
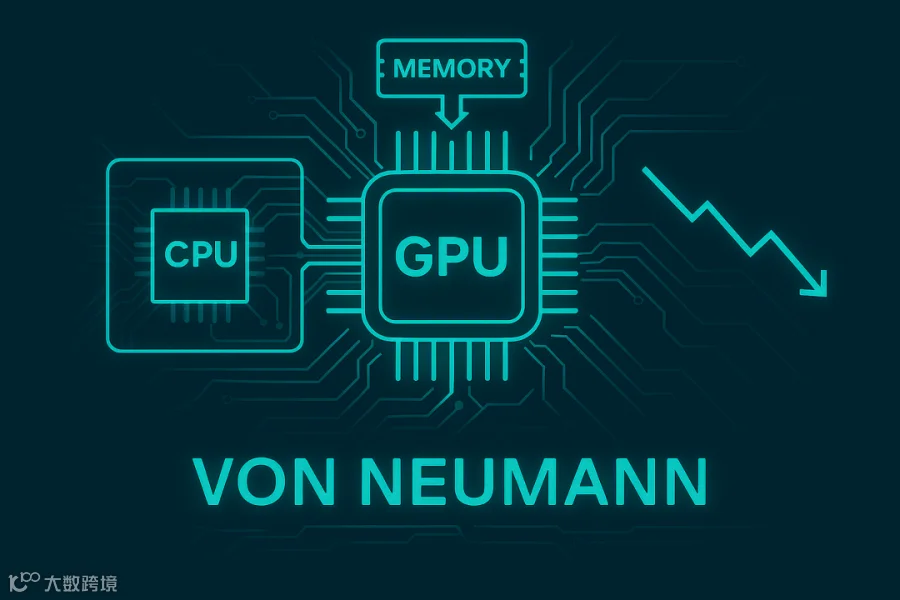
-
传统架构核心组成:CPU + 内存 + I/O设备 -
数据流路径:所有计算与数据传输都需经过 CPU 与内存 -
瓶颈本质:计算与存储分离,数据搬运成本高,带宽与延迟成为限制因素

-
Intel Gaudi与Falcon Shores也在推进GPU主导的AI加速架构 -
AMD MI300系列融合GPU与CPU于单一封装,强调统一内存访问与高带宽 -
Google TPU系列也采用非冯诺依曼架构,强调矩阵乘法加速器与高效内存访问 -
NVLink/NVSwitch 构建的 GPU 网络,本质上是“存算一体”的尝试,提升数据就近计算能力 -
最新的 Blackwell 架构支持数百个 GPU 芯片协同工作,构建“GPU为中心”的智算集群


坦白的讲,我们当然知道基于现有的底盘(通算)去打造一台车相对容易,并且可以快速的切入市场,并获得订单。然而:当你希望这台车足够的轻量化,足够的快速,企图超越当前最快的跑车?那么现有的通用型底盘会很快到达瓶颈,因为“通用”意味着符合普遍的适用性:载物载重,顾及家用成本,越野能力…其纵深的延展性极大的被限制而且很快会到达瓶颈。
我们深知产品的瓶颈会始终伴随企业的发展瓶颈。现在,鸿芯智算选择了一条更艰难的技术路线,即:摒弃厂商普遍采用的通用型架构,我们选择了去重塑一套新的架构,旨在打造符合客户需求的产品,以及构建持续的企业发展战略。

鸿芯智算科技有限公司-理念:基于AGC体系结构(AI computer system with the GPU at its Core),颠覆以往通算底座构建的智算体系、打造下一代创新型智算平台!
在该理念中强调是“Bypass”通算中的CPU、RAM,构建“以GPU为核心”的AGC智算体系,让GPU PCIe智算卡或智算芯片能够火力全开的发挥效能。新型的智算体系性能发挥不再依赖于CPU调度、内存的中转,类似您在MGP-820ls产品看到的那样,我们使用1颗CPU即可全速运行20颗通用型PCIe GPU而无需特殊改装,而在我们的AWS P4中,仅仅使用ASIC(专用集成电路)便可以全速运行4颗标准的PCIe GPUs智算卡。未来,我们会围绕这一技术理念持续深耕,尝试通过类似智能BMC技术,完全摒弃被沿用数十年的“冯诺·依曼”计算体系,试图打造更加纯粹的AGC智算体系。
值得一提的是,AGC技术理念并非是我们的终点,而更像是一艘航空母舰,或是下一代创新型智算无数创意实现的跳板。我们期望在AGC的航母上面构建各式各样的战斗机,轰炸机,预警机…AGC最终会成为鸿芯在智算体系结构中无数有效价值创意的创作平台。
促使一个企业保持持续的生命力关键的因素之一:便是有一个符合商业化,长久战略的公司理念。该理念在内部是创始团队走到一起,凝聚力的核心源泉,对外则是“辐射”生态和伙伴,获得更多共识的触手。这也是缔造一个科技企业的原始动力。
在此,期望更多的有识之士能够加入我们的生态,在技术路线和智算体系发展的理念上获得更多共识!

鸿芯智算(深圳)科技有限公司,专注于全信创鸿芯智算大模型一体机、HX-IPU数据加速单元/分布式存储、HX-DataCore超融合/双活/全闪存存储、云桌面/云终端、等自主可控系列硬件产品及企业数智化转型晓软AI+软件产品的集成、研发、运维、咨询服务。
公司以“硬件+软件”双轮驱动为核心战略,在我们的晓软工研院核心研发基地,汇聚了一批充满激情的硬件研发团队,在存储系统研发,电子电路设计,AI与智算领域有超过15+年研发经验,上线的产品已经过多年的市场打磨,并承载诸多企业客户的核心业务系统。公司同时拥有强大软件研发团队,专注于为企业提供前沿的智能化解决方案,服务涵盖数智化工厂建设、智能智造系统集成研发、工业数据分析和人工智能应用等方面,致力于人工智能、数字智造深度创新和落地。
