

就医难、看病贵、诊疗过程耗费大量的时间和精力,一直是困扰广大患者和家属的难题。我国幅员辽阔、人口众多,医疗资源配置不均衡,优质医疗资源主要集中在一、二线城市的三级甲等医院中,低线城市和农村的医疗资源十分紧缺,患者就医的时间成本和经济成本都比较高,想要获得及时、准确、优质的医疗,更是难上加难。
因此,如果能够依托于优质医疗资源,依托科技的力量,建立起可靠、可信、便捷的线上诊疗制度,有望缓解三甲医院的诊疗压力,也能大大降低患者的就医成本,同时提升整体的医疗效率和诊疗质量。
近日,由医联自主研发的国内首款医疗大语言模型MedGPT发起了新一轮基于临床环境下的大规模真人模拟测试。医联邀请到20位主治医生组成了专家评测小组,在目标疾病的脱敏病历清单中抽取了200份有明确诊断意见的病历,邀请模拟患者与MedGPT的AI医生进行问诊交流,将MedGPT的初步诊断结果与真人主治医生的诊断结果进行对比。为了更加全面地评估MedGPT的表现,医联也将此次的测试结果与国内目前公开的三款主流医疗大模型产品进行了对比评估分析。
模拟测试结果显示,MedGPT初步诊断的准确率(命中率)达到了60.2%,相关率(命中率+相似率)高达84.4%,可以媲美专业医生的诊断水平,并显著优于另外三款主流医疗大模型产品的表现。
参与测试的专家评测小组表示,MedGPT通过与患者进行多轮沟通,收集到了足够的病情信息,确保了初步诊断的准确性,在医疗辅助领域非常有发展前景。目前MedGPT是唯一一个通过了大规模对照试验的医疗模型,而且诊断准确率非常让人惊喜。专家们一致认为:“MedGPT在医疗大模型领域已经迈出了重要的一步,给患者线上初诊提供了更多选择,也在智慧医疗领域取得了里程碑式的突破。”
MedGPT完成大规模真人模拟测试,线上初诊准确率让人惊喜
MedGPT于2023年5月正式发布,这款基于Transformer架构的医疗大语言模型聚焦于疾病预防、线上诊断、用药治疗、就诊后康复等全流程的智能化诊疗能力的提升,希望能在真实的医疗场景中发挥出更具效用的智能诊疗价值。
考虑到我国患者的就医痛点,医联在构建疾病测试数据集时,优先选取了我国患者常见和多发的疾病,按照发病率排序抽取病历,同时也兼顾了少部分危、急、重病,以确保本次真人模拟的测试结果能够反映出MedGPT在居家和远程问诊场景中的适用性。
本次测试抽取的200份病例中,大多数是患者经常在网络上咨询问诊的疾病。比如皮肤疾病、肠道疾病、心脑血管疾病等,也覆盖了婴幼儿常见病和中老年患者常见病。模拟患者通过线上文字输入的方式,向MedGPT旗下的AI医生“家小医”和其他三家同类型大模型描述病情,AI医生会在几轮问诊后做出初步诊断结果。如果模型的初步诊断结果与病例诊断结果一致,则认定该模型通过了测试。
在测试中,42岁的男性模拟患者向家小医提问:“很多天没有大便了,现在肚子很胀,2天前开始恶心呕吐”,家小医询问患者“近期有感觉到腹部疼痛吗”、大便的颜色和形状是否有改变,并要求患者描述疼痛的位置和性质,最后询问了患者是否有酗酒、肥胖、吸烟的习惯,在得到患者的回复后,家小医给出了“肠梗阻”的初步诊断,建议患者到消化内科或胃肠外科就诊。由主治医生组成的专家专家评测小组判断为“结果准确,诊断命中”。
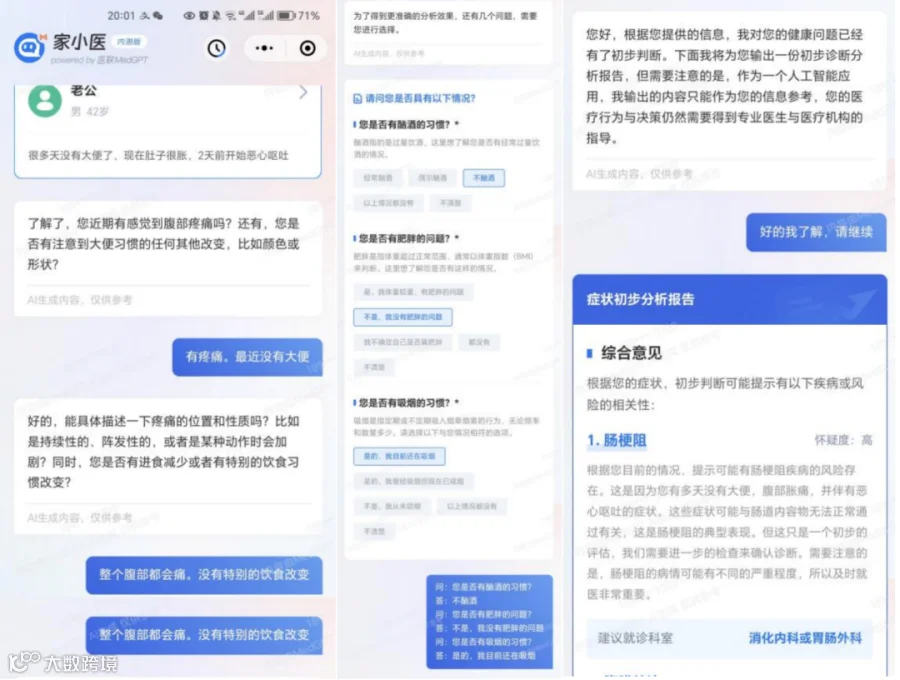
参与对比测试的医疗大模型产品A同样给出了“肠道梗阻”的正确诊断,但医疗大模型产品B则诊断为“便秘”,产品C诊断为“肠道功能紊乱或便秘”,均与患者的病情完全无关。
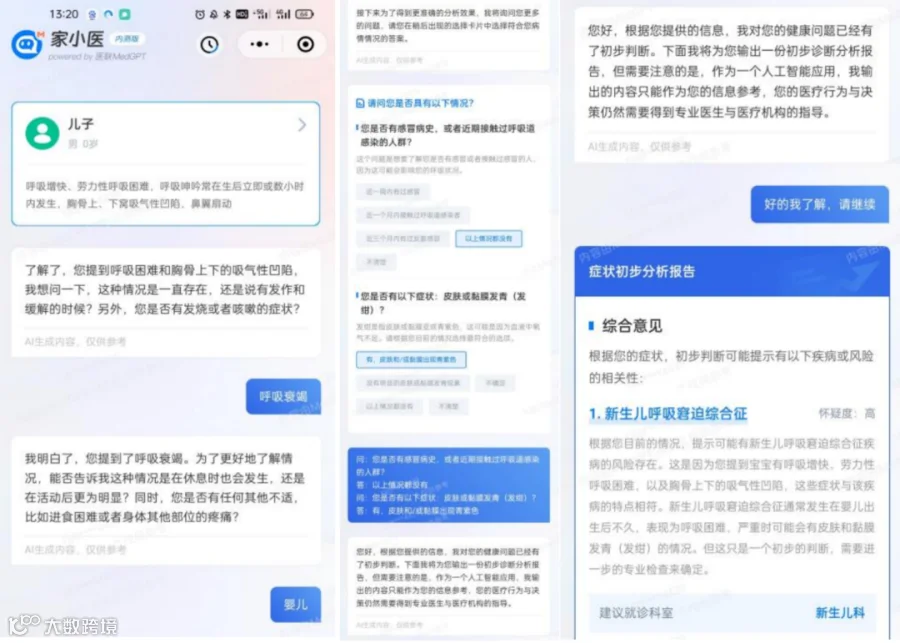
在面对急、重病症时,家小医的表现也十分优异,另一位模拟患者描述了婴儿“呼吸增快”、“呼吸呻吟”、“胸骨上、下窝吸气性凹陷”等症状,家小医与患者进行几轮沟通后,准确地给出了“新生人呼吸窘迫综合症”的诊断,并建议患者前往新生儿科及时就诊。
在对200份病历进行测试后,MedGPT家小医的诊断的准确率(命中率)达到了60.2%,与病情相关的诊断相似率为24.2%,在84.4%的情况下都可以为患者提供有效的就医辅助。而另外三款医疗AI产品的命中率分别为34.9%、36.5%、36.0%,相关率为75.8%、76.8%、67.7%,可以看出MedGPT在初步诊断命中率上处于行业内的领先水平。
命中率
|
相似率
|
相关率
(命中+相似)
|
无关率
(错误+未回答)
|
|
MedGPT
|
60.2%
|
24.2%
|
84.4%
|
18.6%
|
真人医生
|
45%
|
25%
|
70%
|
30%
|
医疗模型产品1
|
34.9%
|
40.9%
|
75.8%
|
24.2%
|
医疗模型产品2
|
36.5%
|
40.3%
|
76.8%
|
23.2%
|
医疗模型产品3
|
36.0%
|
31.7%
|
67.7%
|
32.3%
|
参与模拟测试的一位专家长期关注医疗大模型的研发进展,他指出:“根据我个人的了解,MedGPT可能是目前最准的医疗大模型。未来,像家小医这样的AI医生能够参与到智能化诊疗流程里,可以改善各地医疗资源不均衡的状况,也能给我们医生群体提供很大的帮助。”
顶级专家医生参与MedGPT研发,攻克诊断难点
近年来人工智能技术飞速发展,大语言模型也在各个领域中大展拳脚。然而在面对医学问题时,通用大语言模型在准确性上存在着天然缺陷,在问诊和用药时,通用大语言模型往往会轻率地给出结论,对患者起不到有效的帮助,甚至可能严重贻误病情。
对于医疗领域而言,准确性、可靠性是底线问题,医联的MedGPT聚焦于医疗垂直领域,累积了20亿医学文本数据、800万临床诊疗数据进行模型训练。在技术层面,MedGPT开创性地提出了快、慢双系统AI结构,将有意识、慢速的AI1.0和无意识、快速的AI2.0进行有机结合,实现对真人专业医生完整思维模式的有效模拟。
在模型的微调阶段,MedGPT采用⼤量真实医⽣参与的RLHF(Reinforcement Learning from Human Feedback,人类反馈增强学习)监督微调,来自华西医院、华山医院、北京大学第一医院、首都儿研所、中山医院、中山大学孙逸仙纪念医院等国内顶尖医院的医学专家共同参与研发、改进,增加了MedGPT的医学“含金量”,提升了AI医生的疾病特征判断能力和准确度。
模拟实验是检验AI诊疗产品有效性的关键标准,2023年7月,MedGPT举行了国内首次AI医生与真人医生的一致性评测,邀请到10位来自四川大学华西医院的主治医师和120余位真实患者进行评测研究,并进行全天候直播,最终形成了91份有效病例。经过来自北大人民医院、中日友好医院、阜外医院和友谊医院的7位专家教授的审核和评估,真人医生综合得分为 7.5分,AI 医生综合得分为 7.2分,MedGPT的AI医生诊断与三甲主治医生在比分结果上的一致性达到了96%,在业内处于领先水平,也与本次的真人模拟测试的表现相符。

值得一提的是,为了确保MedGPT进行线上初诊的可靠性,在真人模拟测试完成后,医联也请主治医生专家对32个错误诊断的案例进行了逐个分析。医生们一致认为,针对这样的疑难病历,真人医生往往也无法通过远程的简单问询,就能得出相对准确的诊断。在真实的就诊过程中,医生会要求患者在医院里完成各项指标检测,才能得出准确诊断。未来,MedGPT还会持续更新迭代,进一步提升初步诊断的可用性。
人类医生能否规避?
|
很难规避
|
能规避
|
||
误诊可能性
|
非常可能误诊
|
有可能误诊
|
不太可能误诊
|
完全不可能误诊
|
数量
|
7
|
17
|
7
|
1
|
MedGPT深耕医疗大语言模型,做医生的智慧AI助手
AI诊疗产品的想象空间有多大,取决于AI医生诊断的可靠度、可信度、一致性有多高。医联通过真人模拟测试以及与另外三款医疗AI产品进行对比,验证了MedGPT已经具备了通过问询方式给到患者较高准确率的问诊能力,对于医疗诊断的革新具备突破性的价值。
目前,MedGPT已经可以实现常见疾病咨询、紧急处理咨询、慢性病管理咨询、诊后康复咨询等功能。患者不用再依靠搜索引擎获取未经过滤的医学内容,在前往医院就诊前,也可以通过与AI医生的简单咨询得到相对准确的初步判断,大大降低了患者的就医成本和医院的诊疗压力。
据悉,医联与多位更高级别专家合作研发的AI医疗产品,将在数月后正式面世。
未来,医联将继续深耕大语言模型技术,持续提升AI医生在医疗领域的实际应用价值,争取覆盖常见病、急病和危重病的就诊需求,将医生从繁重的初级事务中解脱出来,更多地把精力倾斜到疑难重病的诊疗中。MedGPT将秉持着为医生服务的初心,成为医生诊疗过程中的“智慧AI助手”,为医疗行业的技术发展持续贡献科技力量。
