

三、根据内外部影响因素预测顾客流失
第二节是从购物时间间隔的角度预测顾客流失。当顾客超过预测的时间间隔还没来购物时,企业可以判定为其流失。
除此之外,我们也可以根据当期的顾客特征和企业营销情况(即表 4-1和表5-1中的数据),每期都预测顾客有多大的概率会流失。我们在预测的时候有两种思路:一种是基于各种内外部因素,直接预测顾客的流失概率;另一种是认为顾客存在一个基础的流失概率,各种内外部因素是在此基础概率上叠加影响。本节分别讨论这两种思路。
1、考虑各种因素对顾客流失概率的影响
第四章提到过直接预测顾客流失的模型,其核心思想是认为各种内外部因素X会影响顾客的流失概率。我们当时给出了概念性表达式,即式:

更复杂、更全面的形式如下所示:
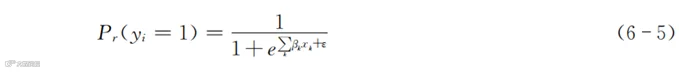
式中,Pr代表概率;yi=1代表顾客流失;yi=0代表顾客未流失。公式的含义是顾客i的流失概率与该顾客k个维度的情况有关。你可以把这k个维度理解成表4-1和表5-1中的k列。
我们已经知道y=1/(1+e^(-x))之类的函数可以把处于区间[-∞,0,∞]的x对应到取值范围为0~1的y。其核心是能够用一批已知其流失与否顾客的数据,拟合出βk(k∈[1,2,…])。也就是说,我们已知式(6-5)等号左侧(即某个顾客在某个时点流失与否),也知道等号右侧该顾客的xk(例如顾客在表5-1中各列的数值),需要找出等号右侧最适合这些数据的βk(就是常说的“拟合”)。当有足够多的行和列的顾客数据时,总能想办法算出相应的βk来。
为了便于理解,我们以表6-1的数据为例。要预测顾客在某个新的时间(可能是日、周、月)的状态是流失还是活跃,需要顾客在该时间对应的数据。这时,某个顾客的性别列到收入列属于静态信息,通常在较长时间内保持不变。而到店次数列到活跃时段列要根据新的时间重新计算一遍,其实就是用新的时间如表3-1那样的数据。标签信息列数据在新的时间有可能变化,也可能和原来一样。我们的任务目标是计算顾客在新的时间的流失概率,即Pr(yi=1)。当有了这个概率后,再设定一个阈值z,当Pr(yi=1)>z时,就可以判定顾客流失了。
表6-1的状态列显示顾客当期流失与否。也就是说,基于表 6-1现有的数据,我们既知道顾客流失与否(对比Pr(yi=1)和z),也知道各种影响流失的因素(从性别列到美妆达人列,一共12列),只是不知道式(6-5)中的参数βk。我们现在可以用某种统计方法(用软件计算),找到一套最合适的βk。通常判断合适的标准是误差最小。
有了对所有顾客都一样的βk(顾客之间如果没有明显差异,则无须分成不同的顾客群),同时我们也有某个顾客重新计算以后对应的Xk,即新的时间对应的表6-1中的某一行(对应某个顾客)从性别列到美妆达人列,一共12列的数据。有了式(6-1)右侧的所有数据,自然能够计算出其左侧的概率值,对应该顾客的流失概率。我们只要判断这个概率是否大于阈值,就能判断新的时间条件下顾客的状态,即新时间条件下表6-1中的状态列。
考虑各种因素对顾客流失的影响,还会有其他的表达式。其具体的形式也许跟式(6-5)不完全一样,但核心逻辑都差不多,即首先根据过去的数据,拟合出模型中的各种参数,然后根据要预测阶段的数据计算因变量(常常是概率)的值。实质仍旧是根据过去预测未来和根据群体预测个体。这与第二章提到的预测的基本思想相比并没有实质的变化。
2、考虑各种因素在已知流失概率上叠加影响
式(6-5)的核心思想是各种因素会直接影响顾客的流失概率。有时候,我们能从现有数据中知道顾客群的流失概率(例如15%)或者知道单一顾客过去阶段的流失概率。这时,可以用另一种思路来预测顾客的流失概率。
第二节提到的比例风险(PH)模型认为流失概率是在基础流失概率的基础上受到顾客个体特征和企业营销行为的影响。模型的核心表达类似于“动态流失概率=基础流失概率+受到顾客特征和企业营销影响的调节值”,表达式如下所示:

式(6-6)表示,顾客存在一个基础的流失概率λ0,最终的流失概率λ是在此基础上叠加各种内部(顾客)和外部(企业营销行为)影响因素X得到的。我们用大写X代表它包含很多小写x,每个x即为某个具体的影响因素(例如表6-1中的性别列到美妆达人列)。式(6-6)认为X通过λ0的指数位置影响λ。
从外观上看,式(6-6)的核心内容可以视作λ是在λ0基础上的某种变化,这既可以表示成λ=λ0+βX这样的线性关系,也可以表示成λ=λ0^βX这样的非线性关系。两种表达式的区别只是λ和λ0的关系是线性还是非线性的。
式(6-6)之所以使用非线性关系,一个原因是λ的含义是概率,取值应该是在0~1之间。所以,如果直接用λ=λ0+βX这样的线性关系,则βX取值不应该超过1。βX在模型中的实质性作用就是通过增减来调节λ0,从而最后得到符合要求的λ。仅仅从数值本身来看,如果βX存在超过1的可能性,则需要通过某种数学处理使得它至少位于0~1之间,这样才能使用线性关系。之前提到的y=y=1/(1+e^(-x))就是类似的把βX的值转换到0~1之间的一个方法。
式(6-6)中需要拟合得到的参数只有两个,即λ0和β。X仍旧是各种顾客特征和企业营销行为。式(6-6)认为每期即第t期都有一个基础流失概率λ0,在此基础上,顾客特征和企业营销行为以β为参数影响该期的流失概率λ。
四、采用机器学习的方法预测顾客流失
迄今为止,我们所用的预测顾客流失的方法都依赖于某种特定的数学模型。这些模型根据营销理论,采用有限的变量,能够较好地预测顾客流失问题。在数据不够丰富的情境下,例如传统实体店,这些模型能够较好地实现预测目标。
电商平台的出现,尤其是综合性电商平台的出现,使得企业积累了多方面的顾客信息。除了购物行为本身之外,顾客的网购支付乃至水电气之类生活支付等都有可能通过这些平台进行。企业现在有了顾客更多维度的信息。在新的数据环境下,整理出的数据表可能有几百列。这意味着有可能在几百个维度上,企业都有顾客行为的记录。
1、机器学习简述
数据丰富时,类似表6-1的数据表可以多达几百列。想要预测顾客是否流失,既可以用式(6-5)即
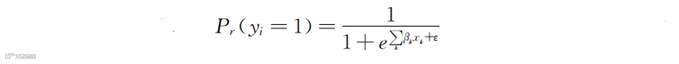
这样的模型(对应的xk有几百个),也可以直接用“y=a+b1x1+b2x2+b3x3+…+bnxn”这样的简单关系。y代表顾客是否流失,有监督机器学习中,我们知道一些顾客流失与否的状态。有了这些y值,就可以用类似于线性关系的简单公式,拟合出对应的a和b1,…,bn。所谓拟合,就是找到最合适的a和b1,…,bn。有的机器学习方法就是多次尝试a和b1,…,bn的不同取值,看看最终哪个组合最好。
你可以把“尝试”简单理解为试试取1,2,3,4,…。学者们开发了多种方法,确保既能找到最优值又能少尝试。例如某种方法可能不是逐个尝试1,2,3,4,…,而是按照某个间隔尝试2,4,6,8,…。实际的方法当然没有本书说的这么简单,但本质确实是既能找到最优值,又能使得尝试的效率最高。
机器学习是现在被提及较多的一类方法。这个领域已经发展了几十年,但最初的很多基本原理直到最近几年因为计算能力的提升才有了用武之地。一次次地不断尝试当然需要很多次的计算。
机器学习本身是一个不断变化的庞杂复合体,为了解决其中的每个问题,往往又延伸出了很多细微的算法。其内容往往需要一本书或者至少几章的篇幅才能讲清楚。与此相关的另外一个概念叫“深度学习”(deep learning),本书则完全不打算涉及。
机器学习的具体方法很多,最近几年随着热度提高,不断有新的改进方法出现。本书因为不是专门讲机器学习的书籍,所以只解释其中一种方法的基本思想。对于更多方法及其思想,读者可以参考相应的机器学习方面的书籍。
本书对计量模型的解释都比较清楚。在机器学习这部分,本书重点说清楚机器学习方法适用于解决什么问题,其核心思想是什么。本书不涉及具体的算法层面,一是因为很难用几段文字解释清楚;二是因为用于解决实际问题时,操作上都是调用特定的程序包计算,并不需要我们理解代码和算法的具体细节。
你如果读了本书以后发现自己对机器学习很感兴趣,可以借由本书提供的对机器学习的朴素的理解,再去深入了解与机器学习有关的内容。本章谈及机器学习的目的只是提供一种营销领域对机器学习方法的应用。
2、简化的决策树例子
本节之前用到的模式是给所有变量xi找到权重βi,然后通过线性模型(类似于y=∑βixi+ε)或者非线性模型(类似于y=α^∑βixi+ε或者y=1/(1+e^∑βkxk+ε))得到一个y值。如果给y设定一个或者一些阈值,可以以阈值为分界线划分出两个或多个类型。
决策树是针对每个变量的取值划分范围,相当于对每个变量上设定阈值,先根据某个变量对所有用户进行划分,然后逐次按照其他变量进行划分,直到得出满意的分类为止。
机器学习包含多种方法。不同的方法适用于解决不同的问题,同时也有针对同一问题的多种不同的解决方法。本章后续部分重点讨论机器学习中的决策树方法如何用于预测顾客流失。
正式讨论决策树之前,我们先用个简单的例子说说什么是决策树。
(1).店铺掌握的顾客信息和期望实现的预测目标
假设一个店铺掌握的顾客信息只有顾客的性别(静态信息)和上个月的购物次数(动态信息)。该店铺知道本月哪些顾客来购物了、哪些顾客没来。它希望利用这些信息建立起一个分类方法,即根据顾客的静态信息(性别)和动态信息(上月购物次数),能够把顾客划分成两类(即本月来购物的和本月没来购物的);然后利用这个分类方法,每个月都根据顾客静态信息和动态信息,预测顾客本月会属于哪一类(来购物或者不来购物)。有了分类以后,店铺就可以针对不来购物的顾客开展营销活动。
我们对上面这个例子进行抽象化。企业已知的信息是顾客静态信息和动态信息,企业也知道顾客的结果性行为(本月是否来购物),那么企业需要建立起一套分类方法,实现预测目标(其实是分类)。目标是根据顾客静态信息和动态信息,在下一期中将顾客进行分类(来购物或不来购物)。其中隐含的假设是顾客每一期(月)的行为模式保持一致,在上一期建立的分类方法可以用于下一期对顾客进行分类。
(2).数据的标准化
我们现在回到这个例子的细节中。你对之前提到的标准化或者归一化还有印象吧,或者说不论顾客数量有多少,我们总能找到类似于“一打”(12个)这样的单位,使得我们关注的数量转化为1或者100之类的便于理解的数量。如果你忘了,也没关系。我们就假设一个店铺有100个顾客,店铺有他们的静态信息(性别)、动态信息(上月购物次数)、结果性行为(本月是否来购物)。店铺想找到一套能够根据静态和动态信息对结果性行为进行划分的分类方法。
(3).使用单一维度对顾客进行分类
我们就以这100位顾客为例,假设数据统计的结果是本月有30位来购物了,另外70位没来。我们又另外统计了这100位顾客的性别分布,发现其中有30位男性、70位女性。
如果只依据性别来划分,可以把所有顾客分成两类,如图6-1所示。其中男性顾客合计30人,但这30人中既包含来购物的也包含未来购物的。仅凭性别我们无法把来购物和未来购物的顾客区分开来。图6-1右侧女性顾客也存在类似的情况,仅凭性别区分不开来购物与未来购物的顾客。
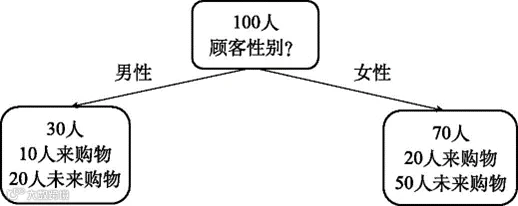
图6-1 按照静态信息(性别)对顾客进行分类
我们也可以单独依据购物频率来做新的分类尝试,情况如图6-2所示。也存在同样的情况,仅凭购物频率一个维度无法区分开来购物和未来购物的顾客。
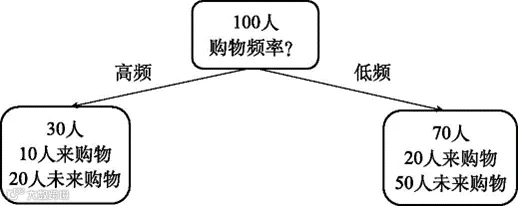
图6-2 按照动态信息(购物频率)对顾客进行分类
你已经看到,单独使用顾客性别或者购物频率都难以把来购物和未来购物的顾客区分开。
(4).综合使用多个维度对顾客进行分类
现在我们尝试综合使用静态信息和动态信息对顾客进行分类。分类结果如图6-3所示:
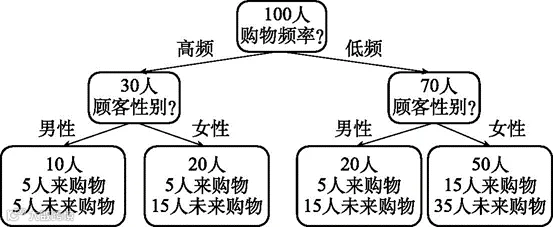
图6-3 先按购物频率再按性别对顾客进行分类
从图6-3可以看出,采用两个维度(即购物频率和顾客性别),仍旧难以明确区分来购物和未来购物的顾客。但似乎越到后面,每一群体的顾客数量越少。也许再找到一个维度,我们就能区分开了。按照这个思路,我们尝试找到一个新的维度,以便能够画出图6-4那样的图来。
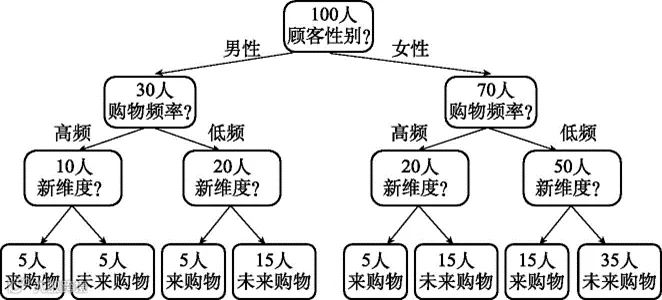
图6-4 引入更多维度来划分顾客类型
我们尝试增加采用数据中包含的其他维度来给顾客分类。例如,依据表6-1的内容,猜测顾客是否退休或者购物的时段不同也许有助于我们区分顾客类别,可根据年龄列或者活跃时段列来试一试。结果如图6-5所示。
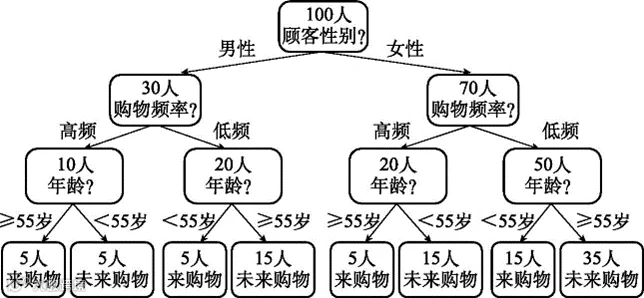
图6-5 使用三个维度来划分顾客类型
看起来我们总算是找到了一个分类方法,能够用几个维度(对应表 6-1 中的若干列),最终把顾客划分成“来购物”和“未来购物”两类。有了这个方法,我们就可以用这批顾客目前的数据来预测下个月谁不会来购物,然后施加营销影响。
(5).决策树的分类过程
从图6-1到图6-5能够看出,整个过程就像是询问每个顾客(对应表6-1中每行数据)的情况。前面已经提到,表6-1是根据顾客的原始行为统计出来的,它并不是记录原始行为数据的日志文件。原始的日志文件应该类似于表3-1。在整个分类过程中,我们针对每一行(即一个顾客)先询问了性别,然后询问了顾客的购物频率,接着又询问了顾客的年龄。到这里已经能够清楚判断来购物与否,足以判断顾客本月是否来购物了。这就类似于一个对顾客进行分类的决策过程,因此这种方法才叫“决策树”。如果顾客来购物了,意味着顾客在此期间仍旧活跃,我们就可以判断顾客没有流失。因此,我们就能够用决策树来预测顾客流失与否。
刚才的例子只用了三个维度(指标)就把顾客清楚分成了来购物与未来购物两类。如果运气没有这么好,需要更多的维度怎么办?或者,怎么样才能把上述方法进行泛化,让它能够用于各种情况?
为此,我们需要找到几方面的答案,即:
(1)需要几个维度?
(2)应该从数据中具体选择哪些维度?
(3)维度的先后顺序是否有影响?
(4)如果有影响,应该如何决定其先后顺序?
(5)如何才算分类成功了?
3、用决策树进行分类的基本思想
机器学习中,通常会将数据随机分割成“训练数据”(Training)和“测试数据”(Test)两个数据集。用训练数据来拟合参数,然后用测试数据来判断拟合能力的高低。
决策树的分类基本思想并不复杂,实际上就三步:第一步是找到一个最优维度(机器学习中通常叫作“特征”),将训练数据对应的样本(即表6-1中的若干行,不是列)分成若干子集。第二步是看看划分后的各子集是否满足分类目标。第三步是针对不满足分类目标的子集,继续重复前两步,直到满足要求为止。
上述过程中,评判特征是否最优主要看分类后的子集的纯净程度。你可以把“纯度”通俗地理解成目标变量要能明确区分(例如,y=0和y=1的样本混在一起就不够纯)。以图6-3和图6-4为例,两个图所用的数据样本容量都是100人,但图6-4中来购物和未来购物人数的比值都更为极端(即某一类型的人所占的比重更大),直觉上我们会认为采用购物频率作为划分依据更有效,即更“纯”。
依据每一个维度划分成几个子集取决于数据本身或者管理判断。例如,性别只有男、女两个维度,如果性别这一列的数据有缺失,则可能会有男、女、未知三个维度。购物频率可以划分成高、低两个维度或高、中、低三个维度。因为表6-1中的高频购物这一列是数值型连续变量,我们也可以在划分高、低时设定多种不同的分割方式。然后按照每种分割方式都计算一下,看看怎么样分割能够更好满足分类目标。
分类质量如何通常可以依据精确率、召回率、准确率来判断,分类之后这些指标满足什么水平算是实现了分类目标,则取决于管理判断。
我们在第五节和第六节分别讨论如何评判最优特征、如何确定子集数量以及如何评判分类的质量。
欢迎诸位企业家朋友随时与朗玛峰团队沟通交流