

第四章介绍了计算顾客生命周期价值的方法。计算的内容主要涉及顾客每期贡献的价值、顾客跟企业交互的总期数(生命周期的时间长度)和顾客总数。
上述计算方法假设顾客之间不存在相互影响。实践中,现有顾客即便与潜在顾客完全不认识,也会通过其行为影响后者。经常看到的顾客“扎堆”“凑热闹”都是这个意思。只不过当一个企业的顾客数量少的时候,这种相互影响导致的结果不够重要,因此在建立模型的时候常常会被忽略掉。当一个企业的顾客数量较多时,潜在顾客会有更多的机会观察企业现有顾客的行为。这种相互影响就会发挥较大的作用。除此之外,如果企业顾客中包含影响力大的顾客,例如明星、专家等,他们即便数量不多,造成的影响仍不容忽视。我们如果希望通过模型预测得更为准确,在建立模型时就需要考虑顾客之间的这种相互影响。
除此之外,有些行业(例如社交电商)本身就是依赖现有顾客对潜在顾客的影响获取新顾客或者利用现有顾客相互之间的影响提升重复购买率。在这种情境下,企业在计算顾客单期的价值和顾客总数时,更不能忽视这种相互影响。
本章讨论在建立模型时如何从底层逻辑上引入顾客之间的这种相互影响。
一、衡量现有顾客的影响
现有顾客的影响力可能来自多个方面。例如,使用产品(被人看到使用华为、苹果手机)、使用服务(去某个商场形成的客流、被路人看到提着印有某logo的购物袋)或者主动发声(私下或者公开的口碑传播)。从最隐晦的使用到最明确的口碑传播(word of mouth,WOM),都会对外界产生影响。
学者们针对现有顾客带来的影响,把影响产生的结果做了概念性区分,分为customer influence effect (CIE)和customer influence value (CIV)两类。CIE通常指非金钱方面的影响,例如使用或者口碑传播,CIV则指可以用金钱衡量的,例如购物金额。我们也可以从间接和直接的角度理解,CIE间接影响顾客价值,CIV则直接影响顾客价值(从企业角度看就是销售额和利润)。
1、衡量现有顾客单期影响力大小的概念模型
按照之前章节的思考逻辑,我们总是先考虑单期,再考虑多期。顾客单期的行为也会对未来多期产生影响,这就像企业今年做广告,到明年还会有些影响是一样的。本章的重点是说清楚针对影响力建立模型的思路,因此,只集中考虑单期。多期的影响力可以按照计算顾客生命周期价值的思路,对未来影响做折现处理即可。当然,如果采用更为复杂的思路,认为模型中的变量在每期都会变化,则仍旧可以依照上一章的思路做对应的处理。目前先以单期为核心考虑问题。
衡量现有顾客单期的影响力需要考虑两个方面,一是影响面的大小,二是影响的强度。前者(即影响面的大小)主要涉及影响多少人。大V、公众人物、网红人物的影响力,主要说的是他们的影响面大。他们的一言一行因为关注的人多,会对很多人产生影响。后者(即影响的强度)主要涉及影响的效力。这又涉及行为类型(行动还是口头)和关系强弱。信息源的专业度会对影响的效力产生巨大的影响,例如,专家更可信,有更多使用经验的用户更可信。信息源的专业度主要是在广告领域研究,本书主要针对的是普通顾客之间的相互影响,因此不涉及信息源专业度的领域。
就影响强度中的行为类型而言,同样的人其行动比语言更有效力。例如直接购买、使用产品通常比仅仅说产品好的影响更强。当然,这样的行为应该是有明确指向而不是难以理解的。
就影响强度中的关系强弱而言,直接关系比间接关系的关系强度要高。因此,直接信息比间接信息效力更大。例如,直接看到或听到比转手来的信息效力更大,亲近(接触较多)的人的信息比其他人的效力更大。除此之外,两个人建立关系的时间越久,可能导致关系越强。这种关系强度不仅与时间长短有关,还受到保持这段关系的过程中双方互动的次数影响。也许关系保持时间对关系强度的影响并不是线性的,但这两个变量之间肯定有相互影响。
按照上述分析逻辑,可以提出一个现有顾客影响力的概念模型,即
单一顾客的影响力=单一顾客所影响的人数×平均影响强度
这是一个概念模型。其中的影响强度用的是平均值。公式中用平均值能够把含义说清楚,但在大数据时代不够精准。
如果数据能够精确到具体用户和行为层面,就可以使用更为精细的概念模型,即
单一顾客的影响力=某行为的影响强度×该顾客与被影响对象1之间的关系强度
+某行为的影响强度×该顾客与被影响对象2之间的关系强度
+…
+某行为的影响强度×该顾客与被影响对象n之间的关系强度
其实质是这样的:
(1)对不同行为(行动或语言)做了细化分类,可以根据应用场景对两类行为的影响强度做细化标定。
(2)即便是同样的行为,其效力还受到影响方与被影响方双方关系强度的调节,因此把关系强度作为系数考虑了进去。
(3)因为同一顾客跟不同人的关系强度不同,所以这里采用加和的方法,而不是用第一个概念模型那样的平均值。
(4)单一顾客的影响面与其影响对象的数量有关,因此,这里一直从1加到n,把单一顾客能够影响的所有顾客都包括了进去。
按照类似的思路,只要数据足够详细,模型还可以建得更为细化一些。反之,如果数据本身的颗粒度不够小,例如只有群体数据而没有个体数据,则模型可以建得粗一些。模型的细化程度取决于最终需要处理的数据的颗粒度。
2、衡量现有顾客单期影响力大小的实际模型
现在回到实际生活中的某个场景,就以大家常用的微信(是个App)为例吧。假设你把一条汽油价格要涨的信息发给了两个同事,他们都很信任你,又把这条信息各自转发给了一个好友。收到这个消息的人都在油价上调前给车加满了一箱油。简单计算你的影响力可以发现,你发给两个同事,产生两个影响。他们看到后100%相信,各自又转发了一条,产生额外的两个影响。你在社交网络上的影响力一共是4条信息,实际效果是4个人去加了油。
学者们按照类似的逻辑,建立了如下模型
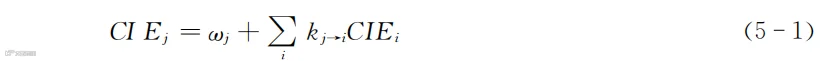
CIEj代表顾客j的影响力,它包括j直接影响的人数ωj(也可以用j所发信息直接送达的人数或所发信息条数代表),kj→i代表j对另一个顾客i的影响效力,CIEi则代表受到影响的顾客i的对外影响力。式(5-1)的整体思路是计算顾客j直接发布的信息加上他影响别人所伴随的转发数量。用刚才说的加油的例子,我们应该很容易理解式(5-1)在计算什么。
计算的过程是从最末端的顾客i开始算起,一直计算到j。我们只要理解了公式的含义,能够明白它是在计算什么即可。真正计算的时候,是写程序代码计算,很可能还会引入矩阵来提高运算速度。那些都是计算机程序的事情,甚至直接调用写好的程序包即可,不用过分担心这些细节。
计算清楚了影响力,就有办法从顾客生命周期价值的角度把这种影响折合成价值了。折算价值的逻辑与式(5-1)类似,一是计算对接收方顾客生命周期价值的直接影响,二是计算接收方对他人CIV的间接影响。具体的计算模型如下所示:
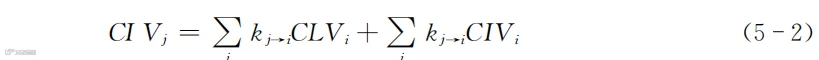
式中,CIVj代表顾客j的影响金额价值,实际计算时也是从最末端的顾客i开始计算。
本节最先介绍了计算影响力的基本思路。按照此基本思路,可以有多种计算内容和计算方法。之所以构建了如式(5-1)和式(5-2)这样的模型,是因为这两个公式所依赖的数据恰好是学者们能够从现实场景中获取的一类数据。如果获得的是其他类型的数据,则仍可以按照基本思路构建对应的模型。
仍以式(5-1)和式(5-2)的模型为例,在公开的社交网络情境下,顾客j在社交媒体上(Facebook、Twitter、微博)发布的信息是可见的,他的好友或者关注者也是可见的,好友是否转发了信息也是可见的。当然,因为是个多层连接的网络,要描述整个网络很复杂,但如果聚焦在单层网络上,并不算复杂。我们通过某个企业的内部数据能够看到顾客的购买时间和购买金额(或购买量)。企业只要看看自己发起的传播活动所直接影响的第一批顾客,然后把所有顾客受到影响后改变的销售额计算出来,就能够判断顾客相互影响最终产生的价值。最初的传播活动可以是企业发起也可以是顾客自发发起的,只不过如果是企业发起的活动,企业自身更容易剥离数据。同时,活动可以是企业发起的,但传播常常是不受控的。因此,受到传播影响的不仅仅是企业现有的顾客,也包括潜在顾客和其他无关人员。企业计算传播价值的时候,尤其是计算传播引发的直接顾客生命周期价值变化的时候,更多的是针对现有顾客和新顾客,而传播影响到的非顾客并不计算在内。
现实生活中,社交电商(例如拼多多目前的模式)经常通过发起或者支持类似的传播活动,实现获取新顾客或者找到新买家的目标。
3、衡量现有顾客多期影响力的变化
刚才是按照单期来计算顾客的影响力,如果想计算顾客多期的影响力,所采用的逻辑仍旧是对多期的CIE或者CIV求和。只需要按照第四章的方法,把顾客生命周期的总期数(有新增或者流失)考虑在内即可,但加和时要考虑未来影响力的折现。如果认为顾客每期的CIE或者CIV都一样,则可以不采用加和的方法,而直接用单期值乘以总的期数即可。
如果认为所有顾客都一样,则可以用单个顾客的数值乘以顾客总数,这就能得到企业整体的数据。如果认为顾客之间有差异,则可以采用概率分布的期望值来代表典型顾客。这些思路都是第三章和第四章介绍过的。
如果考虑到每期的变化,也可以按照第四章介绍过的方法处理。一种方法是按照每期概率分布的期望值计算,即类似于式(4-9)的思路。另一种方法是先设定一个每期不变的基础值,然后考虑各期在基础值之上的变化。计算方法可以是“basevalue+Δ”(类似于式(4-10)),也可以是基础值的指数形式,即basevalueΔ。Δ是delta的符号,通常代表增减量。Δ受到顾客(特征、行为)、企业(营销活动)和竞争者(营销活动)三方面的影响。区别只在于这里计算的是CIE和CIV,在做数学变换时,把多期数据按照线性的“basevalue+Δ”或者指数的“basevalueΔ”代入公式即可。这些只是一些数学上的变换,建立模型的思路本身并没有大的变化。
二、优化企业激励顾客相互影响的策略
有了第一节的基础,我们就能根据顾客的影响范围及由此引发的个体和群体生命周期价值的变化,量化顾客的相互影响。有了量化结果,企业就能据此优化自己在激励顾客相互影响方面的策略,以此提高企业业绩。
优化顾客之间的相互影响需要完成三个步骤的工作:第一,判断两人之间是否存在直接联系;第二,判断一个人发出的信息(信号)是否被另一个人看到;第三,预测接收信息的人是否因此采取了某方面的行动,例如传播信息或者购买产品。
本节将介绍如何针对上述三个步骤建立分析模型。
1、判断两人之间是否存在直接联系
以常见的互联网用户互动为例。这里所说的用户可以是顾客、消费者、网民或者其他称谓,取决于模型所针对的场景。网上的互动有“平等互动”和“主次互动”两类:平等互动的双方类似于微信(或Facebook)上的好友。两个用户是相互平等的,存在相互引用、转发的可能。主次互动的双方则类似于微博(或Twitter)上的用户。通常一个是博主,其他人是粉丝。博主发布信息,粉丝浏览、点赞(或者转发)信息。信息传播基本是单向的,很少有博主转发粉丝的信息。式(5-2)考虑的是单向影响,我们也可以按照双向影响分别计算微信(或Facebook)这种平等互动的情况。
判断两个用户之间是否存在直接联系,可以通过分析两者的共同特征来实现。这些特征通常是从基于具体情境的特定数据中提取得到,例如,两人是否都对对方的信息有所响应(例如点赞);两人关注或者讨论类似的主题或有相似的观点(更容易被对方看到);两人都属于同一个群体(容易在列表中相互看到)。诸如此类的特征,都是影响两个人是否建立起直接联系的因素。
实际研究时,虽然应该先从理论上分析影响两者关系的因素,但为了确保数据的可获得性,往往是先看企业具备了什么样的数据,然后才从理论上做初步分析,看哪些数据会影响两者建立联系。如果处理数据用的是计算机领域的范式,则经常会采用特征工程的方法,让计算机去寻找和确定哪些因素会造成影响。不少机器学习的方法挺有效的,但因为分析过程难以解读,本书不深入探究这个领域的方法。我们还采用基于理论的分析来看哪些因素会影响两者建立联系。
学者们基于理论,建立了预测两个人是否有直接联系的概率模型,模型的表达式如下所示:
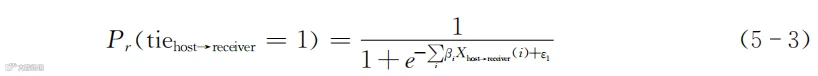
我们先不看式(5-3),先回顾一下第四章中的式(4-8),如下所示:

两个公式虽然细节不一样,但似乎有共同之处。你如果仔细阅读第四章,会发现第四章第三节提到过这样一个函数:y=1/(1+e^(-x))。当x=[-∞,0,∞]时,y=[0,0.5,1]。也就是说,不论x如何变化,y都落在0~1这个区间内。这个函数有名字,但这里不列出了,以免分散注意力。
基于y=1/(1+e^(-x))这个函数,式(5-3)和式(4-8)其实是一个逻辑,都是为了把自变量转换成0~1之间的某种概率。式(5-3)等号左边表示的是信息发送者和接收者有直接联系的概率,等号右边是如何计算这个概率的表达式。其中i代表双方特征的某个方面,例如关注相似的主题、有相似的观点等。在电商场景下找两个相似用户时,也是看他们在各种行为上的共同点或者距离。至于更具体的思想大家可以参考第七章推荐系统设计的逻辑,这里先不展开讨论细节。式(5-3)等号右边e的指数的表达式其中的i就是判断用户相似的某个方面。Xhost→receiver(i)可以当作两个用户相似的评分或者距离。βi则是这个相似方面的参数,可以当权重来理解。ε1通常都是指残差,这个符号可以形象地理解为error的第一个字母。ε1通常有不同的分布估计,有些设定它服从正态分布,有些设定它服从其他分布。设定的不同会影响模型的叫法。不过,此处不必在意这些细节。我们甚至仍旧可以按照y=a+bx来理解,把ε1当作其中的a来理解。只不过,在式(5-3)中,我们看到的y是位于指数的位置。
式(5-3)就是计算两个用户之间的共同点,或者用计算机技术领域的思路,计算两个用户在各种行为上的距离,然后通过类似于y=1/(1+e^(-x))的形式,根据两个用户在多个维度上的距离判断他们有直接联系的概率。
2、判断信息是否送达或者被接收者看到
确定了两个用户有直接联系后,下一步就是看信息是否送达或者被接收者看到。有了第一步积累的数学模型的基础,这一步就很容易理解了。
我们还是用第一步的思路,认为一个信息能否被看到,受到多个因素的影响,然后把数据中包含的那些因素X,采用与y=a+bx类似的线性思路,对应具体信息能否被看到。数学表达式就是:
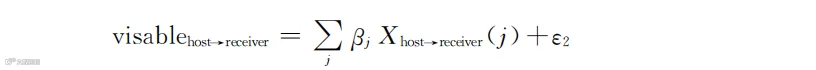
这个表达式的思路和外观与式(5-3)是一样的,差别是i换成了j,但都是代表两个用户有关的某些特征,它可能和第一步涉及的特征一样,也可能不一样,或者有一些共同的部分。这里的X和式(5-3)中的X含义一样,表示某个特征的具体值:如果是同样的特征,则此处的X和式(5-3)中X的值是一样的。ε2的含义仍旧是剩余的那个值,与第一步中ε1的含义一样,只是数值不同罢了,通常按照服从正态分布来处理。然后我们还是用y=1/(1+e^(-x))的形式,判断信息能否被看到的模型如下所示:
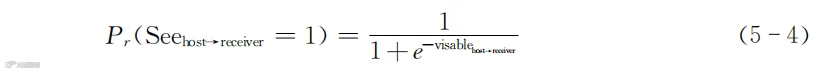
式(5-4)和式(5-3)的表达式类似,目的是预测信息被看到的概率。
3、预测接收信息者的行为概率
第一步计算了两个用户是否有直接联系,第二步计算了信息是否送达或者被看到。关联用户看到信息后,会有转发(或者购物)的可能性。第三步则要预测信息接收方采取行动(转发或者购物)的概率。我们仍旧可以采用与式(5-3)或式(5-4)类似的思路,用类似于y=1/(1+e^(-x))的形式预测行为概率。
实践中,因为能够获得总体转发概率的数据,所以学者们采用了新的建模方式,但都认为人群存在一个基础转发概率(或购买概率),各种内外部因素是在此基础比率的基础上影响具体用户的行为。
如果认为内外部因素X对转发概率Y的影响是线性的,可以建立y=a+bx这样的模型,其中a作为基础转发概率。学者们通过测试,发现转发概率和内外部因素之间的关系用非线性描述更好,相当于建立一个类似Y=ab^X这样的模型。实际的模型如下所示:

式(5-5)中的h表示转发概率,hm,host表示用户看到某条信息m(即message的缩写)后,作为发送者host的转发概率。式(5-5)等号右侧的h0是基础转发概率。h0既可以是群体的基础转发概率,也可以是特定个体的基础转发概率,即h0j。
当企业有充分的个体层面的历史转发数据时,可以逐一计算每个用户的基础转发概率,或者用群体数据中的概率分布来推算每个用户的转发概率。如果数据不够精细,无法剥离出每个人的转发概率,则也可以用群体数据拟合出这个群体的基础转发概率。例如,一个由n个用户构成的群体,收到q1条信息的情况下,一共对外转发了q2条,据此算出群体的转发概率大致是h0=q2/q1。这个表达式只是为了说明思路,实际的计算当然没这么简单,有可能收到1条信息,转发了5次,如果直接用h0=q2/q1=5,转发概率都超过1了。但无论如何,我们有了一个代表群体转发概率的基础概率,然后可以在此基础上个性化预测每个人或者每条信息的转发概率。
式(5-5)等号右侧e的指数中k代表影响转发的某个方面,例如,可以用k=1代表话题的热度;用k=2代表信息接收者对话题感兴趣的程度,依此类推。Xm,host(k)代表该方面的X的值。例如,如果X的取值范围是1~10,k=1时,x1=5代表这个话题的热度中等;k=2时,x2=10则代表信息接收者对该话题很感兴趣。整个值是第m条信息的话题热度、信息接收者对其感兴趣程度等各方面的整体反映。它通过指数形式(即当作e的指数)在h0的基础上,通过调整形成最终的hm,host。注意, hm,host和h0实际上可以指同一个人。只不过在等号左边他是充当发送者的角色,在等号右侧他充当信息接收者的角色。
如果想预测某条信息整体的转发概率,同样可以采用公式(5-5)。这时k对应的是用户,X又包括x1, x2, …,xn,对应用户的各个方面。其他参数的含义类似。综合起来预测某条信息m的总体转发概率hm,host。
4、优化激励相互影响策略的思路
我们用式(5-3)得到了两个用户有直接联系的概率,用式(5-4)得到了信息送达或被看到的概率,用式(5-5)得到了看到信息以后采取行动的概率。将这三个概率相乘,就得到了某两个用户相互影响产生效果的概率。企业优化相互影响策略的方法,就是找到三个公式中所有的参数β,使得最后的这个概率最大。
欢迎诸位企业家朋友随时与朗玛峰团队沟通交流