

五、特征选择、决策树的生成和剪枝
通过一个例子了解了决策树的分类基本思想后,我们来重新审视图 6-5。图6-5涉及三个特征,分别是性别、购物频率和年龄。哪一个特征应该首先用于分类,取决于用它分类以后子集的纯度提升水平。从概念上思考,决策树的分支节点的纯度可用该节点所包含的个体属于同一类别的比例表示。例如,如果存在一个性别节点,分类后一种情况是女性占比90%,另一种情况是女性占比50%,则前一种情况下的纯度就高。如果反向衡量不纯的程度,则后一种情况不纯的程度更高。
要让计算机程序自己找出一个类似于图6-5那样的最优分类过程,通常要包括特征选择、决策树的生成以及决策树的剪枝三个步骤。信息熵和基尼系数是找出最优(即纯度提升程度最大)特征的基础,学者们以此为基础研究了选择特征的方法。生成决策树就是每次迭代前找到最优特征作为节点,将训练数据进行划分的过程。划分完成以后,计算机程序找到最优的决策树(即先用什么特征进行分类,再用什么特征进行分类……)。这其中也包括找到每个特征具体进行划分时的最优阈值,例如每月来购物多少次可设定为区分高频和低频的阈值。计算机程序得到了这样一个分类规则后,就可以用测试数据检验一下是否满意。如果可行,计算机程序就会保存这个分类方式,然后就可以用于实际预测了。剪枝则是通过设定一些标准,使得决策树不会为了追求训练数据的分类精度而过度分支,以便最终形成的决策树能够在测试数据上也有较好的分类效果。
我们下面先介绍衡量分类纯度的指标。决策树正是以此为标准才知道如何判断每次迭代分类时的最优特征是什么。
1、衡量纯度变化的指标及算法
在决策树方法中我们不衡量纯度,而是反向衡量不纯的程度。衡量不纯程度及其变化,有三种重点不同的指标,即信息增益(1986年提出的ID3算法采用)、信息增益率(1993年提出的C4.5算法采用)和基尼系数(1984年提出的CART算法采用)。其中,信息增益主要代表分类前后纯度的变化值,可以首选信息增益最大的特征用于分类。信息增益率是用信息增益除以信息熵,解决了多分类特征本身信息增益就大的问题。基尼系数则是用不同于信息熵的思路来衡量不纯程度。
(1) 信息熵
信息增益的基础是信息熵(information entropy)。你不用在意概念和含义的细节。通常一个变量的信息熵越大,它所包含的各种可能性越多,“不纯程度”就越高。略去前人提出这个概念的过程,只集中于其计算方法。信息熵的计算公式如下:
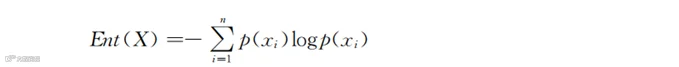
式中,Ent是Entropy 的缩写,也有用符号H表示的;n代表x这个变量(对应的是表6-1中的某一列)一共分成的类型数量(例如性别列有男性和女性两种类型,则n=2);p(xi)代表对应的类型i出现的概率(例如图6-1中男性出现的概率是30%),实际就是当前样本中第i类个体所占的比例。
我们可以用p(x高)代表购物频率高这一类型的顾客所占的比例。如果数据集中的样本容量是100(即假设表6-1一共有100行),而样本中购物频率为高的顾客有20个(20行),则p(x高)=0.2。
如果是二分类变量,例如数据中的顾客流失状态(1代表流失,2代表活跃,对应的是x1和x2),则该变量的熵值即为:
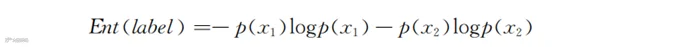
我们很容易通过样本中流失和未流失(即活跃)的顾客所占的比例,计算出p(x1)和p(x2),进而得到Ent(label)的值。
(2) 信息增益(ID3算法采用)
信息熵反映了变量的不纯程度。如果把分类前后的不纯程度相减,就可以得到一个反映分类前后纯度变化的指标。信息增益正是按照这样的思路计算的。信息增益指的是使用某个维度(特征)进行分类前后的信息熵的变化。
这里说几句题外话。营销领域是按照自变量(即x)和因变量(即y)来思考问题,希望通过建立理论来解释x是如何影响y的,并据此解决如何通过x来预测y的问题。机器学习源自计算机领域,虽然并未脱离x和y这样的影响关系,但更多的是关注两个变量之间的对应关系,而不是建立两个变量之间的解释关系。因此,机器学习领域很多时候并不采用x和y这种隐含自变量和因变量含义的符号,而只用Data或D这样的符号来表示。所用的概念常常是“分类”之类的中性词而不是“预测”。
下面切换到计算机领域的用语,来看看如何计算信息增益。仍用表6-1对应的例子来解释。
假设表6-1中的15行数据就是所有用户的数据。现实中,机器学习主要用于处理海量用户的数据,几乎不会仅处理十几行的数据。不过,用于这15个用户的算法与用于更多用户的算法并没有差别。我们关心的是用户状态是活跃(active)还是流失(loss)。这是一种活跃或流失的二分状态。表中显示,活跃用户有6人,流失用户有9人。仅看状态列,提前不做任何额外划分时,表6-1中数据的初始信息熵是:
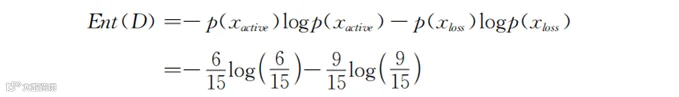
我们现在依据性别对用户流失状态进行划分,用户总数是15人,其中男性用户5人,用户状态为“活跃”的有0人,用户状态为“流失”的有5人;女性用户10人,用户状态为“活跃”的有6人,用户状态为“流失”的有4人。我们先计算男性群体的信息熵。注意,这个时候样本容量(仅限男性)为5人。计算过程如下:

上述公式等号左侧括号中的“|”表示条件概率。“Ent(D|gender)”意为按照性别(gender)分类以后,原有数据(D)对应的15个用户的信息熵。其中,因为男性只占总数的5/15,所以需要用Ent(male)乘以这个比例。女性占10/15,所以Ent(female)也需要乘上这个比例。
我们可以换个例子想想为什么要乘上这个比例。假设高中考试有物理、化学和理化综合三套考卷,都是100道选择题,满分也都是100分。学生有两种选择:一种是直接用理化综合试卷考试,得到的直接就是“理化综合成绩”。另一种是分别用物理试卷和化学试卷, 然后用“物理成绩×50%+化学成绩×50%”折算后作为“理化综合成绩”。计算Ent(D|gender)的逻辑就类似于这个道理。
我们现在有了状态列不用任何指标进行分类之前的信息熵Ent(D),也有了用性别进行分类之后的信息熵Ent(D|gender)。二者的差值,就是信息熵的变化值,信息熵的降低正好表示纯度的提升。这种信息熵的变化被称为“信息增益”,用Gain(缩写G)来表示。用性别进行划分以后的信息增益就是:
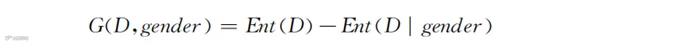
现在我们有了单独用性别进行划分以后得到的信息增益或者提高的纯度。注意,这是类似于图6-1的单层分类。
类似地,我们也可以分别计算用年龄(age)进行划分的信息增益。在表6-1中年龄分成了老、中、青三类,分别对应老年人5人(其中1个“活跃”,4个“流失”),中年人5人(其中2个“活跃”,3个“流失”),青年人5人(其中3个“活跃”,2个“流失”)。分成老、中、青三个群体以后的信息熵分别为:
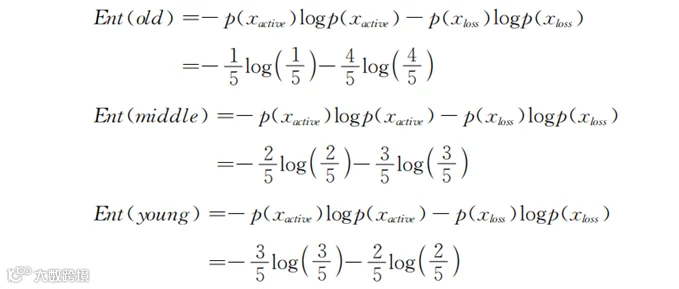
综合起来看,使用年龄进行划分之后总体的信息熵是:
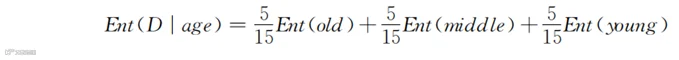
我们同样也能得到单独使用年龄进行划分之后的信息增益或提高的纯度,即G(D,age)=Ent(D)-Ent(D|age).类似地,我们也可以计算得到购物频率(frequency)的信息熵及其增益。表6-1中购物频率划分为高频(对应高频购物列中的“是”)和低频(对应高频购物列中的“否”)两类。按照与计算按性别分类相同的方式,能够得到:G(D,freq)=Ent(D)-Ent(D|freq)。
G(D,gender)、G(D,age)、G(D,freq)的含义是对应的分类方法对纯度的提升作用。现在,只需要比较这三个值哪个最大,就可以知道进行第一层分类的时候应该首先采用哪个指标(对应表6-1中的某一列)了。
划分完第一层之后,接着用其余的指标(表6-1中的其余列),按照上述同样的过程,分别计算i=1~n时的G(D,列i)。然后选出最大的 G(D,某列),接着将这一列作为下一层分类的指标。如此重复,一直到满意为止。满意的标准和潜在的问题后面再说。
之所以每次都是用其余的“列”开始下一层的分类,是因为进行上一层分类时,已经用了某列(例如性别),分出的每个分支已经只有单一值(例如男性)。如果还用这个指标(例如性别),就会分不出新的分支。
简言之,当有多个“特征”(也叫“维度”或者“指标”,对应表6-1中的多列)可以用于对数据进行分类时,每次应该采用导致信息增益(纯度提升)最大的指标作为分类的节点。信息增益就是选择节点的一个标准。
(3) 信息增益率(C4.5算法采用)
如果所有特征都是二分类的,用信息增益没有问题。人们在实际计算中发现,采用信息增益法更容易筛选出具有多种分类的特征,而实际上这样分类未必比其他分类更好。例如,表6-1的年龄有老、中、青三个分类,按照信息增益法就更容易被选作初始节点。在极端情况下,如果依据姓名来分类,因为多数人姓名不同,会把每个人分成一类,纯度的提升是最大的,但这对预测用户流失完全没有帮助。
使用信息增益率有助于解决上述问题。信息增益率是用刚才计算出的某列的信息增益除以该列的信息熵。这一比值就称为“信息增益率”,用Gain Ratio(缩写即GR)表示。通常把某列当作一种属性,用“attribute”泛指,然后选择信息增益率最大的特征来作为初始节点。信息增益率的计算公式是:
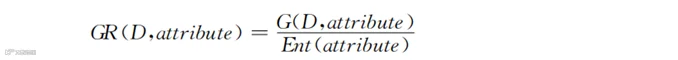
如果某列取值类型较多,虽然G(D,attribute)会变大,但同时 Ent(attribute) 也会变大,两者相除就会在一定程度上解决这些问题。
在表6-1中,我们把年龄分成了老、中、青三类。如果数据中的年龄是实际的数字,用信息增益率处理这类数据时还可以采用对年龄进行排序的方法,用排序后的年龄中的某些位置作为分类的阈值。另外,有时数据会引发Ent(attribute)等于零或者接近零(即分母为零),导致计算出的信息增益率不可靠。学者们想到了另外一些方法来解决这些问题,例如设法在分母中增加数据平滑的部分等。本书主要想讲清楚核心思想,这些细节就不再展开说明了。
(4) 基尼系数(CART算法采用)
基尼系数与信息熵一样,都是用于判断纯度,但采用的思路与信息熵不同。这里说的基尼系数和经济学上所说的衡量地区收入差距的基尼系数不是一回事。容易让人混淆的还有衡量食品支出总额占个人消费支出总额比重的恩格尔系数。
基尼系数(常用“Gini”表示)用于反映从一个数据集中随机抽取两个样本(可以理解为表6-1中的两行),其所属类别不一致的概率。从定义可以看出,Gini(D)的值越小,两个样本所属类别不一致的概率越小,当然数据集的纯度越高。
我们来看看这个概率是怎么计算出来的,以便读者理解基尼系数的计算公式。还是以表6-1为例,用户(对应于表中的某行)的状态无外乎“流失”或者“活跃”中的一种。因为分类模型不可能100%绝对准确,所以归类为“流失”的用户中也可能包含“活跃”的用户,反之亦然。假设某个算法把用户分成了“流失”和“活跃”两类后,其中“流失”这一类别包含m个用户。这m个用户中,实际流失的有n个,剩下都是未流失(即活跃)的,有m-n个。因此,标记为“流失”的用户中,实际流失的比例是n/m,而实际未流失的比例是(m-n)/m。如果从标记为“流失”的用户中任选两个用户,他们实际上不属于同一类别(即分别属于“流失”和“活跃”)的概率是n/m×(m-n)/m。如果把n/m记作符号p,p=n/m实际上正是代表概率,则n/m×(m-n)/m=p×(1-p)。同样,分类为“活跃”的用户中也会包含实际“流失”和“活跃”的两类用户。因为算法在分类(不论是“流失”还是“活跃”群体)上的误差是一样的,所以,在分类为“活跃”的群体中任选两个用户,他们不属于同一类别(即一个实际上属于“流失”群体,另一个实际上属于“活跃”群体)的概率也是p×(1-p)。
我们把依据算法划分的“流失”和“活跃”这两个群体中,任选两个用户而各自不属于同一群体的概率相加,就得到了整个预测结果中任选两个用户分属不同群体的概率。如果是k类别数,就相加k次。由此,得到基尼系数的计算公式,即
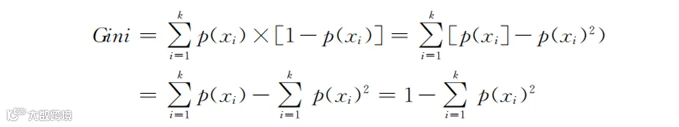
前面提到的信息熵的思想也是类似的逻辑,只不过因为涉及较多的背景知识,很难用简单的几段话解释清楚,本书就没有展开解释。读者从Gini系数的定义逻辑中也能体会个大概。理解核心思想是最重要的,而实际的计算依靠计算机程序。
有了基尼系数的定义,我们也可以按照前面Ent(D|gender)的算法,类似地计算Gini(D|gender)和G(D,gender),然后采用纯度提升水平最高的列作为每次分类时的初始节点。剩余的计算都是类似的,这里不再赘述。
2、生成决策树
确定了每次的最优特征(或者叫指标、属性、列等,都是一个意思)之后,剩下就是逐次按照此特征对数据集进行分类。“找出最优特征→分类→找出剩余特征中的最优特征→分类→……”就是一个计算机程序不断迭代的过程。整个过程并不是根据专家的行业经验,而是用计算机程序通过计算来选择每次最优的用于分类的特征。正是这种不依靠经验而是靠计算迭代找到最优特征的思路,使得决策树被认为是机器学习的一种方法。因为它符合机器学习的核心思想,即设定评判标准,然后由计算机程序找出最优值。
以上描述了一下计算机程序大概要完成的工作。如果实际工作中不进行大的更改,可以直接调用现成的决策树的代码包(例如Sklearn中的tree),就能生成预测结果了。
3、决策树剪枝
决策树的生成过程会不断地对数据递归分类,直到再也分不下去为止。其结果对训练数据表现很好,但应用于实际数据时分类结果则不够准确。因为前面设计的算法在训练数据上追求的就是尽量准确,这就是常说的对训练数据的过拟合问题。为了解决这个问题,需要在原有算法上补充一些判断标准,让算法在达到某种标准的时候就不再继续分类下去,以便提高分类算法的适用性(即不仅在训练数据上表现好,在对应实际情况的测试数据上也能表现好)。
决策树剪枝要解决的就是这个问题。“剪枝”顾名思义就是不让决策树分出过多的分支(分类)。不过这个概念不够严谨,表达的好像是剪掉了一些分支(包含有样本)。更准确一点说,其实不是“剪枝”,而是“停止分支”,就是不让某枝条再发芽生成新分支的意思。
“剪枝”又分为“预剪枝”和“后剪枝”。“预剪枝”的思想很容易理解,它在程序中的做法其实是在每次要开始新分类前,增加一次判断。如果符合某标准,就继续分类(分支)。如果不符合,则停止分类,那么这一支的分类就到此结束了。“预剪枝”的思想很棒,只是不容易找到最优的判断标准。“后剪枝”则是先进行彻底分类,然后把一些类别进行合并,看看这种合并(或者说“不分类”)对结果有多大的影响。如果影响不大,就尽量合并,这样形成的决策树最简单。
对于“后剪枝”,判断合并后的影响主要根据“损失函数”。“后剪枝”遵循损失函数最小化原则。损失函数的形式如下:
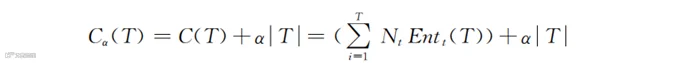
式中,T表示决策树的节点个数,它代表了决策树的复杂度;t代表具体的分支;Nt表示t这个节点的样本容量;C(T)代表模型(即决策树)对训练数据的拟合度;表示模型即树的复杂度;α是控制参数。因为“后剪枝”追求损失函数(即Cα(T))最小化,如果α较大,则模型复杂度|T|在Cα(T)中所占的比重就大,对其产生的影响就大,而拟合度C(T)所占的比重就相应减小。这样通过α来控制两个相互制约的部分(即“拟合较好”和“复杂”)谁发挥的作用更大。
4、以决策树为基础的随机森林方法
决策树的思想和方法虽然是现成的,但要生成决策树用于预测,首先要有样本数据提供给决策树的算法(例如本节提到过的ID3、C4.5和CART)。计算时一般会把样本数据分成训练集和测试集两部分,然后用训练集生成算法模型,用测试集检验模型的优劣。
算法程序虽然可以通过分析训练集生成决策树,并利用测试集进行检验,但最终目标仍是预测正常的业务数据。当样本足够大时,还可以从中按照有放回的抽样生成多个训练集,然后用每个训练集生成一棵决策树。这相当于构成一个决策树森林。
有实际业务数据需要预测时,如果采用单一的决策树,则只有一个预测结果;如果采用刚才生成的多棵决策树(决策树森林),则让森林中的每棵决策树都给出一个预测结果,然后少数服从多数,以此作为最终的预测结果。所谓随机森林中的“随机”,指的是分割训练集样本的时候,随机选择样本。
随机森林评估特征的重要性主要是依据特征在每棵决策树上的贡献,然后根据平均值做判断。贡献常用前面提到的基尼系数或者袋外数据(OOB)错误率来衡量。你可以简单地将后者理解成把样本的一部分装到袋子里,然后用袋子里的样本生成模型,用袋子外的样本通过筛选特征来改进模型。当然,其中还有很多细节,无法用一两句话解释清楚,但核心思想并没有太大的区别。
六、判断机器学习算法优劣的方法
第五节介绍了机器学习中的决策树算法,其实还有很多类似的方法,例如支持向量机(SVM)等。感谢各领域学者的努力和贡献,现在有了多种方法可用于解决同一个预测问题,例如分类或者回归。当存在多种备选方法时,如何选择或者如何评价每种方法的优劣呢?评价各种机器学习算法的指标中,最常用的是准确率、召回率、精确率三个。
1、评判模型优劣的核心思想
一个模型无论是用于分类还是用于回归,总是要服务于某个决策目标。例如,找出高流失风险顾客,找出可能会买东西的顾客,或者找出顾客最可能购买的产品等。我们希望通过某个模型或者算法能够从备选总体(例如所有顾客)中找出目标群体(例如可能流失的顾客)。目标群体是备选总体的子集。可以将备选总体当作一个大圈,而目标群体是大圈内部的某个小圈。预测的过程就相当于在大圈范围内画个小圈,希望这个小圈能够把目标群体包含在内。听起来这是顺理成章的事情,但实际构建模型时却并不容易取舍。
如果模型画出的小圈大一些,当然能把目标群体的所有成员都包括在内,但很可能会把很多非目标群体成员也包含在内。这就相当于汽车厂商要召回已经售出的有事故隐患的车辆,如果不做任何筛选,一股脑儿地把所有售出车辆召回,肯定能够把有隐患的车辆包含在内,但同时也召回了很多没有隐患的车辆。从确保安全的角度来说这样做当然没问题,但却增加了很多不必要的支出,造成了浪费。
如果模型画的小圈小一些,里面肯定都是目标群体的成员,但还会有一些目标群体成员没有被包含在内。这就相当于汽车厂商采用极其严格的召回标准,召回的汽车肯定都是有隐患的车辆,从成本的角度考虑这样做不会有任何浪费。但因为标准过严,所以还有一些同样有隐患的车辆没有包含在召回范围内。这虽然避免了浪费,但无法最大限度确保车辆安全。
车辆召回就是要在安全性和经济性之间找到均衡点。预测模型其实也遵照类似的逻辑,要在找到和误判之间实现均衡:既要尽量找到目标,又不能把范围设定得太大。
2、评判模型优劣依赖的数据
我们还以预测用户流失为例,用图6-6表示预测的结果:
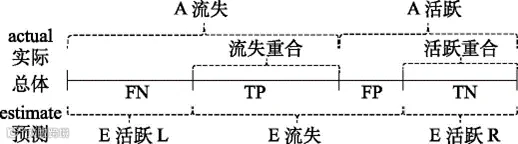
图6-6 用户的实际分类和预测分类的关系
图6-6中间的实线代表用户总体。实线的上方是实际流失和实际活跃的用户,下方是预测流失和预测活跃的用户。用actual(缩写为A)代表实际情况,用estimate(缩写为E)代表预测情况。实际流失的用户群“A流失”中的用户,有些被错误预测为活跃用户(即所标注的“E活跃L”,L即left),有些被正确预测为流失用户(即所标注的“E流失”的左半部分)。实际活跃的用户群“A活跃”中的用户,有些被错误预测为流失用户(即所标注的“E流失”的右半部分),有些则被正确预测为活跃用户(即所标注的“E活跃R”,R即right)。
假设预测模型关注的是流失用户,则用户流失标注为positive(缩写为P),用户活跃就标注为negative(缩写为N)。标注的原则是看要预测什么,所关注的用户类型标注为P,不是所关注的就标注为N。当然也可以关注活跃用户,道理和标注的原则是一样的。
图6-6代表总体的实线一共被分成了FN、TP、FP和TN四个部分。F代表false,T代表true。因为图6-6关注的是流失用户,所以将流失状态设为positive,活跃状态设为negative。其中FN(即false negative,其他缩写也是按照类似的规则)代表错误标注为活跃的,在图6-6中对应的是实际属于“A流失”但被误判为“E活跃L”的用户。TP(即true positive)对应实际流失也被正确判断为流失的用户。FP(即false positive)对应实际活跃但被误判为流失的用户。TN(即true negative)对应实际活跃且被正确判断为活跃的用户。
3、评判模型优劣的具体指标
从评判模型优劣的核心思想可以看出,预测时主要关心以下两方面的目标:
(1)要找的目标尽量都能找到:这时候就需要适当扩大范围。
(2)找到的目标尽量都是要找的目标:这时候就需要适当缩小范围。
基于上述目标,学者们提出了三个指标来综合评估模型的优劣,即准确率、召回率和精确率。
准确率(accuracy)表示找对了的目标占总体的比例,或者说“预测正确的数量占样本的百分比”。图6-6中包括对流失和活跃两种状态的预测,所以预测正确也包含正确预测出的流失和活跃用户,其分别对应的是图中的TP(预测正确的流失用户)和TN(预测正确的活跃用户)。预测正确的用户合在一起即“TP+TN”。可以看出,准确率衡量的是“找对”的比例,即
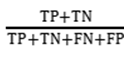
但是,准确率受到样本中不同类型用户所占比例的影响较大。例如,用户总数是100人,实际流失了90人,如果模型把这90人找到了,则准确率就是90%。这个指标看起来很有用,但其实受到用户构成的影响很大。就拿这个例子来看,用一个完全没有区分度的模型,把100个用户都预测为流失用户,仍旧有90%的准确率。所以,仅凭准确率指标不能很好地反映模型的优劣。
为了解决准确率受样本构成情况影响较大的问题,学者们设计了另外两种相互制约的指标,分别是召回率和精确率。
召回率(recall)顾名思义就是把该找的都找到。它表达的是实际找到的目标占要找的目标群体的比例。还以图6-6为例,在这个例子中,预测任务是找出要流失的用户,即“A流失”部分。而通过预测找到的则是“E流失”部分,其中真正流失的是TP部分。召回率反映的其实就是TP/(TP+FN)。如果预测的范围大一些,实际目标包含在内的可能性就大,召回率就会提高。从这个角度看,提高召回率和提高准确率会促使预测时尽量扩大范围,筛选的标准宽松一些。召回率也可以按照“查全率”来理解,反映模型把目标找全的能力。
提高召回率在找到更多目标的同时,会因为标准宽松包含很多非目标群体成员。为了平衡这种倾向,学者们提出“精确率”指标。精确率(precision)反映预测出的目标群体中确实是实际目标群体成员的比例。例如,当想预测流失的用户时,精确率反映的就是预测正确的流失用户占所预测出的总流失用户的比例,也就是TP/(TP+FN)。如果预测的范围太大,则“TP+FP”结果变大,这个指标就会下降。精确率也可以按照“查准率”来理解,反映模型预测正确的能力。例如某个样本被模型判断为某种类型,如果模型的精确率很高,模型的使用者就有把握认定这种判断应该是对的。
召回率和精确率相互牵制,有助于模型达到既能把该找到的都尽量找到又能尽量避免滥竽充数的平衡。
我们把三个指标放在一起对比一下,发现三者关心的都是找到正确的目标群体,即TP或者TN。但三者参照的范围不同,准确率参照的是整个样本(即“TP+TN+FN+FP”),召回率参照的是实际目标群体“A流失”(即“TP+FN”),而精确率参照的则是预测群体“E流失”(即“TP+FP”)。如果用公式表示,则是:

我们可以换个角度看这三个指标。当拿到某个模型的预测结果时,如果关心判断结果(可能是流失,也可能是活跃)对不对,要看准确率,它反映模型误报的多不多。如果结果显示某个样本处于流失状态,想知道这个结果对不对,要看精确率。如果想知道目标是否被找到,要看召回率。
4、采用机器学习进行预测的主要问题
第四节和第五节以决策树为例,介绍了采用机器学习的方法(主要是决策树)进行预测的基本思路。机器学习包含很多不同的具体方法,既可以用于分类也可以用于回归。本章通过介绍其中的决策树方法,希望读者能够对机器学习领域有个初步的感性认识。机器学习的方法很多,要想都讲清楚,足以写成若干本专著,这已经超出了本书的目标。
随着机器学习乃至深度学习相关研究的深入,机器学习预测模型的准确性有了很大的提升,在很多领域已经有了较好的应用,例如用于语音识别和图像识别。将机器学习的方法应用于营销领域时,在多个方面也取得了不错的应用效果。
机器学习的应用效果虽然不错,但利用算法或模型得到的结果的可解释性不好。也就是说,即便结果是正确的,模型本身除了能说这是算出来的之外,对于为什么是这样的结果,出现这个结果的原因是什么,给不出充分的解释。这在那些能够进行尝试的领域倒还不算大问题,虽然难以解释清楚,但只要试一试发现效果好,企业管理者还能下决心使用预测结果。但如果放到其他高风险、无法尝试的领域,即便模型给出一个结果,如果不能给决策者有关“为什么会是这样”或者“这样为什么不会有问题”的充分解释,他们会很难放心使用预测结果,这就会限制机器学习在实践中的应用。
欢迎诸位企业家朋友随时与朗玛峰团队沟通交流