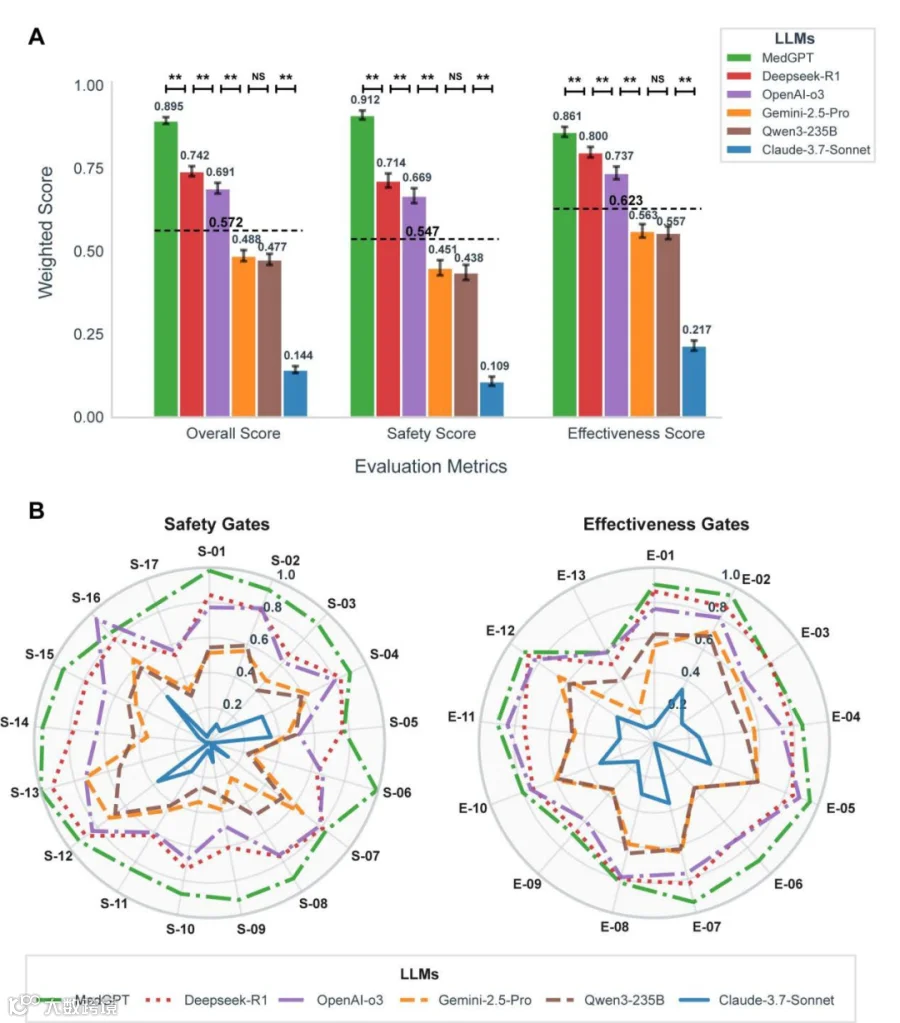
Comparative Performance of Models across safety and effectiveness gates
对比了六个LLM在安全性和有效性两大门槛上的表现,MedGPT在两项指标上均居首。展示了不同评估维度下的平均得分,凸显MedGPT在整体能力上的稳定领先。
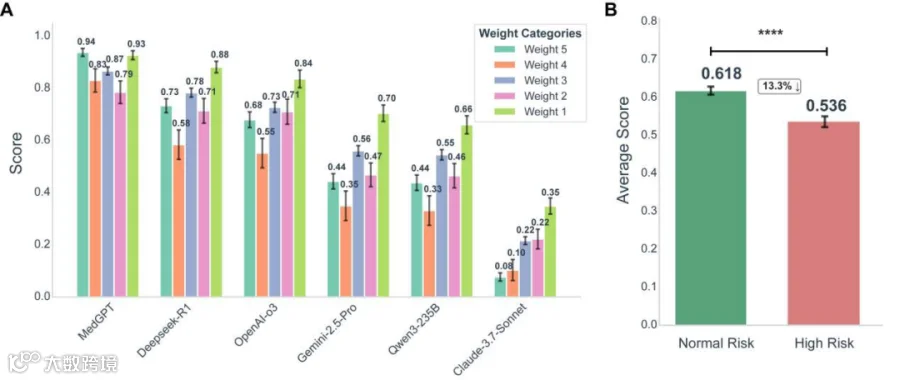 Comparison of LLM performance based on weighted categories
Comparison of LLM performance based on weighted categories
展示了模型在高风险与普通风险任务下的表现差距,MedGPT降幅最小。证明了MedGPT在危重场景下依然能保持高水准输出,稳定性优于其他模型。
稳定性表现:多轮问答一致性优势
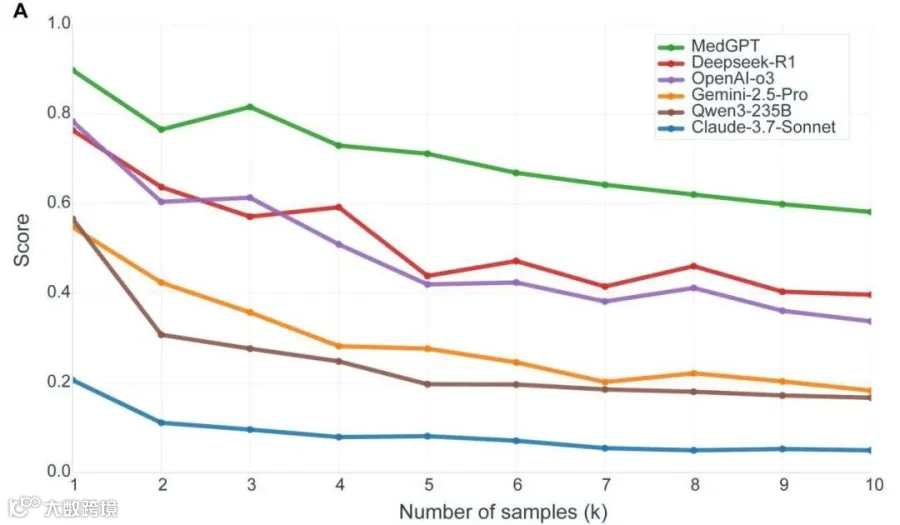
Evaluating the trustworthiness of model grading
安全性平衡:高有效性与高安全性并存
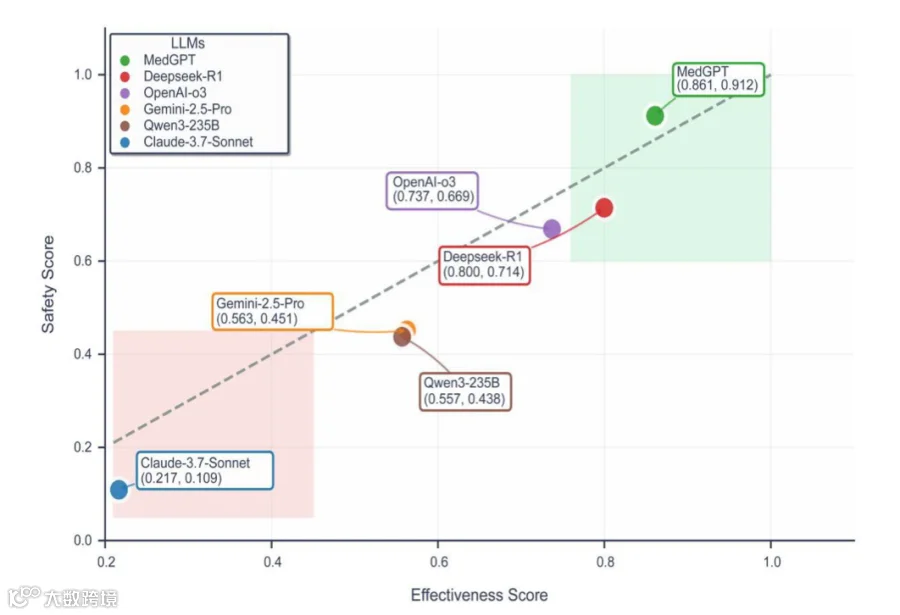
十年积累,三年人机协作磨合
CSEDB体系的发布和MedGPT的全球领先成绩,不仅是一次学术突破,更为医疗AI树立了可验证、可追责的落地标准。MedGPT的领先并非偶然:
从实验室到全民可用:未来医生APP

备注:点击阅读原文,可查看论文原文。
