

三、衡量相互影响对顾客流失的影响
在第四章计算顾客生命周期价值的时候,我们讨论过顾客流失(或对应的顾客保留)对顾客生命周期价值的影响。本节在此基础上,讨论顾客之间的相互影响对顾客流失或保留的影响。首先,要设计一些细化变量来衡量用户之间的相互影响。
1、衡量用户是否接触到流失或满意用户的变量
通常认为相互交流的人(可能是用户或者顾客)会存在某些相互影响。
交流可以有多种形式,通常是交互的。如果需要区分信息的传递方向,例如为了研究单向的影响,可以像第二节那样,明确划分单向的发出或接收信息。如果认为只要交流就会产生影响,关注的是谁影响谁,而不是交流的方向,则可以按照相互交流的人的角色来划分。例如,一个满意的顾客跟其他人交流,可能会提高那些人的购买概率。同样,一个不满意的顾客会降低与他交流的人的购买概率。如果放在顾客流失的情境中考察,则一个流失的顾客可能会提高与他交流的其他顾客的流失概率。从中可以看出,我们既可以像第二节那样就交流本身进行研究,也可以就交流产生的影响进行研究。另外一些研究还把交流细分为点对点(电话、直发短信、直发微信)或点对面(在微信群里发信息、发微博、写商品评论等)两类。如果更为泛化地思考这个问题,也可以认为邻居间、同事间存在潜在连接。这种潜在连接能否成为真实连接可能会服从某个概率分布。住宅社区或工作单位的规模越大,存在真实连接的概率越低。
企业通常有数据能够识别出某个时间段哪些是满意的顾客,哪些是不满意的顾客。例如,某段时间对企业有好评的顾客或者投诉后得到满意回复的顾客往往对企业比较满意,而流失的顾客往往对企业不太满意。我们可以从某个时间段的顾客评论、企业的投诉记录或者流失客户名单中识别出这些顾客。那些在这个时间段与上述顾客有交流的人,就会受到他们的影响。企业有可能也获得了这些顾客之间是否“交流”的数据。例如,电商数据中记录有某个顾客是否看到了某条评论(评论的内容涉及是否满意),电信运营商存储了哪些人和流失的顾客有过通话或者短信交互的记录等。
有了顾客身份(满意/不满意/流失)和交互记录,就能量化其他人(用户或者顾客或者潜在顾客)受到的影响。这种影响是否会导致顾客行为改变是第二节关注的重点。本节主要考虑是如何衡量影响本身。
为了保证表述更简单,我们就以流失顾客为对象,研究他对跟他交互的其他顾客的影响。这里的流失顾客当然也可以换成满意的顾客,或者具有其他特点的顾客。本书的重点是解读定义变量和建立模型的方法。读者完全可以把书中的方法应用到新的情境,研究其他类型顾客的相互影响。例如,研究社交电商用户的相互影响,或者研究团购场景中的团长和团员以及团员之间的相互影响。
学者们以流失顾客为例,定义了一个代表接触的变量,认为一个人只要与流失顾客有交流, 他就会受到流失顾客的影响。原始论文中用的是运营商存储的通话记录,即谁给谁打过电话。你去电信运营商那里打印自己的通话记录详单,原始论文用的就是类似内容的数据。变量的定义是:

式中,t代表第t期,具体含义取决于所用的数据,例如某个月;等号左侧的Exposurei,t代表用户i在第t期受到的影响的总和。等号右侧的SNi代表用户i在第t期的社交网络(例如某个月和谁有通话记录);j代表处于用户i的社交网络中的一个用户,就是和用户i有通话记录的某个人;δj,t表示用户j在第t期的状态,δj,t=1代表用户j在第t期流失了,δj,t=0代表用户j在第t期还是运营商的用户。因为研究关注的是流失顾客带来的影响,所以把δj,t=1设定为代表流失用户。
解释了半天,Exposurei,t其实表示的就是用户i在第t期合计与多少个流失用户有通话。注意,Exposurei,t不是表示通话次数,而是接触到的流失用户数量。我们可以想象一下,A、B、C、D四个人都是中国移动的用户,C和D采用“携号转网”的方式变成了中国联通的用户。中国移动标注C和D都流失了,但仍然可以记录到A和B、C、D三个用户是否有通话。如果5月份A只跟B、C有通话,则5月份A的ExposureA,5=1。因为B没有流失,所以δB,5=0;而C流失了,所以δC,5=1。合计下来即ExposureA,5=1。5月份A没有跟D有通话,所以D在5月份不处于用户i=A的社交网络SNA中。
回顾之前提到的预测模型,如下所示:

这些公式中都有一个大写的X。当时我们对这个X做过初步的解释,表示根据研究的主题和场景,X代表那些会对结果(即等号左侧的预测目标)产生影响的多种内部(顾客)或外部(企业营销行为)因素,但并没有进一步解释这些因素是什么以及如何测量。现在我们可以把Exposurei,t 理解成X代表一个x1,还会有其他x2,x3,…。用这种受到流失用户的影响来预测现有用户的后续行为(转发、购买、流失等)。
2、衡量用户之间交往强度的变量
一个用户要受到另一个用户的影响,除了需要有机会交往外,还受到交往量的影响。除此之外,有的人喜欢跟人频繁交往,有的人则不喜欢。所以,同样的交往量所产生的影响,还取决于它占总的交往量的比重。这类似于企业播出广告,效果不仅取决于本企业广告播放量的绝对值,还取决于同期全行业播放了多少广告以及用户看到了多少广告。
人和人交往的方式有多种,既可以是线下的当面交谈,也可以是打电话、发短信、发微信,或者其他线上活动。交往过程中,一个人会受到另一方影响或者影响另一方。实践中把哪种方式视作交往,取决于企业所在的行业和拥有哪种交往数据。本小节主要讨论如何衡量交往,所提出的变量适用于各种交往场景。
仍旧以两个人通话为例,学者们定义了一个交往强度(tie strength)变量,即

式中,TSi,j表示i和j两个用户的交往强度;Voli,j代表i和j两个用户的交往量,原始论文中是通话时间长度;Total Voli代表用户i当期与其社交网络所有用户的总通话时间长度。其他情境下,可以用发短信或发微信的条数替代通话时间长度。原始论文把一条短信折合成1分钟的通话时间。这种折合并没有经过拟合替代方面的检验,只是研究者的一种自由设计。TSi,j表示的核心概念是“用户i和用户j的交往量”占“用户i跟所有人的交往量”的比重。如果这个比重大,则用户i受到用户j的影响就大。
有了TSi,j这个变量的定义,回到本小节的主题,即用户i受到其他流失用户的影响。我们需要衡量用户i受到他所交往的所有流失用户的总影响。学者们定义了一个表示平均交往强度的变量,即
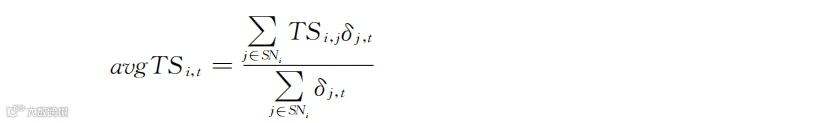
等号左侧的avgTSi,t表示用户i在第t期与流失用户的平均交往强度,等号右侧的分母表示用户i在第t期所交往的流失用户的总数。如果用户i某期一个流失用户都没有交往过,即=0,则定义avgTSi,t=0。分子不仅考虑了流失用户,还考虑了和流失用户的交往强度。δj,t仍旧表示用户j在第t期的状态,δj,t=1代表用户j在第t期流失了,δj,t=0代表用户j在第t期还是运营商的用户。
从含义上看,avgTSi,t既考虑了用户i和流失用户的交往量,还用其所交往的流失用户总数做了平均。变量avgTSi,t实际上表示用户i与其社交圈内所有流失用户的平均交往强度。此强度越大,则用户i受他们影响而流失的可能性越大。
3、衡量用户之间相似性的变量
虽然有忘年交、性格互补之类的说法,但在思考用户相互影响的时候,我们还是假设两个用户相似之处越多,相互之间的影响越大。例如,同年龄的人更容易认同对方的想法(比如偏好、决定等),同一个家庭的人、同样收入的人、同样教育背景的人更容易感同身受,因而受到对方的影响也更大。
衡量用户相似性其实是看两个用户在多少个维度上相似,所采用的维度取决于企业所掌握的数据。我们可以把企业所拥有的数据想象成一个Excel表,每一行代表一个用户,每一列代表一个维度。表格内容包括静态信息(性别、年龄、住址、教育、收入等)、动态信息和标签信息等。动态信息会随着时间不断变化,通常要经过计算得出,可能包括到店次数(实体店、电商数据)、通话时长(运营商的数据)、活跃时段等。标签信息常常是企业根据用户特征或用户在其他行业的行为特点对用户的标定。例如,有的企业根据用户手机安装的App种类,给用户打上理财、旅游、育儿达人等标签。当然,也可能从第三方购买到用户的这些标签信息。表格的形式可能如表5-1所示:
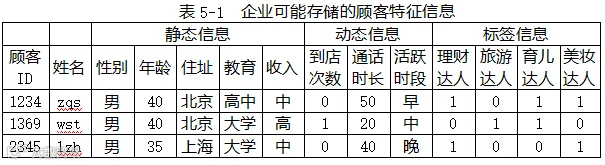
如果加以区分,我们可以赋予静态信息、动态信息和标签信息不同的权重。如果认为用户每个维度的信息具有同样的重要性,也可以给每个维度设置同样的权重。表5-1除了顾客ID和姓名之外的数据一共有12列,如果都采用的话,可以认为是12个维度的数据。如果两个顾客在这12个维度上都一样,则可判定他们的相似度是100%,如果只在6个维度上一样,则相似度是50%。
我们按照与衡量用户交往强度类似的思路来构建相似度变量(homophily),即

式中,Hi,j表示i和j两个用户的相似度;Similarityi,j表示i和j相同的列数;Total Dimensioni则表示i的数据一共有多少列。类似地,用户i和流失用户的平均相似度即为:

等号左侧的avgHi,t表示用户i在第t期与流失用户的平均相似度,等号右侧的分母表示用户i在第t期所交往的流失用户的总数。如果用户i某期一个流失用户都没有交往过,即分母=0,则定义avgHi,t=0。分子不仅考虑到流失用户,还考虑了用户i与流失用户的相似度。δj,t仍旧表示用户j在第t期的状态,δj,t=1代表用户j在第t期流失了,δj,t=0代表用户j在第t期还是运营商的用户。
4、利用行为数据计算用户满意度
除了顾客之间的相互影响外,影响顾客是否继续使用(购买)企业服务的因素还包括顾客的满意度等。
衡量满意度最简单的方法当然是直接询问顾客,例如让顾客用1~10打分之类的方法。不过,这种方法存在两方面的问题:一是顾客未必会真实反映情况;二是进行满意度调查本身有成本,难以长期持续,还存在抽样偏差或者愿意回答者偏差。
有越来越多的企业开始利用用户行为数据来推算顾客满意度。一种方法是看顾客的消费量。如果认为顾客需求是相对稳定的,当顾客某段时间的消费量持续下降时,就折射出顾客对企业的满意度下降。另一种方法是看顾客的投诉率。顾客不满意才会投诉,如果投诉增多,企业认为肯定是不满意增加了。
学者们用当期使用量(购买量)与过去几期平均使用量(购买量)的比值来衡量使用量(购买量)的变化,即
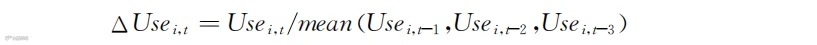
式中,t代表第t期,t-1代表第t期的前一期,t-n代表第t期的前n期。这里的定义考虑的是前三期的平均值,当然也可以根据需要使用之前的n期。或者不用平均值而是用其他方法得到一个预测值,例如通过趋势外推法得到一个值。Usei,t代表顾客i在第t期(即当期)的使用量或者购买量。如果Usei,t和平均值一样,则ΔUsei,t=1。如果Usei,t小于平均值,则ΔUsei,t<1。这表示顾客使用量或者购买量在下降,可能隐含着不满意。
投诉记录可以用Service Recordi,t表示,通常很少有满意的顾客打客服中心的电话,往往是不满意的顾客或者需要解决问题的顾客才会打电话。我们可以根据情况直接将打来电话的次数或者总的通话时长作为投诉数据。当然,如果行业特殊,或者有详细的文字记录,可以更为细化地把Service Recordi,t的记录分为正负等。
除此之外,通常要考虑一些控制变量对结果解读的影响。通常要考虑的控制变量包括两类:一类是涉及顾客人口统计信息的变量(Demography),例如年龄、性别、教育程度等;另一类是反映顾客和企业关系的时间长度(Tenure)、交易频繁程度等的变量。有的时候,我们还需要根据用户画像中的标签来区分不同类型的顾客。
5、引入多种影响因素预测顾客流失
在前面我们聚焦于如何衡量用户的相互影响,为此提出了多个变量并介绍了具体的计算方法。这些变量可以用在多种模型中,用于预测顾客流失等。下面根据是否考虑顾客之间的相互影响建立两类预测顾客流失的模型。
(1)不考虑顾客之间的相互影响
为了突出核心思想,我们先不考虑顾客之间的相互影响。例如,基于满意度建立的概念性流失预测模型:
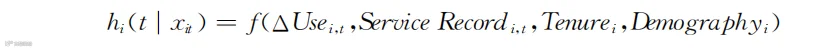
式中,hi(t|xit)表示顾客i于第t期在多种条件下的流失概率;xit涉及顾客使用量变化ΔUsei,t、顾客投诉情况Service Recordi,t、顾客第一次购买企业产品至今有多久Tenurei、顾客的人口统计特征Demographyi等。
如果采用这样的操作性实际模型,则上述公式可以改写为:
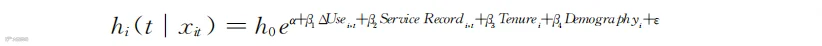
这个公式看起来挺复杂的,但其实仍旧是h=h0eX模型,只不过把之前没有展开的X的内容,也就是代表使用、投诉、关系时长和人口统计特征的那些变量,具体列了出来。
(2)考虑顾客之间的相互影响
如果把顾客之间的相互影响也考虑在内,可以在上述模型的基础上增加更多变量,即:

这里增加了更多的自变量,包括Exposurei,t、avgTSi,t、avgHi,t三个变量。
如果认为顾客之间的相互影响产生效果会有滞后,也就是说一个人知道其他人的情况(不满意或流失)后,其行为会有几期的滞后,则可以在模型中考虑滞后带来的影响,即

这里在前面模型的基础上增加考虑了前三期的影响(更早期的影响忽略不计了),对应的是Exposurei,t-1,Exposurei,t-2,Exposurei,t-3。
实际工作中,企业可以根据所处行业和决策目标尝试多种模型,选择其中最能满足目标的即可。
四、通过现有顾客的推荐获取新顾客
企业可以通过两个来源获取新顾客:一是直接通过各种营销活动(广告、促销)吸引新顾客,即常说的“拉新获客”;二是引导现有顾客推荐新顾客,即常说的“推荐获客”。
从企业自身的营销实践中发现,“拉新”获取新顾客速度快,但得到的顾客未必与企业匹配,顾客流失率高。随着潜在顾客不断转化为新顾客,“拉新”的成本越来越高。
现有顾客既了解企业的情况,也了解好友的情况。“推荐”获得的新顾客跟企业匹配度高,顾客的留存率更高。有些情况下,企业甚至没有渠道接触并影响某类潜在顾客,只能通过“推荐”的方式获客。
诸如拼多多这样的社交电商把“推荐获客”推向了极致。其关注点不仅是新顾客,还利用社交人群更为相似的特点,提高产品在同类人群中的分销程度。
本节先用一些理论模型分析现有顾客愿意向朋友推荐企业或产品的边界条件。然后再用实证模型介绍如何得出可执行的“推荐获客”最优方案。下文并不将实际的数据代入理论模型,而是以符号表示推导出各种变化的边界条件。这相当于弄清楚黑白两极,实践中的各种情况(相当于灰度)都属于两极之间的过渡状态。理论模型相对实证模型更为抽象,但有助于展现关键逻辑。实证模型则主要找出“获得的收益”减去激励推荐的“成本”后的利润最大化方案。
我们先从顾客决策的角度,分析顾客做出购买决策的边界条件。然后以此为基础,增加考虑顾客会向他人推荐企业或产品的边界条件。
1、顾客购买产品的概率
我们先从道理上分析顾客做出购买决策的边界条件,然后寻找一个能够计算这个边界条件的方法,最后据此得到顾客购买产品的概率。
(1)顾客购买产品的边界条件
顾客购买产品的前提条件是购买行为导致的收益大于支出——通俗点说,就是觉得这个交易“划得来”或者“值得”。例如,消费者觉得某产品的功能加上它的品牌,应该值500元(这就是“认知价值”)。如果该产品定价是500元或者低于500元,他就有可能购买。如果定价超过500元,他会觉得不值,也就不会购买。如果用公式表示,就是value-price≥0,缩写即为:V-P≥0
(2)可用于代表产品认知价值分布的概率密度函数
不同顾客对同一产品的认知价值会有差异。我们可以用在第三章学过的概率分布来表示同一产品在不同顾客心目中的认知价值。如果多数顾客感受到的认知价值差异不大,则其可以用正态分布来表示。如果多数顾客心目中的认知价值偏向左边或者右边,则其可以用有偏峰的Gamma分布来表示。如果顾客之间差异很大,两类顾客对产品的认知价值相差很大,则其可以用Beta分布来表示。第三章介绍了这些分布的表达式和计算方法,即
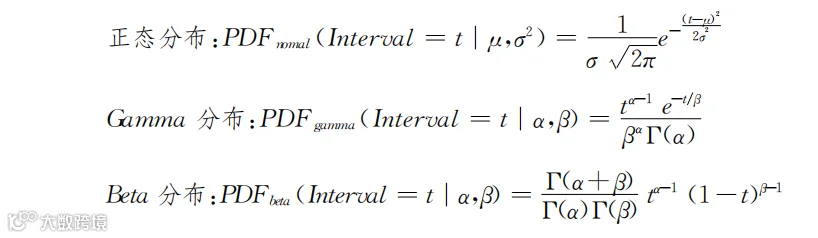
我们不必在乎这些公式有多复杂,只需关注公式需要几个参数,以及计算这些参数的方法即可。第三章介绍了如何用实际数据计算出这些参数和对应的分布的概率密度函数(PDF)。
(3)累积分布函数和概率密度函数的对应关系
数学上与PDF紧密相关的是累积分布函数(cumulative distribution function,CDF)。以正态分布为例,可画出其PDF和CDF,如图5-1所示:
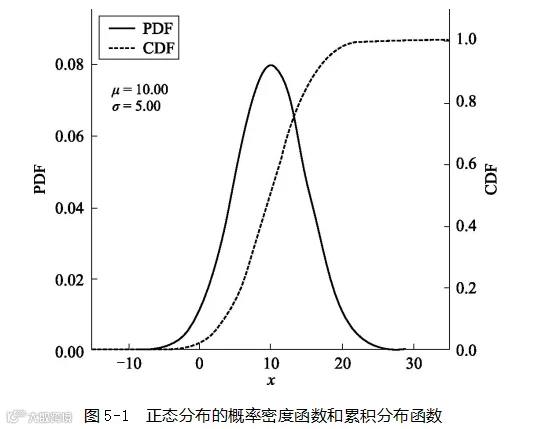
从数学含义来说,CDF是PDF从负无穷到当前值的积分,你可以把这里所说的积分理解为某一点左侧PDF曲线下方所包含面积的总和。积分原始的用途是把曲线下方分成无数个小的竖条,以便通过加总竖条的面积得到曲线下方面积的近似值。当分割成的竖条足够多时,此近似值接近实际值。PDF是CDF的导数,CDF是PDF的积分。我们也可以完全不用管刚才说的这些导数、积分之类的方法和关系,只需要了解有了PDF就能求出CDF,反之亦然。
我们从式(3-2)、式(3-3)和式(3-4)已经能够得到某种分布的PDF,采用某种数学变换(不管具体如何实现),最终能够得到对应的CDF。
(4)用累积分布函数反映变量小于某个值的概率
CDF的数学定义是F(x)=Pr (variable≤x),代表某个变量小于等于x的累积概率是F(x)。公式中用的是小写x,这就类似“y=a+bx”,其中x是自变量。随着自变量x的不同,因变量F(x)自然也不同。F(x)就表示其对应的某种概率密度函数(是一条曲线)在横坐标为x的某点左侧的累积概率。我们只要记得F(x)是个跟x有关的概率值即可。F(x) 括号中的符号是x还是其他符号无关紧要,也可以直接用F(*)表示,结果跟括号中采用什么符号无关。这就像式(3-2)所示的正态分布的形式是固定的,跟用什么样的符号表示无关。如果把σ和μ换成其他的符号也一样,只要计算方法不变就行。其他分布也是一样的道理。
扫除了理解PDF和CDF的障碍后,我们还是回到本节的例子中。不论最终采用的是式(3-2)至式(3-4)中的哪种,反正能够知道顾客对某产品的认知价值V的分布(就是在心目中觉得产品值多少钱)。有了V的PDF(V),自然也就能得到其CDF(V)(前面说过两者之间通过积分和导数能够相互变换)。通常,默认用F(V)表示V的累积分布函数。
企业可以通过做广告或者其他方式改变顾客对产品的认知价值。如果图5-1的横坐标代表顾客对产品的认知价值,则企业做宣传的目的,就是希望图中的PDF的波峰向横坐标右半部分移动,即希望觉得该产品价值高(靠右侧)的顾客多(概率密度高)。我们先讨论企业不施加任何影响时顾客群初始的PDF(V),它对应F(V)。不考虑企业宣传时,F(V)曲线就只与顾客有关。这种设定下,因为企业不影响顾客对产品的认知价值,企业只能通过改变价格来影响顾客的购买决策。
我们现在有了CDF的曲线F(x)=Pr (variable≤x)。如果关注的x是企业制定的产品价格P,则F(P)就表示产品认知价值V小于等于P的概率。如果你还没理解的话,想一想F(x)曲线表示的是变量在x左侧的累积概率值。现在的x是P,而我们关注的变量是V,则F(P)表示的就是Pr (V≤P),即V≤P的概率。
(5)用累积分布函数计算顾客购买产品的概率
我们在本节刚开始时讨论过,只有在企业定价P低于顾客对产品的认知价值V(即P≤V)时,顾客才会购买。现在有了V≤P的概率,要想求Pr (P≤V),只要利用1-Pr(V≤P)=1-F(P)即可。因为P≥V和P≤V合起来的概率是1。
因此,顾客不考虑推荐激励机制,单纯考虑产品本身的购买概率是:
Pr(购买)=1-F(P)
2、顾客向他人推荐产品的概率
当产品的价格低于顾客的认知价值时,顾客会购买产品。如果产品超值,顾客有可能向他人推荐。企业还可以通过营销手段,激励顾客向他人推荐。下面先分析顾客向他人推荐的边界条件,再讨论企业激励顾客向他人推荐的条件,然后以此为基础,计算顾客向他人推荐的概率。
(1)顾客向他人推荐产品的边界条件
顾客购买某产品只能说明他觉得该产品“值”这个价格(即V-P≥0),但并不意味着他会向其他人推荐产品。只有觉得超值时,他才有可能向其他人推荐。超值或者源于产品本身的价值(即value),或者源于企业的定价(即price),两者之间的差值只有超过一定程度时,才算是超值。这个“一定程度”在原论文中被称作惊喜门槛(delight threshold,缩写为D)。那么,顾客向其他人推荐的条件就是V-P≥D。
(2)企业对顾客推荐行为的激励
企业为了鼓励顾客向他人推荐,通常会采用某种激励措施。激励措施的本质是提高V或者降低P。例如奢侈品是通过塑造品牌来提高V,其他企业可以通过促销来降低P。当然,也有既不直接改变V也不直接改变P,而给消费者的推荐行为提供补贴的。
为了把事情说清楚,我们仍旧保留V和P(对应于原始状态的产品认知价值和价格),而企业激励推荐的奖励用R表示。
我们对“推荐”的理解不要太僵化。“推荐”代表一类行为,包括给好评、分享感受、拍个视频等,实践中会有多种行为。例如,消费者去餐馆点了“剁椒鱼头”这道菜。如果僵化地理解“激励推荐”,就是服务员跟顾客说“你发条朋友圈信息说咱们店(或者这道菜)好,等会结账的时候给你打九折”。如果泛化地理解“激励推荐”,则“激励”可以包含各种行为。例如,服务员上菜以后,向剁椒鱼头倒上一两高度白酒,然后用打火机点着。顾客觉得很新奇,拍了短视频发到朋友圈分享。“倒上白酒并点火”就是一种激励行为,顾客发视频向朋友分享就是“推荐”。我们可以把企业付出的“一两白酒和服务员劳动”的成本,平摊到这一桌每个顾客身上,作为企业提供的人均激励R。
(3)潜在顾客看到推荐后的转化率
我们刚才是从企业的视角看待激励推荐。现在换个角度,看看接收到推荐信息的顾客行为。
我们还是用刚才“剁椒鱼头”的例子。服务员点火后,并不是所有的顾客都会拍视频分享。如果4个顾客中有2个拍了视频并分享,则人均分享率就是50%。依此类推,这4个顾客的朋友只有一定比例的人注意到了分享的内容。另外,他们即便看到了,仍可能由于口味、交通、时间等各种因素,也只有一部分人会来餐馆尝试一下这道菜。
我们把所有这些比例综合起来看待,用一个转化率α表示。其含义是企业设计一个点火活动(即激励推荐),最终转化成产出的比例。这里的产出可以是新顾客的数量、菜品的销售额或者餐馆的营业额。例如,有10桌一共40位顾客看到了点火表演,其中有20位顾客进行了分享,最终来了一个潜在顾客,则转化率为1/40。这里做详细解释是希望读者能理解转化率折射的现实和所代表的抽象概念。在理论模型中,我们不用思考那么多的细节,只需要知道有这个比例即可。
(4)有推荐激励时,顾客向他人推荐产品的边界条件
实践中,企业可能会采用多种形式激励顾客进行分享。我们不区分具体的方式,而是用前面提到的R来泛化代表各种激励及其成本。上面是按照人数计算推荐比例α。如果对应到一个顾客身上,则意味着单一顾客有α的概率会分享或推荐。因此,单一顾客得到的向他人推荐产品的激励是αR而不是R。
前面的分析涉及产品的认知价值(V)、产品价格(P)、顾客向他人推荐会得到的奖励(αR)、惊喜门槛(D)。顾客是否向他人推荐产品的边界条件的表达式如下所示:
V-P+αR≥D(5-6)
(5)有推荐激励时,顾客向他人推荐产品的概率
我们对式(5-6)做个简单变形,就得到了V≥D+P-αR。我们已经有了累积分布函数的表达式F(*)。CDF的数学定义是F(x)=Pr(variable≤x),F(*)代表所关注变量小于等于*时的累积概率,则F(D+P-αR)就是所关注变量小于等于D+P-αR的累积概率。只要用1减去这个概率,就得到了所关注变量大于D+P-αR的累积概率。我们关注的变量是认知价值V。那么,有推荐激励时,顾客向他人推荐产品概率就是:
Pr(推荐)=1-F(D+P-αR)
3、激励推荐对企业利润的影响
用激励推荐活动开始时的“顾客数量”乘以“推荐的概率Pr(推荐)”就得到了会有多少顾客向他人推荐企业或产品。这个数值再乘以转化率α就得到了“新顾客的数量”。
(1)顾客数量的标准化
在继续介绍后面内容之前,这里插入变量定义和数据处理的思路和方法,以便于理解他人的模型和说法。
理论模型经常把顾客的总数设定为1,最终的模型根本就不包含顾客数量这一项。这读起来很令人困惑。
假设有两个顾客群,一个有100位顾客,另一个有120位顾客。如果想找个量纲或量级简单表达人数,例如,用100作计数单位,则前一个顾客群的顾客数量为1个单位,而后一个顾客群为1.2个单位。如果直接用120作计数单位,则后一个顾客群也可以记为1个单位,只不过每单位有120人。你可以理解为部队中的1个连。
这个计数单位也可以是看起来更为奇怪的任何数,例如2 749这样的没有任何含义和特点的数字。如果用12作计数单位,似乎也挺奇怪,但这是西方用了很多年的一打的计量单位。我们说喝了1件啤酒或者1箱啤酒(24瓶),也是类似的逻辑。
机器学习领域经常会对数据做“标准化”或“归一化”处理。虽然方法不同,但核心思路类似。理解了这种思想,就容易明白为什么很多模型不包括顾客数量,而只是若干概率或者比例相乘。
(2)激励推荐活动获取的新顾客数量
把前面的讨论结果用公式表示出来,就得到了下面的表达式:

这些新顾客将来还按照同样的转化率α进行第二次推荐,第二次获取的新顾客(注意,仅仅是第二次获取的新顾客而不是最初的所有顾客)又按照同样的转化率α进行第三次推荐。只需要把这个过程持续下去,即可得到一次激励推荐活动能吸引到的新顾客的长期价值。省略中间的推导过程,企业因为激励推荐而获得的额外顾客数量是:
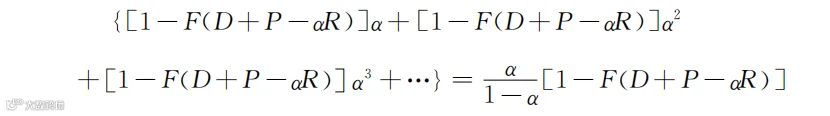
(3)考虑激励推荐投入后的企业总利润
如果每个顾客购买价格为P的产品,则企业扣除激励推荐的成本R之后的利润如下所示:
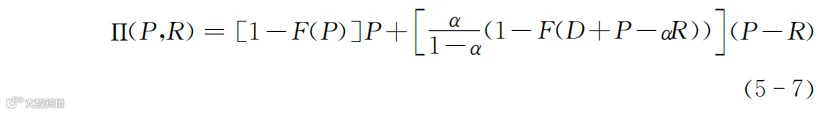
理论模型默认用Π或π表示企业获得的总利润。
在式(5-7)中,等号左侧(P,R)表示这个利润是考虑价格P和激励成本R得到的利润。
等号右侧第一部分P是顾客数量1乘以与激励推荐无关的购买概率,也就是会有多少顾客购买,再乘以产品价格,得到的是最初的那些顾客带给企业的收入。
等号右侧第二部分是中,是激励推荐活动所带来的购买产品的累积总人数(注意,公式中略掉了标准化以后的顾客数量1)。然后又用这个人数乘以企业获得的单位净收入(产品价格P减去了激励成本R)。两部分合在一起得到的是因为激励推荐活动而获得的净收益。
想必读者也注意到了,式(5-7)并没有扣除产品的成本,因此它其实是一个企业收入的表达式而不是利润的表达式。只不过我们的决策目标不是利润的绝对值,而是利润的最大化。在毛利率已知的情况下,收入和利润有确定的对应关系。
4、优化企业激励推荐的策略
明确了激励推荐对企业利润的影响后,剩下的工作就是找出使企业利润Π最大化的(P,R)组合。数学表达式为:
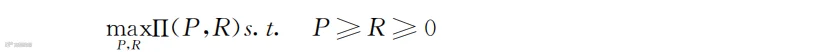
其含义是找出(P,R)组合构成的利润Π(P,R)的最大值,s.t.是subject to的缩写,表示服从后面的条件,条件是设计的定价P和激励成本R都大于等于0,而且激励推荐的投入要低于产品价格,否则企业会面临短期的损失。
(1)企业面临的三种情境和涉及的决策变量
我们在分析顾客决策的时候,区分了有、无企业激励推荐两种情况。对企业而言,也存在几种情境,企业需要比较不同情境的最优P、R策略。
情境A:不认为顾客会向他人推荐,单纯从企业自身的角度考虑如何设定价格P,从而使企业利润最大化。
情境B:认为顾客有可能向他人推荐,但企业不打算投入资源激励推荐,据此设定价格P使得企业利润最大化。
情境C:认为顾客有可能向他人推荐,企业为顾客推荐设置激励措施(实质是考虑激励推荐的成本),据此考虑如何设定价格P和激励成本R。
从式(5-7)能够看出,企业要决策的变量是价格P和激励成本R,除此之外,还涉及代表超值的惊喜门槛D、转化率α和代表产品认知价值的累积分布函数F()(对应有PDF)。实践中,D、α和F()都可以通过某个顾客群的实际数据拟合得到。我们只需要在式(5-7)中代入实际的D、α和F(),就可以计算A、B、C三种情境下的最优P和R的值。
(2)寻找使利润最大化的(P,R)组合
原论文作者用均匀分布的F()对三种情境的结果进行了比较。均匀分布的F()对应的概率密度函数画在图上就是一条横线(你可以据此有个形象的思考),其范围内的F()的数学表达式是
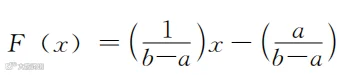
这是类似于“y=ax+b”的线性关系。如果要计算F(P),就把F(x)中的x替换成P,计算其他变量也类似。这样,式(5-7)在F()是均匀分布的情况下就变成了下面这样的:
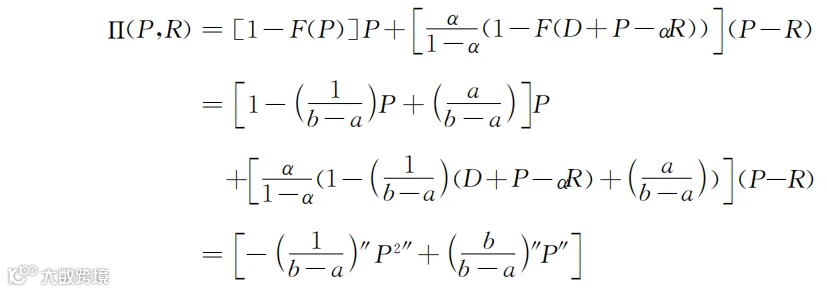
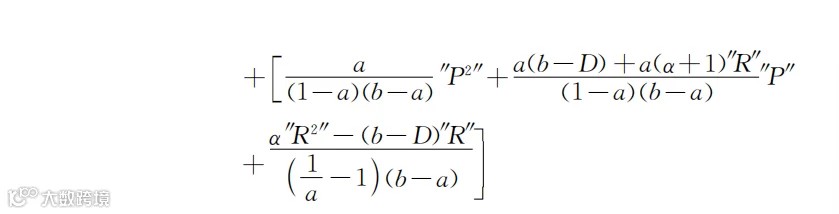
结果看起来很复杂,我们还用前面章节的方法,只看参数个数。如果只关注其中的P2和P,则上述公式最终能转化为:
Π(P,R)=β1P2+β2P+β3
如果只关注其中的R2和R,类似地,上述公式也能转化为:
Π(P,R)=β4R2+β5R+β6
不论原始公式多么复杂,当只看P2和P,或者只看R2和R时,我们都可以用βi来简化代表P2、P或R2、R前面的那些参数。
我们可以用最简单的y=x2来判断曲线的形状,当x=[0,1,2,3]时,y=[0,1,4,9],即曲线总体呈U形。只不过x=[0,1,2,3]时,y的取值是U形曲线的右半侧。如果加上x,即y=x2+x,虽然曲线的形状和位置的细节会发生变化,但曲线呈U形这一点没变。
当在x2前面增加参数β,即y=βx2时,β取值的正负会影响y对应的曲线是呈U形还是倒U形,但总体特征并不会改变。也就是说,参数只会改变曲线是“山峰”还是“山谷”,或者其倾斜情况,但总体特征是不变的。
只要是“山”的情况,总会有极值点(即利润Π(P)或Π(R)的最大值点)。我们可以借用图3-5中的立体图,如果纵坐标的高度代表利润Π的高低,优化任务就是找另外两条坐标轴(分别对应P和R)上能够使得Π(P,R)最大的P和R的位置(数值)。
更复杂的情况下,还可以认为推荐转化率α是随价格P变化的,即α=1-F(P)。或者认为α本身就是一个与顾客个体有关的变量,服从某种概率分布(例如前面提到的那几种)。这种情况下,计算最优Π(P,R)的公式形式会有所变化,但也只是变得更为复杂而已,实质结论并没有方向性的变化。本节的目标不是计算具体的公式,而是希望能说清楚公式背后的道理或者逻辑思路,这里就不对具体的数学表达详细展开了。
欢迎诸位企业家朋友随时与朗玛峰团队沟通交流