

本章开始要用到数学和概率方面的一些说法。不过读者不用担心自己的数学基础不够扎实。本章的重点是用数学和概率表达预测的思想,并不是概率知识本身。实践中具体计算时,用的是程序代码甚至现成的软件包。本章的目的是让读者理解每种计算方法的思想:一方面,在跟人沟通的时候能够听懂对方在说什么;另一方面,在需要做决策的时候能够做出合理的选择。
一、用个体的过去行为预测其未来购物时间
理解了预测的核心思想,剩下的就是具体怎么计算的问题了。每种预测方法都是针对某种情境提供的解决方案。实际应用时需要先弄清楚情境,这样才会知道选择哪种预测方法能够更好地解决这个情境下的问题。
1、情境:有顾客个体过去的购物日期记录
继续用钱广开店的例子。钱广记录了顾客(比如赵轻松)每次来店里的时间(年月日),想要预测顾客下一次什么时间会来店里。
如果把这个情境描述得复杂和贴近现实一些,就是这样的:根据店铺IT系统中的记录,ID为“zqs”的顾客4月8日来过店里购物,我们想预测他哪天还会再来购物。如果描述得更复杂一些,那就是我们想预测zqs某天(例如4月19日)来购物的概率有多大。
IT系统会记录zqs在4月8日购买了哪些东西,数据包括:
商品:醋
品牌:灯塔牌
规格:500g
价格:9.0元
促销:否
除此之外,IT系统通常还会保存其他方面的更丰富的信息,也会包括zqs在4月8日之前的购物记录。其他各种信息虽然都很有价值,但与我们的预测并不直接相关。因此,我们在进行预测的时候可以忽略那些无关信息,只使用“4月8日”这个日期信息以及之前的购物日期信息。
我们要预测的其实不仅是zqs在4月19日这一天来购物的概率,还应包括他18日、20日或者其他日期的购物概率,或者他在一个时间段内(例如4月8日到4月19日)购物的总概率。预测18日和20日两个日期,可以决定是否在特定某天(例如4月19日)开展促销活动;预测一段时间,则可以决定促销活动开始和结束的时间(例如4月8日到4月19日之间促销)。
简单来说就是,已知顾客之前一段时间在哪天买过东西,想预测顾客最后一次购物之后的某一天或者一段时间产生购物行为的概率。
2、IT系统中的实际数据
我们刚才谈到了企业留存的数据内容,现在来看看未经抽象的实际数据。如果你手边没有合适的数据,可以看看自己在超市购物的数据。例如,你可以打开自己的微信,找到“支付”➝“钱包”➝“账单”,选择“导出账单”。你收到的邮件就会包含一个加密的“微信支付账单.csv”附件。其中可能包含的内容如表3-1所示:
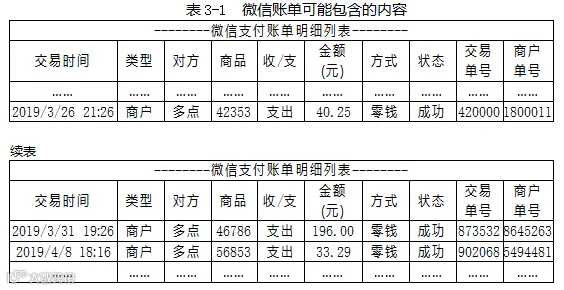
表3-1是某个ID的顾客(例如zqs)的付款记录,其中第一列是交易时间。表中一共显示了三条购物记录,简单计算,能看出分别间隔了5天和8天。
把这个顾客一段时间内的所有记录都统计一下,可以得到类似于图1-1或表2-2那样的图表。
从表2-2的第二列可以看出,该顾客最常见的购物时间间隔是10天(出现12次,占比30%),其次是间隔8天(出现10次,占比25%)和13天(出现9次,占比22.5%)。如果上一次购物发生在4月8日,那么他很可能会在之后的8~13天内再次购物(概率为30%+25%+22.5%=77.5%)。如果具体到某一天,则之后第10天再次购物的可能性最大(概率为30%)。
3、IT系统中的实际数据预测任务:顾客间隔不同天数来购物的概率
通过表2-2的例子,我们大致明白了预测的原理。那么,有没有什么方法能够比较准确和专业地完成上述计算过程呢?
此处的计算目标是顾客间隔不同天数的购物概率。本质是要找到一个函数,这个函数能表达出购物概率和间隔天数之间的关系,类似于:购物概率=f(间隔天数)。其中,“f”表示已知的自变量x(即间隔天数)和未知的因变量y(即购物概率)之间的关系,通常用某种函数(function,缩写即f)来表示。
4、预测时常用的基础概率分布:指数分布
有研究认为,顾客间隔不同天数产生购物行为的概率服从指数分布(exponential distribution),总体假设是,距离上次购物越久(即间隔天数越多),再次购物的概率越小。回想一下我们自己的购物经历,如果是重复购买的产品,从一个店铺刚买完东西不太可能第二天又买,而如果隔了很久不买,则我们可能不想买了或者到别的地方买了。也就是说,刚买完再次购买的概率会很小,间隔很久再买的概率也会很小。指数分布的假设至少听起来和描述的后半部分有些接近。为了便于理解,这里先用指数分布来说明道理。实际计算的时候,可以根据已有的数据选择合适的概率分布,或者直接通过计算拟合得到最合适的概率分布。
指数分布的概率密度函数(probability density function,PDF)如式(3-1)所示:
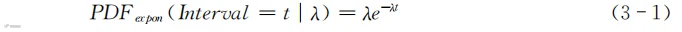
式中,t代表间隔的天数,相当于表2-2第一列中的某个数值。式(3-1)等号左侧相当于表2-2中的第三列,等号右侧表示计算出第三列的方法。式(3-1)与表2-2的不同之处在于,表2-2是我们根据已知数据(即顾客过去的购买记录)统计出来的,间隔天数只存在某些特定的值(例如间隔5天或者8天),而使用式(3-1)首先要用购买记录计算出式(3-1)中的参数,然后用参数去计算各种间隔天数(包括原来记录中没有的间隔天数)对应的购物概率。
指数分布的概率密度图如图3-1所示。请注意,概率密度并不等于概率,就像“速度”并不等于“距离”一样。因而概率密度值完全可能大于1。你可以把概率密度理解为速度,把概率理解为距离。既然“距离=速度×时间”,则相应地,你也可以理解为“概率=概率密度×间隔时间”。即概率实际上是图3-1中曲线和位于其下方的某两个时间点之间的间隔组成的图形的面积。
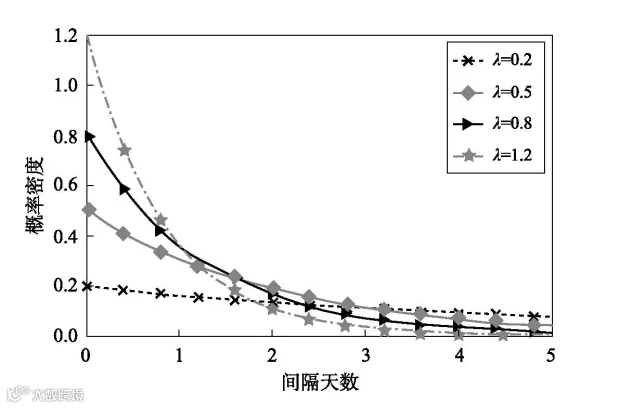
式(3-1)其实只有一个参数,即λ。e是已知值,大约是2.718 28。t则是自变量,是你预测时要针对的时间间隔(即间隔多少天)。
λ在购物情境中的含义是单位间隔天数发生的购物次数,通常用一个时间区间的购物次数除以区间总天数得到。例如,如果要预测赵轻松上一次购物后间隔不同天数的购物概率,则λ就是赵轻松以往单位间隔天数的购物次数。假设表3-1对应的微信账单就是赵轻松以往的购物记录,第一列“交易时间”一共包含有三条数据,分别是3月26日、31日和4月8日。我们进行简单计算就能看出,从3月26日到3月31日间隔5天,从3月31日到4月8日间隔8天,合计5+8=13天,也就是13天发生了3次购物行为。λ=3次/13天=0.23次/天。你可以简单地认为赵轻松平均每天购物0.23次。把刚才计算时的分子分母颠倒一下,即13天/3次=4.3天/次。这代表赵轻松每次购物需要经过4.3天,即平均每4.3天来购物一次。
前面的计算过程就是简单地把日期相减,并没考虑计算间隔天数的时候是否去掉开始和结尾那两天。实际工作中,我们很少会用三条记录作为依据,通常都会采用更多的购物次数。实际计算时,更多是用现成的程序代码来解决,这里主要是为了说明道理。日期相减在各种计算机语言(如Python)中都有对应的模块,没有我们这里按月计算这么麻烦,到时候写代码计算即可,读者不必担心。
表3-1虽然是实际数据,但本书只截取了其中三条用于举例,这样更便于口头计算。在实际进行预测的时候,如果一个消费者只有三次购买行为,往往会被归到数据不足那一类,当作新顾客来处理。预测这种顾客时,往往是用顾客群的行为来预测个体。
λ代表的是顾客平均每天来购物的次数。λ越大,代表顾客来得越频繁,图3-1中的曲线就越陡峭。这意味着频繁来店里的顾客如果间隔了好几天还不来店里,再来的概率就会大幅下降,这也与常识一致。从图 3-1 能够看出,不论λ的值是多少,时间间隔超过5天以后,概率密度就降到很低的水平了。
二、预测时各种可采用的概率分布
指数分布只需要一个参数λ。它虽然简单,但不能与常识(即现实世界)完全匹配。假定顾客购物行为服从指数分布没有太大的问题。但也有人认为顾客刚买完东西的那几天再次购物的概率很小,即间隔天数较小时,购物概率也很小;然后购物概率会上升到最大值;之后则随着时间延长,购物概率逐渐下降。我们可以思考一下顾客购物时间间隔的特点,顾客距离上次购物时间越长,再来购物的可能性越小。这样来看,购物间隔天数的概率分布的形状应该类似于倒U形,或者更通俗点说,像个山包的形状。
埃尔朗分布(Erlang distribution)适用于刚买完再次购物概率很小的情况。Erlang分布的形状是一种山的形状。本书虽然提到了Erlang分布,但因为其他的概率分布能够涵盖Erlang分布,所以,这里并不展开描述Erlang分布的任何细节。
统计学中有多种概率分布可以用于预测购物概率,本节做个概要介绍。
我们可以用最简单的方式,先只看概率密度函数的图示,就是类似于图2-1那样的坡形图。概率密度函数的图示形状多种多样,现实中最常见的是“山”形。差别只是有些像是尖尖的“山峰”,有些像是“山包”;有些“山”是对称的,有些“山”偏向一边。“山”的这些不同形状可以用不同的概率分布(对应不同的概率密度函数)来表示。
1、正态分布
呈“山”形的概率分布有很多种,最常见的是正态分布(normal distribution)。你看到“正态”二字就应该能意识到它要求某种形式的“正”,例如左右对称。正态分布如图3-2所示:
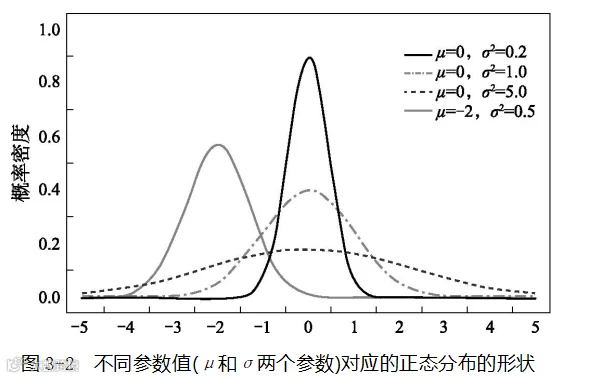
单纯从图形的形状可以看出,正态分布基本是左右对称的。正态分布的概率密度函数如下所示:
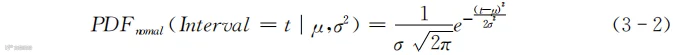
不要被式(3-2)的复杂形式吓住了,本质上它只有μ和σ两个参数。如果我们有购物间隔天数的其中一组数据(例如表1-2的数据),就可以很容易地计算出μ和σ两个参数。
看表1-2的第二列“两次购物间隔的天数”,可以得到一组代表间隔天数的数据11、12、8、23、7、9,这组数据一共包含6个数字。μ和σ2就是这组数据的平均值(mean)和方差(variance)。你当然也可以用其他的字母或者符号来表示平均值和方差,此处还是采用常用的符号μ和σ2。下面用表1-2的数据进行计算:
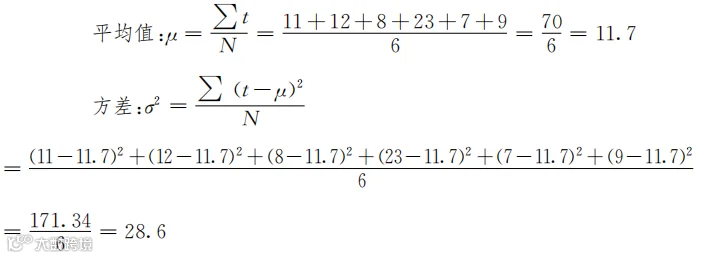
有了μ和σ的值,就可以很容易将t置于横轴,将用式(3-2)计算的概率密度置于纵轴画出图3-2来。μ影响“山”所处的左右位置(“山”本身仍是对称的),而σ影响“山”的陡峭程度(即尖尖的“山峰”还是“山包”)。σ越大,“山”的形状越扁平。
2、伽马分布
伽马分布(Gamma distribution)是另外一种呈“山”形概率分布,你可以把它当作备选方案。Gamma分布的概率密度函数图如图3-3所示:
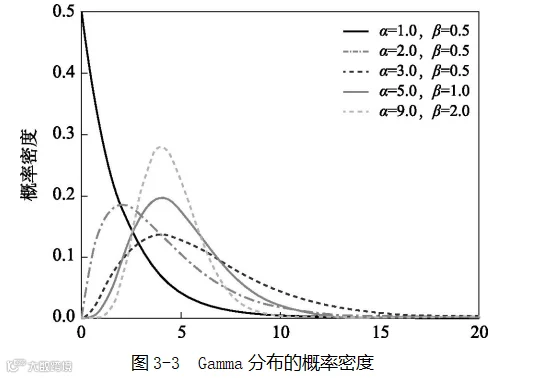
Gamma分布除了仍旧能够表示“山”的形状(“山峰”或者“山包”)和“山”所处的左右位置外,还可以表示“山”的不对称情况。在Gamma分布中,“山峰”或者“山包”的形状可以是偏左的,甚至可以只表示“山”的一侧。从这点来看,感觉Gamma分布应该涵盖了指数分布。实际上,Gamma分布确实涵盖了指数分布,指数分布可以看作Gamma分布在某个特定值时的情况,后面会细说。从“山”的形状来看,Gamma分布比正态分布提供了更大的自由度。
Gamma分布的概率密度的计算公式如下所示:
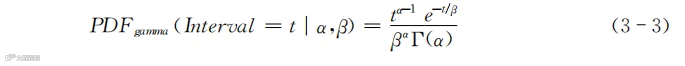
有的书用κ代表α,用θ代表β,只是所用符号不同,并没有实质的差别。
当α为正整数时,Γ(α)=(α-1)!,“!”表示阶乘。为了便于可能忘光了数学的管理者理解,下面举个例子:如果α是3,则Γ(α=3)=(α-1)!=(3-1)!=2!=2×1=2。
式(3-3)看着复杂,但从参数的数量来看,它和正态分布没差别,也只需要输入两个参数,只不过这次不是μ和σ,而变成了α和β而已。
不要被式(3-3)的复杂形式吓住了。除了阶乘,其他都是常规的乘法或者指数运算,可用科学计算器计算。另外,代入现实数据实际运算的时候,你是用计算机程序(你可以简化又形象地理解为用Excel表)计算。不管公式看起来多复杂,只要是最终可以计算出结果的公式,都不是问题。
从Gamma分布的推导过程知道,一组购物间隔天数t的期望值(你就当作平均值来理解)和方差,与α和β具有如下关系:

经过数学推导就能得到: α=μ2/σ2 β=σ2/μ
这就变成了前面已知的μ和σ2。我们还用表1-2中第二列“两次购物间隔的天数”数据,来说明如何计算α和β。在正态分布那一小节,已经计算出:

有了α和β的值,你只要代入式(3-3),就能画出对应的Gamma分布的曲线或者计算不同间隔天数t对应的概率密度了。
不论α和β的值具体是多少,它们所影响的是图3-3中曲线的形状。α决定山形曲线的形状是对称的还是偏向一侧,常常被称为形状参数(shape parameter);β决定曲线的陡峭程度(“山峰”还是“山包”),常常被称为尺度参数(scale parameter/rate parameter/inverse scale parameter),你可以把这个尺度理解为曲线散布有多广和多大的范围。
你从不同的书籍或不同的网站看到的Gamma分布可能会采用不同的符号,尤其是在采用β还是1/β来表示上,最终得到的Gamma分布的公式可能和式(3-3)有些不同。有时候用更为本源的κ和θ来推导Gamma分布时,Gamma分布的公式以及α和β的计算公式看起来都显得有些不同。在有的书中,当用α替换κ、β替换1/θ时,也可以把本书所描述的Gamma分布称为“倒Gamma分布”。如果用κ和θ来表示,图形会如图3-4所示。你会发现,在图3-3和图3-4中曲线的形状没有什么变化,差别只是当α和κ同样都是[1, 2, 3, 5, 9]时,图3-3中的β=[0.5,1.0,2.0]对应的是图3-4中的θ=[2.0,1.0,0.5],正好是θ=1/β。这里用中括号“[1, 2, …]”表示,采用的是Python中list的写法。
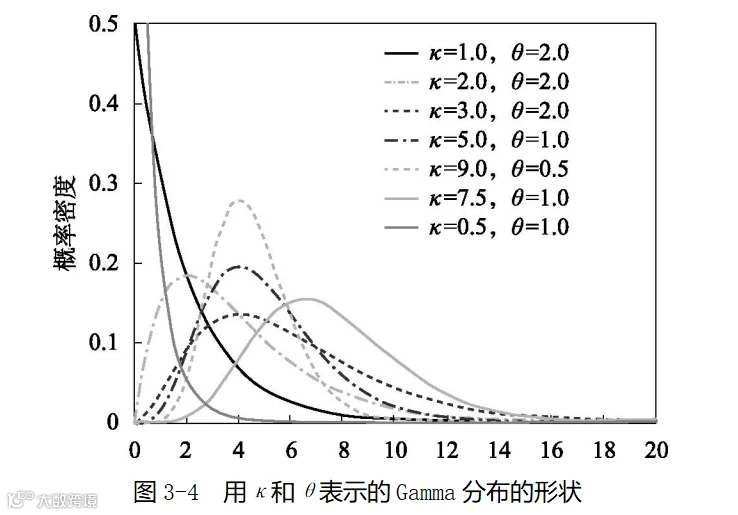
从上述转换可以看出,可以完全不必在意这些符号的变换和公式的具体表达。为了便于理解和应用,本书选择了最容易理解和看起来最简单的表达和计算方式。
3、伽马分布和指数分布的关系
当α=1而β用λ表示时,式(3-3)就变成了:
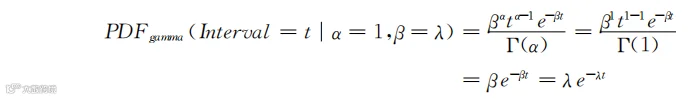
这等同于式(3-1),可以看出,指数分布是Gamma分布在α=1时的特例。实际上,Gamma分布可以看作多个指数分布的叠加。
回顾图3-1,它代表指数分布的概率密度。当时,我们根据每个消费者以往的购物历史数据,能算出一个对应的λ值,并能根据这个λ值在图3-1中画出一条对应于这个消费者的曲线。注意,这时该消费者的λ值是固定的。
如果是新顾客,因为没有以往的购物记录,所以无法算出其λ值。如果知道或者可以假设这个顾客和大多数顾客相似(例如山西某县的多数人吃醋的频率是差不多的),就可以用某个店铺已知的一群顾客的数据来代表那个新顾客。这一群顾客每个人的λ值可能都不一样,则会有一组λ值[λ1,λ2,λ3,…]。如果把λ值单纯当作一个数字,则仍旧可以对这组λ值进行统计,最后发现这组λ值会服从某种分布。
也就是说,假设那个新顾客的购物行为服从参数为λ的指数分布,而这个具体参数λ又服从某种概率分布(指数、正态或者其他某种分布),把这两种分布“叠加”在一起,最后就形成了Gamma分布。
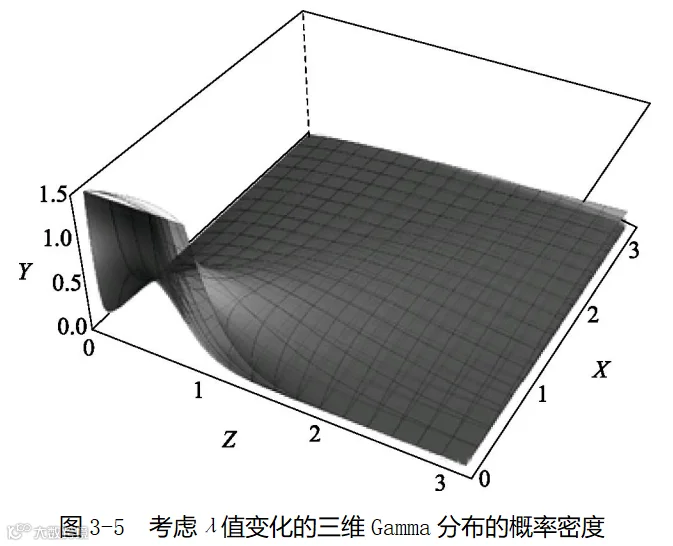
我们可以换一个角度,把Gamma分布看成一个类似于图3-5那样的三维图形,它有X、Y和Z三个坐标轴。横轴X仍旧与图3-1中横轴的含义一样,代表间隔天数;纵轴Y也仍旧代表概率密度。当你从图的右下角看向左上角时,看到的就是某个单一λ值对应的指数分布。但这次因为有了Z轴,这个λ值可以发生变化。你可以想象一下沿着右下方向左上方竖着放一叠常用的A4纸,每张纸上都画着一个λ值不同的指数分布。具体的Z值就是那张纸的编号,代表某个具体的顾客。这时还存在两种情况。一种情况是这一叠A4纸代表了整个顾客群,一张纸代表一个顾客。另一种情况是这个顾客很特殊,他易变,这一叠A4纸代表了他的每种变化。
4、贝塔分布
到目前为止,我们已经有了多种办法表示一个山形,它可以仅仅是山的一侧,例如指数分布或者某种Gamma分布;或者是一座完整的山(不论它是山峰还是山包,对称还是不对称),例如正态分布或者某种Gamma分布。
现在换一个新的情境:某个顾客一段时间频繁地来购物,之后间隔很久不来购物,过一段时间又频繁购物。如果把这个现象还原为一个实际场景,这可能是一个常驻外地的人的购物行为。他每次回家小住几日,这几日会天天去超市买东西;然后他出差去外地,一去就是十天半个月。从超市的记录上看,这十天半个月他就像消失了一样。然后他回到本地又会频繁购物几日,之后又出差去外地。如此周而复始。
这样的顾客,购物间隔天数很小(如1天)和很大(如12天)出现的频率都很高,但间隔7天左右出现的频率则很低。如果将间隔天数置于横轴,将间隔天数出现的次数置于纵轴,从图形(实质上是概率密度图)上看,就会出现两头高中间低的形状。
当顾客购物间隔天数的概率密度函数的图形包含两个山形时,该如何表示呢?这时,双峰的贝塔分布(Beta distribution)就是一个备选方案。Beta分布的概率密度如图3-6所示:
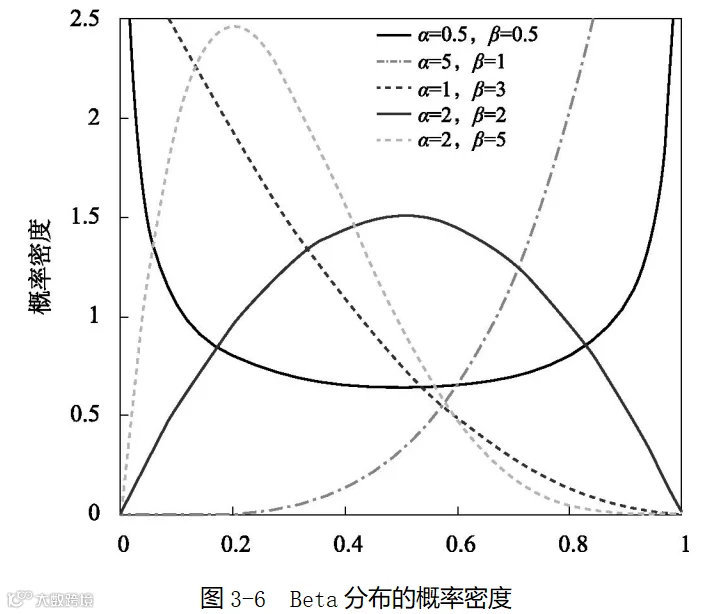
Beta分布可以提供类似U形或者M形的双峰形状,这是之前介绍过的只能提供单峰形状的指数分布、正态分布、Gamma分布所不具备的特点。
Beta分布的概率密度计算公式如下所示:
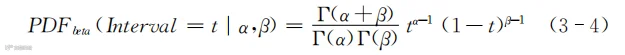
式(3-4)看着复杂,但从参数的数量上来看,它和Gamma分布并没有差别,也只需要输入两个参数的值而已,还是用符号α和β来表示,只是它们跟前面Gamma分布用到的α和β的含义没有关系。
从Beta分布的推导过程知道,一组购物间隔天数t的期望值(你仍旧当作平均值来理解)和方差与α和β具有如下关系:
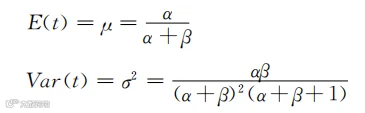
α和β的值可以通过之前在正态分布中计算得到的μ和σ2(即平均值和方差)的值推导得到。结果是:
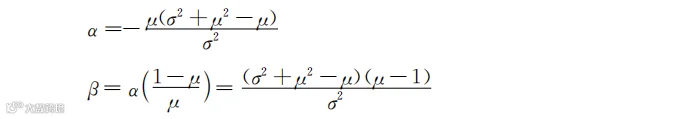
你还是不用管α和β的表达式有多复杂,反正只是基于μ和σ2的加减乘除而已。之前你已经算出了μ和σ2的具体值。
还是用表1-2中第二列“两次购物间隔的天数”这一数据说明如何计算α和β。在正态分布那一小节,我们已经计算出μ=11.7,σ2=28.6,则:
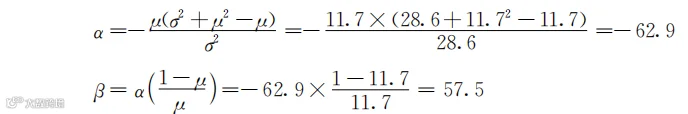
有了α和β的值,只要代入式(3-4),就能画出对应的Beta分布的曲线或者计算不同间隔天数t对应的概率密度了。
5、各种分布的小结
针对常见顾客行为的特点,本节介绍了几种进行预测时可能用到的概率分布。统计学中的概率分布有很多种,根据不同顾客的行为特点,可以选择不同的分布。
实际计算时,具体是采用哪种分布,要根据顾客过去的购物行为来决定。从道理上讲,哪种分布更贴合顾客的购物行为(类似于根据表3-1统计出的表2-2),就可以用历史数据计算得到对应分布的参数,进而使用该分布预测顾客的未来行为。这样的分布最贴合顾客的实际行为,所做出的预测应该也最准确。当然,购物行为具体贴合哪种分布,既可以基于现有理论进行推测,也可以通过计算机程序尝试各种概率分布,看看哪种分布拟合得最好。
如果不同顾客的购物频次相差较大,那么不仅最贴合每个顾客购物行为的概率分布具体参数的值可能不一样,甚至采用的概率分布也会不同。例如,最贴合赵轻松行为的是指数分布,而最贴合李中华行为的是正态分布。甚至,赵轻松上半年的行为更像指数分布,而下半年的行为变得更像正态分布。或者,即便同为指数分布,赵轻松上半年和下半年的λ值也可能不同。大数据时代数据的获取性和计算能力已经不是主要问题,“千人千面”推荐算法的兴起也使得针对每个用户采用不同分布进行预测成为可能,但总会有需要采用同样的分布对一批用户进行预测的情境。尤其是要求高时效、快响应的情境,或者需要用顾客群来预测单一顾客行为的情境,这时都要求我们用一个概率分布和一套参数来实现预测。
使用单一概率分布来代表有多种可能性的购物行为(例如要同时适用于赵轻松和李中华两种不同的行为),要求概率分布的形状有更大的可变化性。例如,要求代表概率密度函数的图形中山的形状可以陡峭,也可以平缓,可以对称,也可以偏向一边。当然,为了保证这种形状的可变化或者丰富性,概率密度函数所需的参数也就需要相应地增加。这类似于汽车在地面上行驶,操控改变的是前后左右;而飞机在天上飞,为了还能操控飞机向上向下,自然要增加更多的仪表或部件。
具有更大自由度的分布是狄利克雷分布(Dirichlet distribution)。这里的自由度指的是概率分布可以变化的领域数量。狄利克雷分布能够通过改变多个参数值生成多种其他分布,有时被称为“分布的分布”。你可以把它形象地理解为带有时空穿梭功能的飞机(即比普通飞机又多了时间轴)。如果固定时间参数的值,就是某个时代的飞机;如果进一步固定上下参数的值,飞机就类似于在地面上行驶的汽车;如果再进一步固定左右参数的值,就变得类似于只能前后开的高速列车了。参数越多,可以变化的领域就越多;相应地,模型也会越复杂,需要计算的参数会越多。
多数情况下,需要预测的顾客行为没有那么复杂,或者决策不需要实现那么高的精度,预测模型不需要像飞机那样适应各种情况,通常只要像汽车那样控制前后左右就能满足要求了。通常,我们需要在灵活性(伴随着适应性、复杂性)和简洁性(伴随着易用性、低精度)之间实现均衡。
(未完待续)
欢迎诸位企业家朋友随时与朗玛峰团队沟通交流