
随着大数据分析、AI计算等应用对算力需求巨大,在分布式系统中,大模型训练对算力基础设施的要求从单卡拓展到了集群层面,这对大规模卡间互联的兼容性、传输效率、时延等指标提出了更高的要求。
传统:GPU-CPU直连架构
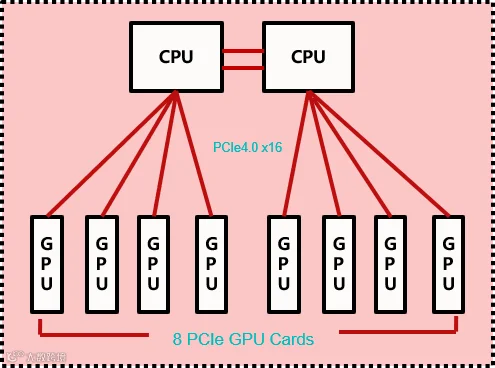
Ø传统架构核心组成:CPU + 内存+ I/O设备
Ø数据流路径:所有计算与数据传输都需经过CPU与内存
Ø瓶颈本质:计算与存储分离,数据搬运成本高,带宽与延迟成为限制因素
ØGPU的优势:高并行度、强算力,适用于AI训练与推理
Ø但GPU无法独立调度任务需依赖CPU发起指令,参数与数据需通过内存中转,增加延迟与资源占用
ØPCIe作为连接通道,带宽远低于GPU内部算力需求,形成“算力孤岛”
Ø算力无法线性叠加:GPU算力虽强,但受限于CPU调度与内存中转,整体性能提升受阻
ØPCIe带宽滞后:GPU与CPU之间的数据传输受限于PCIe速率,即使GPU性能翻倍,带宽不足也无法充分发挥其潜力
Ø资源浪费与能效下降:大量GPU资源处于等待状态,整体系统效率低下
鸿芯智算:创新GPU互联架构
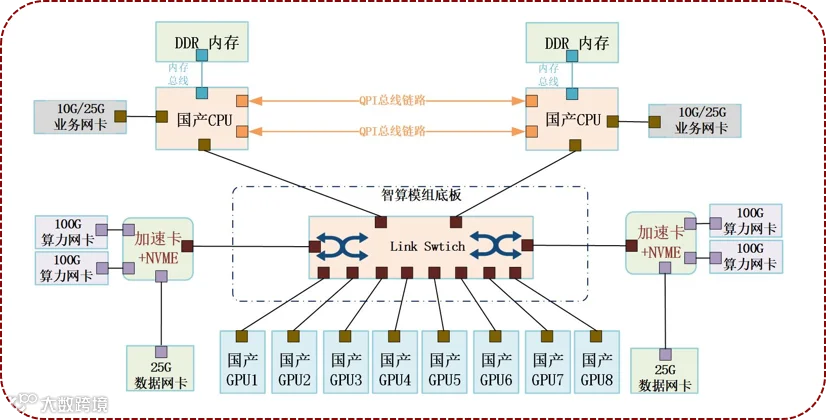
◆通过加速卡+NVME构建独立的分布式数据加速平台,不占用CPU资源,满足数据/模型快速加载、交互;通过高带宽的互联协议供GPU近线使用。
◆卡间速率达到500GB/s,节点间速率达到400Gbps。
◆模组可以实现不同品牌、型号GPU卡的混插,内置驱动与主流GPU卡适配实现拉通国产GPU生态目的。
◆通过鸿芯智算自研XR-AIOS枢纽平台可按照业务或任务需要进行卡级资源调度,还可以调度异构GPU卡进行混卡推理和混卡训练,提高智算资源的使用效率的同时,降低了使用难度。
鸿芯智算:关键组件
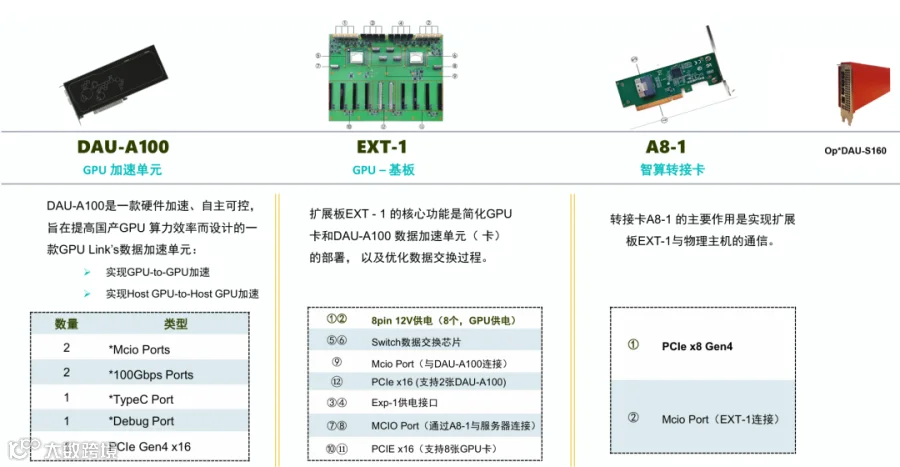
P系列:HCP-48 8颗GPU卡
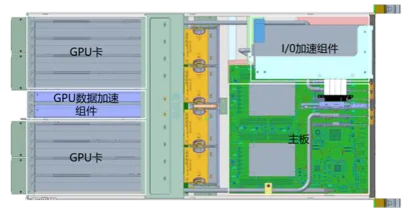
AGC系列:AGC64F 64颗GPU芯片
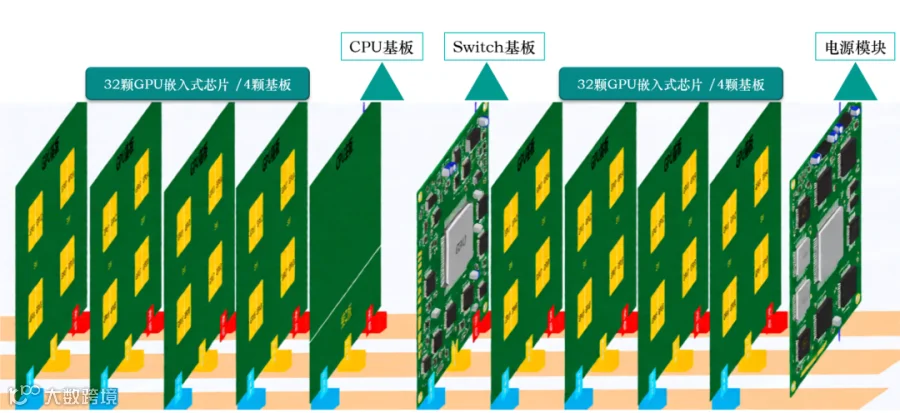
提供丰富的模块化“通算单元”可选项

鸿芯智算-创新型GPU算力单元的设计理念:
在为大规模智算集群设计高性能节点之初,鸿芯智算的专家团队不仅考虑了极致的算力密度,极高的AI能效,极简的交付部署特点等因素,还包括长久以来吸收的项目交付经验,客户在智算场景许多痛点的共识,我们特别遵循了以下的设计考量:
◆自主可控,规避有可能出现的任何IP产权的争议,战略性的保持产品持续迭代的稳定性
ØARM架构?AMDIP传承分支?NOWay!
Ø确保GPU与基础平台的知识产权的绝对无争议。
◆数据流动带宽必须符合当前最先进互联技术
Ø卡与卡(GPU)间的数据流动,必须突破PCIe限制。
ØGPU节点间的数据流动,需要规避CPUtoRAM开销,做到物理卸载,P2P则是优先值得考虑的优势。
◆积极的为智算信创生态贡献力量,整合异构GPU算力池,并使其相容
Ø通过有效的技术手段,促使各厂商的GPU能够在相容的模式提供算力服务。之后,通过统一的框架适配广泛的模型。
◆避免硬件厂商对单一品牌的绑定,充分保护客户的投资,确保智算平台提供广泛的GPU兼容性
◆调度的灵活性与丰富的策略,任务处理与GPU之间可支持“一对一”、“一对多”
◆提供一站式交付平台:
Ø开箱即用,定位于打造AI领域的搜索引擎,构建算力+模型+数据的运营闭环的智算公共服务平台。涵盖AI开发全流程,包含数据集、模型开发、训练、管理、部署功能,可灵活使用其中一个或多个功能。
Ø平台内置多种预置模型,提供优质开源数据和精准模型索引,支持按照用户需求选择最优资源,简单操作快速训练出自己的模型。
Ø使GPU模块能够在满负荷与休眠状态下自适应运行,具备先进的唤醒机制。
Ø整机最小化电力消耗可达几百瓦,有效的降低智算运营的电力投入。
Ø同时,间接降低冷却系统投入。更大的延长GPU使用周期。
◆GPU-RAID 高可用:提升业务连续性
◆GPU热插拔:提升运维连续性
◆GPU异构融合:提升灵活性
◆Bluelink高速互联:提升传输效能
鸿芯智算-行业认可:
◆工信部一所测试:
核心性能符合信创要求,可提升信创服务器性能10倍左右,满足高并发应用在信创设备运 行的需求。
◆电信集团研究院:
XR-AIOS枢纽平台可进行异构卡级调度,可对国产GPU卡间互联加速,提升GPU推理速度 44.87%,图像生成速度提升41.2%,卡间互联速率561.5GB/s,节点间互联速率400Gb/s。部署效率提升,属国内首创。
◆中移动苏州研究院:
读写带宽性能平均提升3倍,IOPS性能平均提升14倍,实现完全卸载计算节点CPU和内 存资源,大大增加
部署业务所需的可用计算资源量,并且在ARM主机计算节点环境下,支持创建X86架构资源的能力。对信
创服务器加速效果明显,具有良好的信创适配,功能和安全性均符合要求。
◆浪潮测试:
使用Llama2-70B-instruct和百川2-13B-Chat两个模型测试,国产GPU卡有效算力提升40%,使国产GPU卡有效算力发挥达到80%,卡间每秒生成token数80个,整机每秒生产token数1000-2000个,高于浪潮测试的其他国产设备,满足智算平台建设需要,且明确产品具有4项明显优势:1、单服务器异构算力 融合;2、信创服务器GPU免驱动管理;3、单一模型异构算力混合推理;4、GPU算力网与业务网隔离管理。


更多详情: