

第七章 产品推荐和先后购买
通过前六章我们已经了解了重复性购买行为,知道了如何预测顾客下次购物的时间,知道了如何从长期考虑,判断顾客能够向企业提供的终生价值,也知道了顾客之间会相互影响,导致顾客新增或者顾客流失,改变企业的总顾客数量。本章探讨一个新的问题,即企业通过营销手段吸引到新顾客,或者预测到老顾客可能要重复购买了,或者唤醒了休眠的顾客后,应该向顾客推荐什么产品。或者说,之前关注的是顾客什么时候来、购物金额是多少、长期来看会持续购物多少年,但没有关注顾客会买什么产品。本章就来考虑顾客会购买的产品以及购买产品可能存在的先后顺序。
在深入探讨产品推荐之前,我们先要泛化对顾客重复性购买行为的理解。有了对不同层面“重复性”的理解,后续进行产品推荐的时候就能够有更多灵活的选择,而不会局限于具体产品的重复购买和推荐。
一、从不同层面泛化理解重复性
顾客的购买行为可以分为重复性和非重复性两大类。随着视角的变化,同一个行为有可能被划分为不同的类别。
1、判断重复性的不同视角
如果画一条线段,把重复性和非重复性作为线段的两头,那么多数购买行为都可以作为一个点,标在线段上的某处,如图7-1所示:
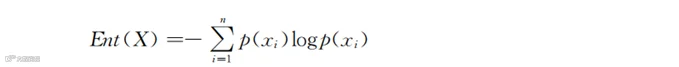
式中,Ent是Entropy 的缩写,也有用符号H表示的;n代表x这个变量(对应的是表6-1中的某一列)一共分成的类型数量(例如性别列有男性和女性两种类型,则n=2);p(xi)代表对应的类型i出现的概率(例如图6-1中男性出现的概率是30%),实际就是当前样本中第i类个体所占的比例。
我们可以用p(x高)代表购物频率高这一类型的顾客所占的比例。如果数据集中的样本容量是100(即假设表6-1一共有100行),而样本中购物频率为高的顾客有20个(20行),则p(x高)=0.2。
如果是二分类变量,例如数据中的顾客流失状态(1代表流失,2代表活跃,对应的是x1和x2),则该变量的熵值即为:

图7-1中文字代表顾客下次购物和上次购物相似的领域。例如,上次买了350ml的啤酒,这次买的还是350ml的啤酒,属于规格上一样的购物。如果上次买的是听装啤酒,这次买的是瓶装啤酒,容量也从350ml变成了640ml,虽然规格完全不一样,但可能仍属于同一个品牌。如果下次购物买的不是啤酒,而是酸奶(仍属于食品),则可以从品类角度把两次购物看作重复购买,区别只是品类划分的宽窄。甚至两次购物购买的完全是不同的品类,例如一次买啤酒,一次买电脑,虽然品类不同,但都是从同一个电商平台购买的,如果从电商平台来看,顾客仍旧产生了重复性购物行为。在更靠线段右侧的情况下,顾客分别从中石油和中石化加油站加油,两个加油站虽然分属不同的公司,但如果从行业看,顾客仍旧在行业内产生了重复购买行为。在更宽泛的定义下,顾客上半年买衣服、下半年去旅游,从动用购买力支付的角度看,也是一种重复购买。图7-1其实说的都是重复性购物,只不过越偏向左侧,越是狭义上的重复性购物;越偏向右侧,狭义的重复性越低。
2、不同视角看待重复性的例子
我们可以用个更具体的例子来讨论重复性。假设我们有类似美团(以下缩写为MT,泛指美团网和对应App等)这样的平台企业的数据。MT作为一个服务平台,涉及很多的领域。为了便于说明,我们用2021年3月MT手机App的页面截图来展示,如图7-2所示。

MT记录的顾客行为,包括点了什么菜品(对应图7-1中的“规格”)、从哪家店购买(对应图7-1中的“店面”),还可能包括顾客看了哪些电影、去哪里看病和修车(对应图7-1中的“购买力”)。简单地说,如何看待重复性行为,取决于数据所包含的内容。
图7-1把顾客后续的购买行为看作不同范围的重复性购买,区别在于关注的是购物产生的哪部分数据。例如,研究顾客的购物数据时,如果从所购买产品的规格角度来判断,可能发生了顾客流失;但是从品牌角度来判断,顾客仍旧活跃。同样的逻辑和道理,可以延伸到图7-1的最右侧。以图7-2所代表的业务为例,如果从产品所属的品类、店面甚至行业看,顾客都可以看作流失了,但从顾客登录MT并使用其服务来判断,顾客仍旧活跃。顾客在MT上的任何行为仍旧可以归为重复性行为。
总的来看,顾客的多数行为,取决于不同层面的数据提取和分割,可以归为不同层级的重复性行为。
3、判断重复性的不同视角
在重复性购买的基础上,向顾客推荐产品有“水平”和“垂直”两种思路。这是本书借用的说法,理论上并没有“水平推荐”和“垂直推荐”的说法。提出这种概念指向的是顾客购买产品时是否存在“天然”的先后顺序。这与市场营销文献中的“水平产品”和“垂直产品”不是一回事。文献中的“水平产品”指的是产品本身无优劣而只跟顾客偏好有关的产品,例如白色汽车还是黑色汽车。“垂直产品”则指产品本身有优劣差别,例如高品质汽车和低品质汽车。如果价格一样,所有正常人都会喜欢高品质产品。
按照“水平”思路推荐产品时,认为顾客购买的产品都是同一层级的,不存在先后顺序。影响顾客购买决策的主要是产品之间的相似性或者顾客之间的相似性。例如,我们在电商平台购物时经常会看到“猜你喜欢”之类的产品推荐。这类推荐的逻辑有两种:一种是根据你之前看过或者买过的产品,给你推荐相似产品;另一种是向你推荐与你类似的顾客买过的产品。不论是哪种情况,其在推荐时并不认为这次购买的产品与在此之前购买的产品之间有先后顺序,更多的是看产品或者顾客之间的相似程度。
按照“垂直”思路推荐产品时,认为顾客购买的产品存在先后顺序,顾客通常会先买某些产品,然后才会购买其他产品。例如,从银行的角度看,顾客会先开储蓄账户,再开信用卡账户。或者,顾客开户后,会先存活期,再存定期,后进行理财之类的金融活动。如果不了解这种产品隐含的先后顺序,即便按照之前的预测方法预测出顾客最近购物的概率很高,如果直接向他推荐排在后面的产品,也是很难实现重复性购买的。实践者可能会因此反过来质疑预测模型的效力,殊不知问题没出在预测顾客重复购买概率的模型上,而是推荐的产品不对路,或者更精确地说是推荐产品的先后顺序或者时间点不合适。
本章后续各节就从“水平推荐”和“垂直推荐”两个角度,说明向顾客推荐产品的思路。电商平台的推荐系统主要是采用“水平推荐”的思路。这主要是因为在电商平台上销售的绝大多数产品之间不存在购买的先后顺序。而在另外一些行业,顾客需求会随着顾客对企业的信任提升而发生变化,这些行业往往需要采用“垂直推荐”的思路。例如银行业、保险业的顾客首先购买的多是低风险产品,然后才会逐渐尝试购买高风险产品。企业在顾客浏览(或者逛店)概率最高的时间,向顾客推送合适的产品,更容易实现产品销售,形成从预测到销售的闭环。
二、水平推荐:推荐系统的基本逻辑
推荐系统在电商平台运用得最多,不过其思想并不是发源于此,当然应用领域也不局限于此。当多个产品不存在购买的先后顺序,或者,即便有先后顺序,也没有能力识别出顾客购买产品的先后顺序时,我们都会用到水平推荐的思想。电商平台上的绝大多数产品相互之间没有关联,顾客购买这些产品完全不存在前后顺序。当然,也会存在一些产品有购买的先后顺序,例如,顾客先买打印机,然后才会定期购买墨盒或者硒鼓。只是这种很明显的先后顺序依托现有的销售经验就已经能够识别出,用不着再用模型或者算法来解决。
1、水平推荐针对的三种顾客类型
我们先用个例子对推荐的核心思想进行简单介绍。假设你是服装店的销售员,来了一个顾客在挑衣服,你应该走过去向顾客建议试穿什么样的衣服呢?
我们可以把顾客分成有反馈和没有反馈两大类。反馈又可以分为显性和隐性两类。显性反馈代表顾客告诉了我们他是否喜欢。隐性反馈则代表顾客没有用语言,而是通过挑选或者购买产品等行动暗示了他的偏好。没有反馈的顾客则类似店里来了个新顾客,他什么都没说、什么都没特别去看,很难直接猜出他的偏好。我们往往只能根据可获取的信息进行判断,例如性别、年龄等人口统计信息或者来的时间。下面针对上述三种顾客类型分别讨论推荐的思路。
(1).给出显性反馈的顾客
向给出显性反馈的顾客推荐产品最容易。顾客如果是正面表达,说想要休闲风格的服装,我们直接向他推荐休闲装即可。如果顾客是负面表达,例如说他看到的服装风格过于休闲了,我们可以推荐稍微正式一点的服装。无论正反馈还是负反馈,都可以把顾客偏好量化,例如服装风格的休闲度是3(1代表完全正式,5代表完全休闲)。如果顾客反馈不喜欢颜色太暗的衣服,我们可以推荐色彩明亮一些的衣服。这时,我们又得到了顾客在另外一个维度(即色彩)上的偏好。依此类推,顾客反馈的维度越多,我们对顾客偏好的了解也越多。
(2).给出隐性反馈的顾客
有的情况下,顾客没有明确告诉我们他的偏好。他可能是个不爱说话的顾客,也可能没有弄清楚自己的偏好。如果顾客已经试过几件衣服,我们大概可以根据他试过的衣服判断他倾向于购买什么类型的衣服。例如,顾客试了若干套西装,向他推荐西装肯定比推荐夹克衫成交的概率更大。当然,他试了若干套还没买,肯定是在犹豫或者不完全满意,所以,推荐的应该是同属西装大类但又跟他试过的不完全一样的西装。我们还可以根据其他方面做更多的细化考虑,设计推荐系统考虑的是非人员化的场景,所以,先要考虑大类判断正确,再考虑细节,并且要考虑用算法实现的可能性。
(3).没有给出反馈的顾客
有的时候来的是个新顾客,他还什么都没说,也什么都没试过。我们也就无法根据他看过、试过的产品来判断其偏好。当然可以问一问他想要什么,或者等他试过几件以后再向他推荐。这样就转化成了前两种情况。
现实的挑战是,顾客进店不容易,如果不和顾客互动(常见的就是推荐点什么),很可能顾客在店里看几眼就走了,我们根本就没有等他试了几件后再推荐的机会。你去实体店买衣服,店员总是不厌其烦让你先试试,其实是需要了解一下你的偏好,同时也通过试衣服把你留在店里,以便能获得和你交流及后续向你推荐的机会。
电商平台或实体店的顾客来访是企业花钱做广告等吸引来的。电商平台上可选的店铺和产品又近乎无限,顾客切换到其他店铺或者产品页面是很容易的事情。如果不能很快留住顾客,顾客在手机上只要轻轻一滑就去别处了。
新顾客还没有留下行为痕迹,所以无法根据他浏览或者试过的产品来进行推荐。这个时候就需要换个思路来解决问题。我们在预测顾客的重复性行为时遇到过类似问题。情形是,如果有顾客的过去行为,我们就按照“用过去预测未来”的思路;如果是新顾客(这时没有顾客的过去行为),当时的思路是“用群体预测个体”,即用群体的购物时间间隔(实际上是个概率分布),按照概率最大化的原则,推算个体的购物时间间隔。向新顾客推荐产品时,我们也可以按照类似的思路。好消息是现在比预测购物时间间隔有了更多维度的信息,如顾客性别、年龄、进店时间和引流渠道等,我们可以据此找到与这些新顾客类似的现有顾客,根据现有顾客的偏好来猜测新顾客的偏好。
向上述三种类型的顾客推荐产品,实质都是弄清楚顾客偏好。区别只在于有的顾客直接说出了他的偏好;有的顾客只有行为,需要我们猜测其偏好;还有些顾客甚至连行为都没有,需要我们根据相似顾客来猜测其偏好。弄清楚了顾客偏好以后,我们向他推荐与他偏好最接近的产品就是了。
2、顾客反馈的量化
我们以上述三种顾客类型为例,看看如何量化顾客不同类型的反馈并形成可供分析的数据。
(1).显性反馈形成的数据
在显性反馈情境下,顾客表达了自己的偏好。我们可以把顾客对不同产品的偏好转换成五点量表。在线上场景中,顾客可能直接给出了评分。例如顾客会在豆瓣网站留下对不同电影或者书籍的评分。或者,顾客点了外卖,会在美团平台对餐馆、送餐员等给出评价。类似的场景还有很多,其核心就是我们有了顾客对不同产品或服务的评分。对应的数据整理出来则如表7-1所示:
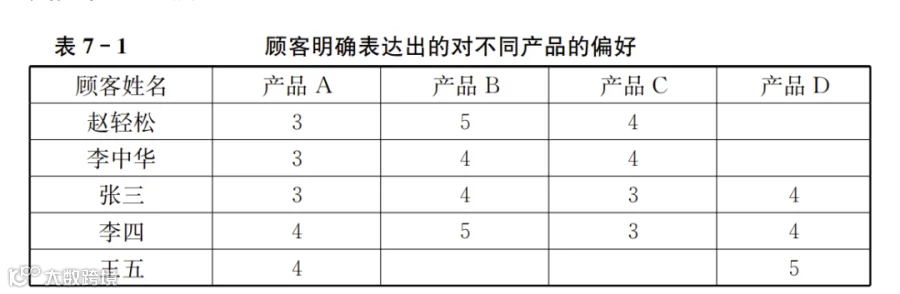
表7-1的空白处代表顾客没有反馈对该产品的偏好。这可能是顾客没有给出反馈,也可能是顾客没有购买过该产品。
(2).隐性反馈形成的数据
隐性反馈的情况稍微复杂一些,我们可以从产品整体和产品特征两个层面来分析。
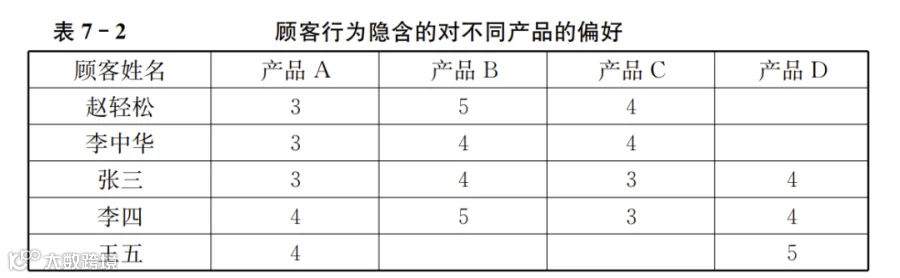
从产品整体看,虽然顾客的隐性反馈并未给出任何针对产品的整体评分,但是他的一系列行为会折射出其对产品的总体偏好。例如,顾客花了不少时间查看某产品,或者在电商平台上多次浏览某产品,都意味着顾客对它感兴趣。顾客如果购买了该产品,则对该产品的总体偏好肯定高于仅仅翻看产品。在电商情境下,顾客的页面点击、浏览、加收藏夹、加购物车、下单、付款存在一个先后顺序,并且在企业的数据系统中都有行为时间的记录。我们可以按照点击是1、浏览是2、加收藏夹是3、加购物车是4、购买是5来给不同的行为赋值。虽然不同的行为只是类别不同,应该使用定类尺度标记,但因为存在先后顺序,实际上可以标定成定序尺度。我们也可以用浏览时间或者浏览次数来量化顾客对某产品感兴趣的程度。在衡量对某首歌的喜爱情景下,显性反馈是顾客给出对某首歌的评价,而隐性反馈则可以用顾客播放某首歌的次数来代表。例如,QQ音乐等在线网站对用户的播放次数都有记录。不论哪种情况,我们都可以把顾客行为转换成数字。为了明确对应关系和便于阅读,我们也基于顾客的隐性反馈生成一个对应的数据表,数据的形式如表7-2所示。注意,表7-2与表7-1的区别主要是每列数据的数字含义有差别,而整个表格(对应的是数据系统存储的数据)的结构与表7-1其实是一样的。
从产品特征看,任何类别的产品都可以划分出若干特征。例如,服装包括品牌、材质、颜色、尺码等,家电包括尺寸、功率等。如果是电影或者其他演出,则可以划分出导演、主演、情节类型、表现手法等。这些特征本身并不受顾客偏好的影响。产品的同一个特征,在不同的顾客看来并没有差别。但是同一顾客却会对不同特征构成的产品产生不同的偏好。也就是说,特征本身不受顾客偏好的影响,却会影响顾客偏好。如果抽象具体的特征名称(例如品牌、材质等),而用特征1、特征 2……来表示,也可以形成不同产品的特征数据,其形式如表7-3所示:
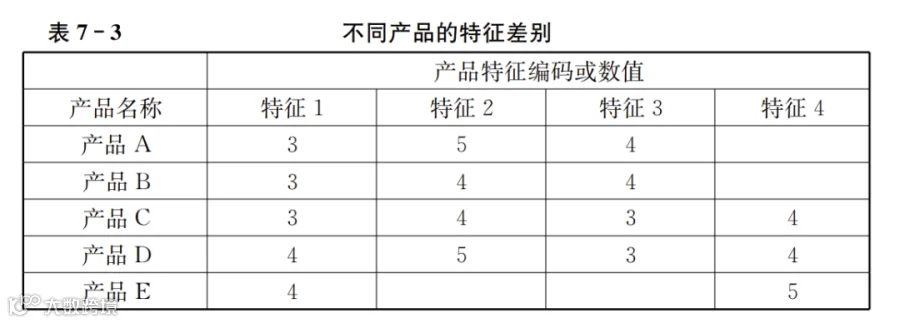
表7-3中的特征可以是定类的,例如不同数字代表不同的品牌;可以是定序的,例如同一颜色的不同亮度;可能是定比的,例如价格之类可以加减乘除的数字。
(3).顾客没有给出反馈时推荐产品需要依据的数据
当顾客没有给出任何反馈时,无法观察或者了解顾客偏好。这时则需要根据与他相似的顾客的偏好来猜测他的偏好。寻找相似顾客更多的是依赖顾客的人口统计信息和与具体产品无关的行为信息(例如进店或者登录时间等),而不是顾客在具体产品层面上的信息(因为还没有获得这类信息)。在这种情况下进行推荐,主要是依据数据系统中留存的顾客背景信息。这些信息的数据格式如表7-4所示:
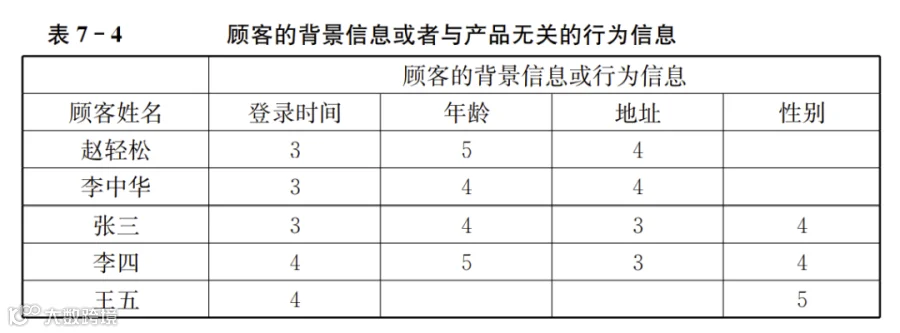
表7-4中的多列数据是分类数据。登录时间虽然能精确到秒,但做出推荐决策需要的只是时间段,例如划分为“早、中、晚”或者划分到每个小时中,其他的信息如地址、性别也都是分类数据,虽然表格中的内容仍旧是数字,却是之前提到过的定类尺度。通常,只有年龄、收入这样的数据采用的是定比尺度。实践中,往往因为数据精度不够,年龄也会是“老年、中年、青年”之类的定类尺度,收入也可能是“高、中、低”之类的定类尺度。
对比来看,表7-1和表7-2是不同顾客对不同产品的总体评价,区别只在于评价是顾客明确给出的还是我们依据顾客行为做出的。表7-3是不同产品在多个特征上的对比。不同于表7-1和表7-2代表多个顾客,表7-3可以是同一个顾客看过的多个不同的产品。表7-4实质上类似于表7-3,区别是产品换成了顾客,产品特征换成了顾客特征。本质上,这两个表是一样的,都是特征数据构成的表格。
如果把表7-1(或者表7-2)和表7-3(或者表7-4)结合起来,就可以构成一个包含X、Y、Z的三轴立体图。你可以把表7-1(或者表7-2)中的顾客和产品想象成X和Y轴,而把表7-3中的产品和特征想象成Y轴和Z轴。这样,就构成了一个三维结构。如果把上述四个表格结合起来,就构成一个四维图形。因为在现实世界中通常用到的都是三维立体图,如果是多于三维的数据,就很难用图形来形象说明了。这时候通常就要用到向量(用带有方向和数值的量来表示)了。本书尽量用形象的数学来表示内容,我们暂时就想象到三维或者四维。
推荐系统依赖的数据类型用表7-1到表7-4基本就能代表了,所不同的只是具体的数据类型和具体的值。
为了便于后续计算,把上述4个表格所表示的数据抽象化。抽象化后的数据如表7-5所示:
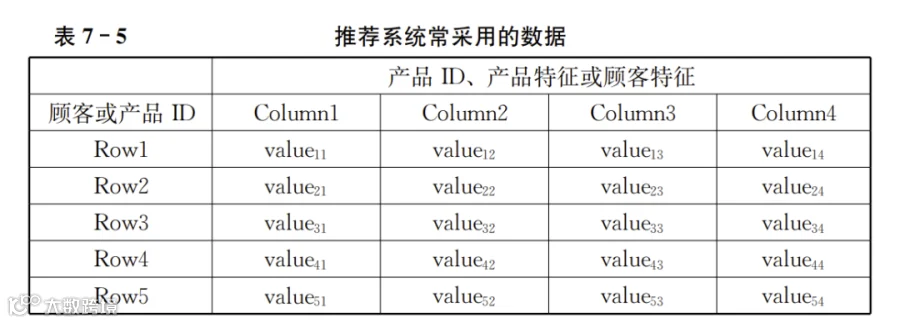
表7-5中最左侧一列,可以是顾客ID或者产品ID。其余列则代表多个产品、产品的多个特征或者顾客(用户)的多个特征(背景信息或者行为信息)。表中的具体数值value可以是分类的(例如1~n对应n个类别),也可以是代表顺序的,或者是代表差别的,甚至是可以加减乘除的定比的数据。
取决于决策目标,有时各列的重要性相同,有时某些列更加重要,因此计算时各列的权重未必相同。如果权重不同,则需要通过训练数据拟合出最佳权重,这些都是我们在之前章节已经了解到的。
3、计算相似性的基本思想
推荐的思路说起来并不复杂。下面用甲、乙来代表顾客,用A、B来代表产品。如果根据顾客甲的反馈(无论隐性还是显性)知道他喜欢产品A,那么向甲推荐与产品A类似的产品B即可。如果不知道甲的喜好(例如甲是新顾客,因此无反馈),但知道跟甲相似的乙的偏好,则只要按照乙的偏好向甲推荐产品即可。
上述过程中,我们需要完成两个任务,一是计算所有产品与产品A的相似性,二是计算所有顾客与顾客甲的相似性。因为表7-5的行代表产品或顾客,所以,我们要计算的就是表7-5的每一行和特定某行(对应产品A或顾客甲)之间的相似性。然后找出最相似的那一行。如果行对应的是产品,则最相似的那一行就是产品B。如果行对应的是顾客,则最相似的那一行就是顾客乙。最后再从另外的表格中找出乙偏好的产品并向甲推荐即可。
计算相似性实际上就是计算两行之间的距离,本质是两行在多个维度(即多列)上的差异大小。最相似的两行就是距离最小的两行。下面先从计算两个维度的距离说起,然后过渡到计算在多个维度上的距离。
(1).计算两行两列的相似性
先以两个维度为例,看看如何计算两个顾客或产品的相似性。我们用图7-3来表示表7-5中前两行和前两列的数据。其中的value缩写成V,而A、B则用于标注距离。
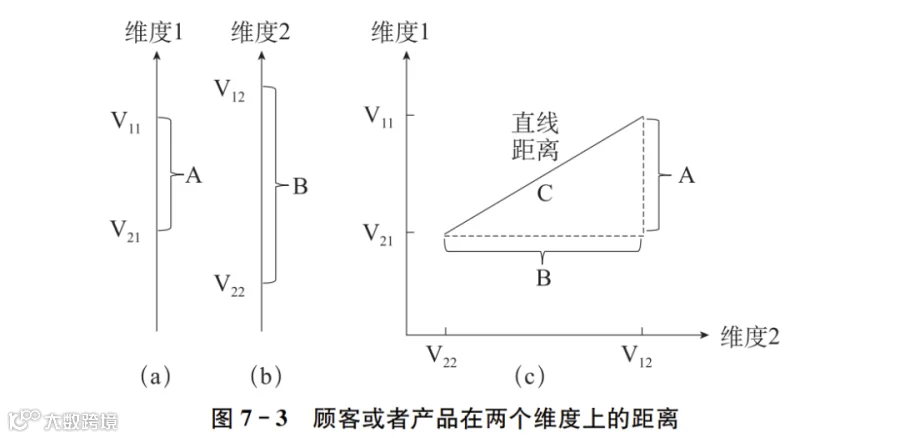
从图7-3的(a)和(b)可以看出,在单一维度上,如果想计算两个顾客(或者产品)的距离,只要将这两个顾客(或者产品)在这个维度上的V值相减即可。寻找相似顾客或产品时,并不需要在意相似是从哪个方向(大或小)相似,因为,代表相似性的距离无所谓正负。我们可以用绝对值(即A或B=|V1-V2|)或者用先求两者之差的平方再求平方根(即A或 B=√(v1-v2)^2)来解决。图7-3中的(a)和(b)两种情况都可以按照这个思路解决。
当需要同时考虑两个维度时,计算顾客(或产品)的距离有两种方法:一种方法是计算每个维度上的距离A和B,然后把两者的和(即“A+B”)当作距离。另一种方法是计算顾客(或者产品)之间的直线距离,即计算图7-3(c)图中的C。也就是计算三角形的斜边的长度。按照三角形勾股定理的计算公式,有C=√A^2+B^2。
(2).计算两行多列的相似性
表7-5的列对应现实中的维度(即产品特征或顾客特征)。当需要计算两个顾客(或者产品)在多个维度(即多列)上的相似性(即距离)时,可以按照与计算两行两列的相似性类似的思路。一种方法是计算每个维度上的距离,然后求和;另一种方法是借鉴但不完全按照求直线距离的思路,对每个维度上的距离差先求平方,再求平方根。前者的思路可以表示成式(7-1),后者的思路可以表示成式(7-2)。
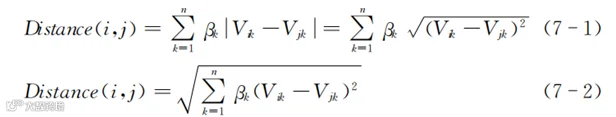
公式中的i和j分别代表要计算距离的两个顾客(或者产品),也就是表7-5中的某两行。k代表数据的维度,也就是表7-5中的某一列。公式中的n对应表7-5的列数。βk代表第k个维度的权重。我们可以根据经验给某个维度的权重赋值,或者通过已有训练数据拟合出βk之后再用于实际计算。多数情况下都直接用βk=1来赋值,相当于没有βk这个参数。
式(7-1)计算的是曼哈顿距离,式(7-2)计算的是欧几里得距离,还有个更为通用化的闵可夫斯基距离
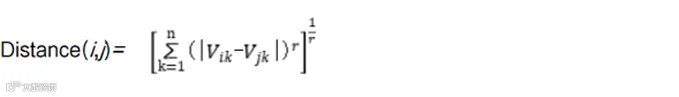
因为本书的重点在于帮助读者理解,所以尽量不使用增加阅读负荷的新概念,读者不必在意这些概念或算法的来源。
有了i和j两个顾客(或者产品)之间的相似性,只要计算所有顾客(或者产品)与目标顾客(或者产品)的相似性,然后找出最相似(即距离最小)的那个,就可以据此进行推荐了。
4、实践中的复杂情况
多数情况下,我们都可以用式(7-1)和式(7-2)计算顾客或者产品之间的相似性。现实世界总是会有各种各样的情况出现,当某行数据偏大或者偏小(即数据膨胀),或者某列数据偏大或偏小(即数据量纲不同),或者行列中存在很多空白(即数据稀疏)时,用式(7-1)和式(7-2)计算出的相似性就会有偏差,需要区分情况做出不同的调整。
(1).数据膨胀
当表7-5中的数据是用户评分时,常常会出现某行数据偏大或者偏小的情况,这种情况称为“数据膨胀”。数据膨胀是因为顾客评分的尺度不同。例如,顾客甲为人大度,他给的所有评分都是4~5分。顾客乙则要求较高,他给的评分常常是1~3分。如果直接用式(7-1)或式(7-2)计算结果,所得出的相似行并不具备足够的区分度。
虽然甲对所有产品评价都挺高,但对于大家都觉得不好的产品,甲给的评价也相对低点。同样地,虽然乙对所有产品评价都不高,但对于多数人觉得好的产品,乙给的评价也相对高些。为了消除某行数据偏高或者偏低对结果的影响,可以对该行数据统一做出调整。例如,如果行和列分别对应用户和产品,调整的思路就是根据大多数用户在不同列上的差别,修订某个用户在所有列上的评价,类似于该用户的数据都增加或减少某个数。例如,对同样4个产品的评价,甲是[5,5,4,3],而乙是[3,3,2,1],乙对所有产品的评价都比甲低2分。则实际上甲、乙两人对这4个产品的评价是类似的。
式(7-2)是计算表7-5任意两行在多个维度上的距离。我们计算距离的目的其实是考察相似性。除了计算距离,还有其他考察相似性的方法,也就是计算两行数据(两个顾客或者两个产品)的相关系数。常用的方法是计算皮尔逊相关系数。这里之所以把名称列出来,是因为还存在其他的相关系数。
皮尔逊相关系数的计算是用两行数据的协方差除以标准差,计算公式如下:
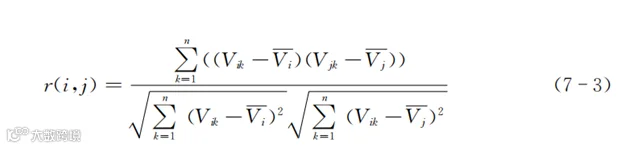
如果直接用式(7-3)计算相关系数,每次计算v的平均值时都要遍历数据进行计算,效率不高。实际应用的时候,常常采用变形以后的算法,形式如下所示:
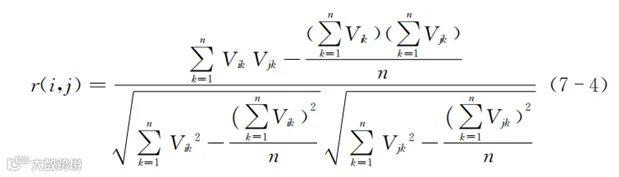
式(7-4)虽然看着复杂,但很多项都是提前一次性就能计算好的。如果把这些一次性计算好的内容都用“*”代替,则式(7-4)就变成了:
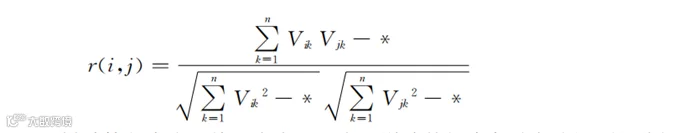
这样计算起来会很快。本书的重点是说清楚解决各种实践问题的分析或者计算思路,以便于读者理解对应方法的思想。在实际计算时,还需要考虑计算的速度。例如,电商平台的推荐系统必须在极短时间内给出推荐结果,所以算法对应的响应时间就成了要满足的限制条件。实践中的很多算法都会在基本思路的基础上做些提高计算效率的针对性调整。
皮尔逊相关系数用的都是平均值、方差之类的简单数学计算,本身的道理也不复杂,但它要求两行之间存在线性关系,这并不完全适合所有的情况。基于评价计算顾客的相似性倒是没有问题。
(2).数据量纲不同
表7-5是一个从实际数据中抽象出的示意表,可以代表多种情况。例如,每行代表一个顾客,每列代表一个产品,就构成了不同顾客的“产品偏好表”。偏好可能来自顾客直接评价,也可能来自对顾客行为的折算。如果每行仍旧代表一个顾客,但每列代表顾客某方面的背景信息或行为信息,就构成了不同顾客的“静态信息表”。当然,也可以是每行代表一个产品,每列代表产品的一个属性或特征,这就构成了不同产品的“特征对比表”。
“产品偏好表”通常来自顾客评价或者行为折算,数据的范围比较一致,例如,多数都是1~5或者1~10。如果是其他的表格,不同列的量纲可能不同,导致数据范围有很大区别,例如,顾客身高通常是1.5~2.0米,顾客月收入通常是1 000~30 000元,顾客行为次数可能从几十次到几百次,而产品特征则可能涉及重量、尺寸、色号等完全不同的量纲,数据范围变化更大。
如果直接用这些数据计算两行之间的距离,例如一列数字是12 345,另外一列数字是10,则只有数值大的列对结果有影响,数值小的列即便有变化,也不会对结果产生影响。在式(7-1)和式(7-2)中通过赋予不同的列不同的权重βk,修正了这种数值相差较大的影响。
除了使用权重βk进行调整外,也可以直接在数据预处理的过程中先对各列数据进行归一化或标准化处理。归一化是把所有数据都转变成0~1之间的数字。这样就消除了不同列的数据大小带来的影响。标准化则是把数据转换成平均值为0、方差为1的标准正态分布。其假设是绝大多数情况下,某个属性或特征的数值都服从正态分布。标准化后的数据没有区间限制,但服从正态分布。使用权重βk需要提前用数据拟合出具体值才行,而进行归一化或标准化则有成形的方法,无须提前进行数据拟合。归一化的计算公式是:
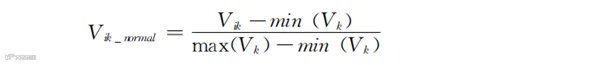
式中,Vik_normal代表归一化后的新数值;Vik代表第i行k列的值;max(Vk)代表第k列数值中的最大值;min(Vk)代表第k列数值中的最小值。
归一化的公式看着复杂,其实思想很简单。公式的分母是某列最大值和最小值之间的差,分子是每个值和最小值之间的差。相除的结果就是“每一数值和最小值的差”占“最大差距”的百分比。简单来说就是把所有的数值都压缩到一个百分比区间内。另外,标准化的计算公式是:
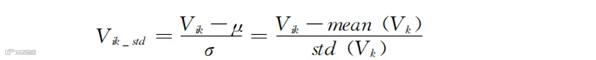
式中,Vik_std代表标准化后的新数值;μ和σ分别是第k列所有数据的平均值和标准差。我们在第三章中演示过这两个数值的具体计算。实际工作中,各种编程语言都包含现成的mean和std函数,直接调用即可。
标准化的公式看起来更复杂,竟然带有正态分布的意味。其实其思想和归一化并没有多大区别。分母是标准差,代表的是第k列每个数值与平均值的距离的平均值。简单来说,就是把归一化分母中的最小值换成了平均值,把最大值换成每个数值。分母求的不是最大值和最小值之间的距离,而是所有值偏离平均值的距离的平均值。分子计算的是每个数值距离平均值的距离。两者相除后,标准化表达的就是“某个值偏离平均值的程度”占“所有值偏离平均值程度的平均值”的比例。它既可能小于1也可能大于1。
(3).数据稀疏
虽然在表7-5中我们用Vik表示行列交叉的每一个位置,但在实践中,并不是每个Vik都一定有数值。表7-1和表7-2中,并不是每个顾客都对所有的产品有过评价或者行为。顾客看过或买过的产品也就几十个到几百个而已,相对于电商平台几十万个SKU而言太少了。如果每个产品都作为一列,那么代表某个顾客的那一行在多数列上都是空白的。同样,在表7-3中也并不是每一个产品都有某个特征。如果直接用这样的数据计算顾客或产品的相似性,很难得到有价值的结果。
遇到数据稀疏的情况时,往往需要计算两行的余弦相似性。你从概念上就能感受到,这是把两行数据当作两个向量(向量在多维空间上有方向和大小),计算两个向量之间的夹角。如果夹角小,这两行就相似一些,如果夹角大,就不相似甚至完全相反(如果夹角是180°)。解释余弦相似性需要讲述三角形计算角度的算法,还要把数据解释成坐标,很难简简单单地说清楚。好消息是,皮尔逊相关系数的计算公式经变形后和余弦相似性的计算公式是一样的。我们可以简单理解为计算皮尔逊相关系数时,把所有的空白都填成了0,然后用所有值减去平均值,道理与余弦计算类似。我们可以用皮尔逊相关系数来解决数据稀疏问题。
(4).异常值影响
除了上述三种常见的情况外,实际数据中还可能因为其他原因存在异常值。如果直接使用存在异常值的某行数据,则找出的相似顾客或产品肯定不对。在实践中,人们经常采用K近邻的方法,即求出最相似的k行(对应k个顾客或者产品),将这k个顾客或产品当作推荐的基础。这是为了避免单一相似顾客(或产品)隐含的误差,而找了k个相似的。相当于原来是找相似顾客,现在是找k个顾客组成的顾客群,然后根据顾客群的偏好来进行推荐。
K近邻本身并没有新的算法,只是推荐时是基于顾客群而不是单一相似顾客。
欢迎诸位企业家朋友随时与朗玛峰团队沟通交流