

一、重复性行为背后的规律
1、顾客行为本身的重复性是预测的前提
所有对重复性行为的预测都建立在一个假设前提上,即顾客行为本身是具有重复性的。这种重复性的背后,是事物本身所蕴含的某种规律。我们可以从阈值和消耗的角度来思考,即事物要回到某个平衡点,随着日常的消耗,水平低于某个阈值时,就需要启动补充行为。我们能够从外界观察到的是此补充行为,但决定补充行为的是事物本身的特点。
2、必需品存在重复性需求的原因:阈值和消耗量
我们先以必需品的购买行为为例。多数家庭至少会有1卷左右的卫生纸库存,不会等到完全用完了才购买。这时,阈值就是1。消费者每次可能购买一大袋即12卷卫生纸,如果每月消耗4卷,则买了一大袋卫生纸后(此时家中库存是13卷),过了大约3个月,库存又接近1卷。能够观察到的重复性行为是消费者大约间隔3个月会买一大袋卫生纸,而背后的规律其实是每月消耗4卷,只是这个规律仅仅依赖购物数据无法获知。
这里再说一个道理一样但描述起来更为复杂的例子。读者可以想想自己开车加油的情境。一般没人会开到一滴油不剩才去加油,通常是觉得差不多了就去加油。有人的“差不多”是加油灯亮了,有人的“差不多”是剩下一格油时。下次什么时候加油,取决于油量消耗的快慢,背后则是车辆开了多远的距离。站在加油站的角度,车主的开车行为数据不太容易获得,通常能够知道的是车主间隔多长时间来加油,每次加多少钱和多少升的油。
3、非必需品存在重复性需求的原因:心理阈值和消耗量
必需品的重复购买容易理解。为什么有些非必需品也会呈现出重复性消费呢?例如,有人隔一段时间就会去吃麻辣烫,有人隔一段时间就会去逛街。这些难道也有阈值和消耗吗?
这类行为解释起来比较复杂,需要根据不同的情况采用不同领域的理论。例如,定期吃麻辣烫的原因可以从生理和心理两个角度分析。从生理角度分析,可以把吃麻辣烫当作吃饭来理解,只不过多数人吃饭的频率是一日三餐,而吃麻辣烫的频率可能是一月三次。区别只是通常一餐的消耗速度大约是半天,而一顿麻辣烫的消耗速度大约是10天而已。从心理角度分析,有些人吃完麻辣烫或者逛完街,内心的愉悦感会达到一个较高的水平,但之后每天的工作、学习伴随很多的“不爽”,会不断消耗之前积累的愉悦感。在愉悦感消耗到一定程度时,消费者就需要“放纵”一下来补充消耗掉的愉悦感。工作、学习压力大的消费者,“不爽”较多,愉悦感消耗得快,需要“放纵”一下进行补充的频率就高一些。我们仍旧受限于数据的可获得性,无法获知消费者的“不爽”程度,能够观察到的只是他们多长时间来吃一次麻辣烫或者逛一次街。这背后的规律仍旧是“不爽”消耗愉悦感的速度。
如果不存在上述提及的阈值和消耗过程,则重复性行为的基础也就不存在了。本书所说的预测重复性行为的分析方法自然也不可能管用。
4、非重复性行为所蕴含的重复性
理解消费者行为的时候,存在不同层次的视角。比如,多数人买一张电脑桌后,短期内不会重复购买,不会有重复性购买行为。预测某一消费者下一次再买电脑桌是什么时间,会比较困难,意义也不大,但预测他什么时候会再来店里逛逛则是可行的。我们可以想想类似曲美这样的家具店应该如何预测顾客的重复逛店行为。消费者绝大多数的逛店行为本身就蕴含着前面提到的阈值和消耗的逻辑,具有一定的重复性。
如果把买了电脑桌的消费者的数据放到一起来看,可能会发现其中不少人过了一段时间会买尺寸更大的显示器或者打印机,又过了一段时间,他们会买打印机耗材等。从一个比较小的时间跨度看,仅仅看顾客购买电脑桌的行为,会发现不存在重复性。但从逛店或者购物这个更广的视角看,消费者的行为仍旧具有某种重复性,他间隔一段时间又会购物(例如买打印机、打印机耗材等)。虽然“购买电脑桌”这个行为没有重复性,但购买办公设备(电脑桌、打印机、打印机耗材)是具有重复性的。
当然,间隔的这个“一段时间”,可能不同的人在购买不同的产品上会相差很大。例如,可能会有30%的人间隔1个月,20%的人间隔2个月,还有10%的人间隔3个月,剩下40%的人间隔4个月到10个月不等。这实际上可以用某种概率分布来表示。后面的章节会详细说明这方面的预测。
二、用个体的过去行为预测其未来行为
1、预测顾客下次行为所需的数据
多数传统企业拥有的数据,就是某个顾客什么时间来过店里,买了什么,花了多少钱。如果企业仅仅知道每天卖了多少货、收了多少钱,或者稍微好一点,知道或者能够感受到今天来店里的顾客数量是多是少,但无法了解单一顾客的情况,则这个企业就过于“传统”了。这类“传统”企业已经脱离了本书讨论的范围。这种企业首先需要提高信息化或者数据化程度。
本书提到的了解单一顾客的情况,并不是要知道顾客的各种背景信息。预测所需的只是能够识别出是这个顾客而不是那个顾客。例如,某个顾客之前来过店里,因为某种行为留下了记录,IT系统对该顾客有个随机编号,例如“1234”。预测所需的只是下次再有顾客来的时候,我们知道进店的这个顾客是不是“1234”。或者他是可识别的另外一个编号为“2345”的顾客也行。我们并不需要知道这个顾客是男是女、年龄多大、收入如何、住在哪里等。虽然了解的顾客信息越多,可以据此做出的预测越多,但至少本节并不需要这么多的信息。
与本节有关的最简洁、最典型的信息只有两个,即进店时间和顾客ID。其中顾客ID只是用于区分不同用户,所以核心信息只是进店时间。预测所需数据如表2-1所示:
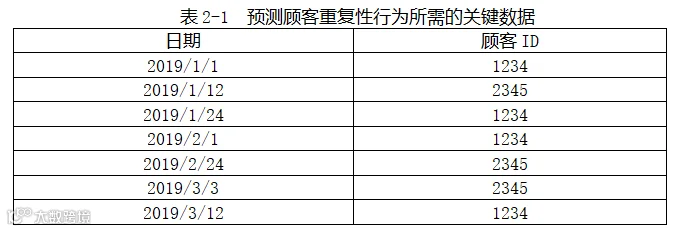
2、预测个体顾客下一次到店会间隔多久
我们还是用第一章中商户钱广和顾客赵轻松(顾客ID:zqs)买醋的例子。已知zqs之前买醋的行为,我们需要预测他未来什么时候会再买醋。这里的本质是知道顾客过去的行为,这个行为可能是购买,也可能是逛店,而在电商的情境下,可能是登录网站,或者是点击网页。具体采用什么行为的数据,取决于要预测什么,是下次购买还是下次来店里,或是下次登录等。
假设统计出过去的一年里,ID为zqs的顾客两次购物间隔的天数为:间隔5天的有4次,8天的有10次,10天的有12次,13天的有9次,15天的有5次。总的次数是:4+10+12+9+5=40次。如果直接用出现的次数,画出频次分布图,则得到第一章中的图1-1所示的图形。
如果知道了顾客zqs最后一次来购物是哪一天(例如,4月1日),想知道他下次来是哪一天,本质就是要预测间隔的天数。如果预测出间隔10天才来,则该顾客就是4月11日会来购物。我们应该据此备货。当顾客4月14日甚至4月16日(间隔天数已经超过了以往的最大间隔天数15天)还没有来的时候,顾客流失(不再来)的风险就很高了。此时商家通常应该通过营销活动进行干预,以便吸引顾客来店里,挽回要流失的顾客。而对于没有流失风险的顾客,则无须加以干预。通过这种精细化的区分,促销费用的使用会更有效。
在阅读本书的过程中,读者可能会觉得某些内容似曾相识。这是因为写作的过程中,笔者会在突出主题的情况下,尽量保证每个例子和每一部分内容的完整性,让读者能够看到事物的全貌。这样做主要有两方面的考虑:第一,很多读者并不会认真阅读本书的每一部分,常常是随手一翻,任选一个例子来看。读者未必读到了其他章节的内容,即便读到了,也未必能够跟当前看到的例子联系起来。第二,笔者给学生上市场营销课的时候,总是先用一个综合案例,把市场营销的各部分都包含进去;然后会换用新的案例,讨论市场营销的各个部分。但每次用的仍旧是完整的案例,只是关注的是营销的某一部分职能而已。本书的写作也是采用类似的逻辑。即第一章用一个相对完整的案例介绍了CRM的整个应用领域,然后每章所用案例仍旧是从全局的角度来看局部,想要说清楚每种分析指向什么样的实践应用。
3、间隔天数不是单一的确定值
从图1-1能够看出,顾客购物间隔的天数并不固定,那么如何判断下一次购物间隔多少天呢?
我们可以把刚才例子中预测的间隔天数10天,简单地理解为一个平均值。若要更进一步的话,我们则可以将其理解为一个类似于平均值的期望值。平均值的标准说法是算术平均值,就是把所有的数字都加在一起,除以数字总个数,最后得到的那个数值。期望值的道理与此类似,只不过是从概率的角度考虑,把不同概率(即可能性)下的情况都考虑到了,是对得到的按照概率发生的行为的简要描述。
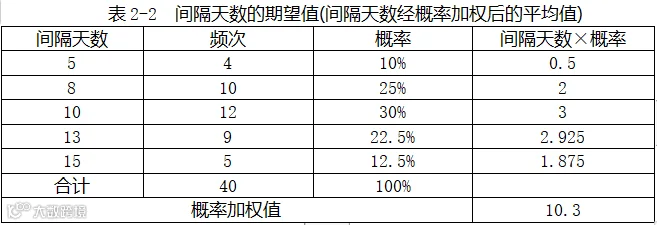
我们可以计算这个例子中的期望值。顾客全年有40次购物,即5×(4/40)+8×(10/40)+10×(12/40)+13×(9/40)+15×(5/40)=10.3天。
用Excel表计算,如表2-2所示:
4、理解现实是最重要的,不要被数学和统计困住
本书的写作方式是从最简单、最容易理解的事情说起,逐渐增加复杂性。采用的各种数学、统计、计算机概念也会逐渐复杂,以便读者(主要是企业各层级管理者)在阅读的过程中能够一直坚持到自己所掌握的数学知识能够理解的极限。本书引用数学和统计的各种概念或者公式的时候,重点不是保证表述严谨和正确,而是尽量容易理解。对于能做出CRM决策的人来说,他们晋升至有决策权的职位时,上学期间学过的各种数学和统计知识已经忘得差不多了。内容再严谨、再正确,如果他们不能理解,实际上是在做无用功。本书数学、概率有关计算的严谨性依赖于所引述的各种研究成果,而不取决于笔者的表述过程。
简单点说,即本书在表述上重在易理解,可能不够严谨。不过读者不必为此担心,本书涉及实际计算和实践应用时,现有研究在该领域认知的极限范围内,充满了严谨性。
5、可以针对每个顾客预测其相应的间隔天数
回到之前的例子。钱广可以利用他所积累的数据,计算出赵轻松(zqs)间隔10.3天应该会来购物一次,从而据此做出对应的营销决策。如果上述例子中的间隔天数代表的是赵轻松买醋的间隔天数,则计算出的10.3天是赵轻松下次会来买醋的间隔天数。只要钱广记录了上次赵轻松是什么时间来买醋的(比如4月1日),那么加上10.3天,大致就能预计赵轻松4月11日或4月12日应该会再来买醋。
上述信息在电商情境中很容易分析。电商平台存储的数据完全可以按照用户提取,这样,就能计算该用户过去一段时间不同时间间隔的登录(或逛店)频次。如果提取的是该用户购买某种产品的时间,通过统计用户购买该产品的不同间隔天数出现的频次,同样能够计算出类似上面例子中10.3天的期望值来。当然,这个10.3天其实代表的是图1-1那样的一个频次分布。企业决策者可以根据类似的频次分布,调整对应的营销决策以便让营销活动(如促销)更有针对性。本书的重点是预测,至于有了预测结果以后如何根据预测结果进行决策,相关的书籍已经很多,本书不再赘述。
6、有多种概率分布可以描述顾客不同类型的行为特征
本节的例子是用平均值或者期望值简单表示购物的时间间隔。实践中在计算的时候,为了更为准确,通常会采用某种概率分布。例如,像图1-1那样的凸形曲线,像座山的形状,中间高、两边差不多一样低,可以用正态分布表示。如果是其他形状,则可以用其他的概率分布表示。例如,如果山峰偏左一点,可以用某些参数的Gamma分布表示;如果山峰在两侧,则可以用某些参数的Beta分布表示。在此可以先把Gamma、Beta理解为某种形状的代号,具体的表达公式下一章会详细介绍。
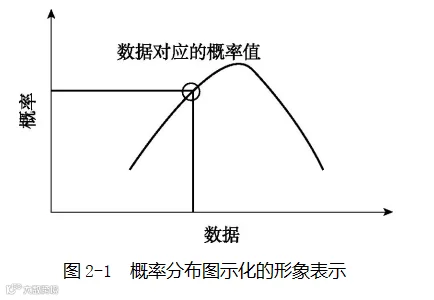
这里简要回顾一下概率相关知识。概率分布如果用图示化的方式形象表示,可以用横轴表示数据(例如间隔天数)的值,用纵轴表示横轴上对应数据值发生的概率(目前先这么理解,但很多时候纵轴其实代表的是概率密度不是概率本身),如图2-1所示。
从本节的分析过程看,我们已经能够根据顾客以往的购买记录预测他什么时候会来,会买什么产品。问题似乎已经完美地得到了解决,但真的这么顺利和简单吗?
三、用顾客群的行为预测顾客个体行为
1、挑战:顾客个体的过去行为数据不足
“用过去代表未来”这个完美方案有一个前提,就是作为预测对象的顾客要有足够的逛店次数或者购买次数。表2-1中第二列的合计数40次如果是某个顾客过去一年的逛店次数(平均365/40≈9.1,即大约每9天来店里一次),那么基于这个数据,对他未来的行为进行预测还是有可能的。可惜的是,每个店铺、每种产品绝大多数的顾客都没有这么高的逛店或者购买频率。虽然顾客过去10年的数据有可能累积到这么多次数,但时间太久,顾客行为很可能已经发生了变化。消费行为常常是不断变化的,只有用近期的行为数据来预测才比较准确。预测时遇到的第一个问题,就是即便行为没有发生变化,“过去”所包含的重复次数也不够多。
另外,对于近期才来店里或第一次才买某种产品的顾客,数据记录表明他们的购买频率很低,甚至为零。针对这些低频顾客,上述方法基本失效,那有什么新的办法吗?
除了低频顾客,新顾客也给预测带来了挑战。我们还用钱广的例子:钱广的店里最近来了个新顾客李中华(ID:lzh)。钱广没有他的任何购买记录;或者,虽然李中华买过一次醋,但还没有买第二次。钱广仅仅依靠李中华的一次购物记录,完全无法计算ID为“lzh”的顾客的购物时间间隔。那我们能不能用顾客赵轻松(ID:zqs)的购物间隔时间来预测李中华的购物时间间隔呢?
2、应对方案:寻找类似群体
用其他人的行为数据来模拟预测对象进而进行预测,在道理上应该是可行的。只要赵轻松和李中华两个人对醋的消耗量差不多。但钱广完全不了解李中华的背景,无法判断其消耗量。钱广根据当地的整体情况进行估计,假设李中华和赵轻松两个人吃醋的行为模式差不多。
如果当地的风俗差不了太多,每个人买醋都是为了吃饺子,而不是吃山西刀削面,则钱广就可以用与李中华相似的一群顾客的购买频率来预测李中华的购买频率。既然钱广也不知道顾客里面哪些人跟李中华更相似,那就简单一些,可以把所有顾客当作一个群体来用。通过统计这些顾客的购物时间间隔,仍旧可以得到类似于图1-1或者表2-1那样的结果。这就变成了能够解决的问题。
如果钱广将来有了更多的顾客行为数据或者背景信息,能够更准确地判断哪些顾客和李中华相似、哪些顾客和李中华不一样,则也可以只用相似顾客的信息进行预测。这其实就涉及将来要进行顾客细分的问题了。本书最后一章会讨论寻找相似顾客的方法,会使用其他的数据来判断顾客的相似性。或者,我们也可以通过营销活动调整或者改变顾客的购物频率。
还是回到本节所讨论的问题上。当有了一群和李中华相似的顾客的数据,我们应该如何预测呢?
之前预测顾客赵轻松的购物时间间隔时,思路是统计该顾客不同间隔天数出现的频次,既可以简单一点直接用平均值(误差肯定挺大),也可以复杂一点,用某种期望值仍然是10.3天的概率分布来表示。不论是哪种方法,本质上道理并没有变化。
现在要用顾客群的数据来预测个体行为,首先就需要预测顾客之间的差别。我们在学术上把这叫“异质性”(heterogeneity)。之前用过的平均值和期望值能够表示顾客群的整体情况,但无法表示顾客之间的异质性。如果用简单一点的方法,可以用方差或均方差来表示顾客之间的差异大小,核心含义(不是指公式)是每个顾客的取值和平均值的差异。顾客之间差异越大,方差应该越大。不过和平均值类似,它蕴含的信息还是不够充分,对现实世界的表示不够细腻。我们可以采用更为复杂的概率分布形式,以充分表示顾客之间的差异。
3、用例子来说明平均值和方差的差别
如果非技术背景的管理者觉得上述内容不易理解,可以想象以下情境:
情境A:用已知预测未知。相当于用一个人去年1—12月的收入预测他今年1月份的收入。
情境B:当这个人换了工作后,在新单位没有他去年的收入信息可用,如果想预测他今年1月份的收入,则只能用新单位类似岗位1月份的收入进行预测。
给情境A举个例子如下:这个人去年1—12月的收入分别是3、2、1、1、2、3、3、2、1、1、2、3,计数单位是万元。月收入相差这么大,是因为他干的是销售之类的工作,收入中很大一部分来自业绩提成。其中,他的收入有4个月是3万元,4个月是2万元,4个月是1万元,平均月收入为2万元。如果用平均值或期望值进行预测,则他今年1月份收入应该是2万元。如果用去年同期的数据进行预测,则他今年1月份的收入应该是3万元。不同方式预测结果相差50%。
给情境B举个例子如下:这个人的新工作是在某明星工作室负责对外联络。假设该明星名义年收入为1.2亿元(包含各种来源收入),即平均月收入为1 000万元。明星个人的平均月收入(1 000万元)和工作室另外9个人的平均月收入(合计10万元)加在一起再平均一下(1 010万元/10人=101万元/人),人均月收入为101万元。外人如果用平均值来判断是否值得去该工作室工作,则会觉得收入看起来不错呀。但如果看人群分布,只有1/10的人的平均月收入为1 000万元,其余9/10的人平均月收入1.1万元(即10万元/9人=1.1万元)。这样预测的误差也太大了。
从以上简化的例子可以看出两点:第一,如果顾客之间差异很大,就需要分成不同的群体分别预测;第二,简单地用平均值进行预测有可能误差很大。
我们现在简要回顾预测重复性行为的核心思想。如果有预测对象(如顾客)之前的行为记录,可以通过其过去行为预测其未来行为。如果没有该顾客的过去行为记录,可以使用与该顾客相似的群体的过去行为,来预测该顾客的未来行为。简单来说,就是“用过去代表未来,用群体代表个体”。
用“过去代表未来”的前提条件是顾客的行为模式从过去到未来没有发生变化,或者变化不大。如果变化较大,在预测的过程中就需要把这种变化考虑进去。这种情况下,预测的整体逻辑虽然没有发生变化,但预测的具体方法会变得更为复杂。类似地,用“群体代表个体”的前提条件是个体和群体相似。如果个体和群体相差太大,则不能简单用群体来代表个体。这时候往往要用到市场细分的逻辑,即把人群分成很多个小群体,从中找出与个体最相似的小群体,用该小群体的行为来代表要预测的个体。极端情况下,这个小群体甚至是一个相似的个体。
电商平台的推荐系统所用的逻辑也与此类似,分为找相似顾客和找相似产品两大类。找相似顾客通常不是看顾客在人口统计信息上的相似性,而是看顾客行为(主要是反映偏好的行为)的相似性。例如,两个顾客同样都买过什么产品、同样都评价过什么产品或者同样都对哪些产品犹豫不决等。从“买过”到“犹豫”,是在相似上从选择结果相似到选择过程相似的不断深入,乃至延伸到购物频率相似。其核心是从一些方面的相似性(例如购物过程和购物结果)来推断另外一些方面的相似性(例如购物频率)。当然,与此对应的是要分析的数据量和所需计算能力的成倍上升。相似产品则主要是根据产品特征或者顾客评价的相似性进行判断,与判断相似顾客的整体逻辑类似。
有了对预测所采用核心思想的理解,下一章就可以展开讨论各种具体的预测方法了。这时需要引入数学或者统计方面的一些知识和表达方式,看起来会稍微复杂。不过核心思想并没有变化,仍旧是本章所说的这些。
欢迎诸位企业家朋友随时与朗玛峰团队沟通交流