


01
重大发布(新模型/产品/开源)
①美团发布EvoCUA:开源计算机操作模型位列OSWorld第4名
美团近日于GitHub和Hugging Face上开源了全新的多模态大模型EvoCUA,并选择OSWorld作为评测标准。OSWorld是一个用于评估多模态智能体在真实计算机操作系统中执行任务能力的基准测试,模型需要能够像人类一样通过观看屏幕、控制键鼠等操作完成复杂任务。
经测试,EvoCUA的任务完成率为56.7%,位列开源模型第1,总榜第4,超越了香港大学和月之暗面研发的OpenCUA-72B(+11.7%)和阿里研发的Qwen3-VL-Thinking(+15.1%)。
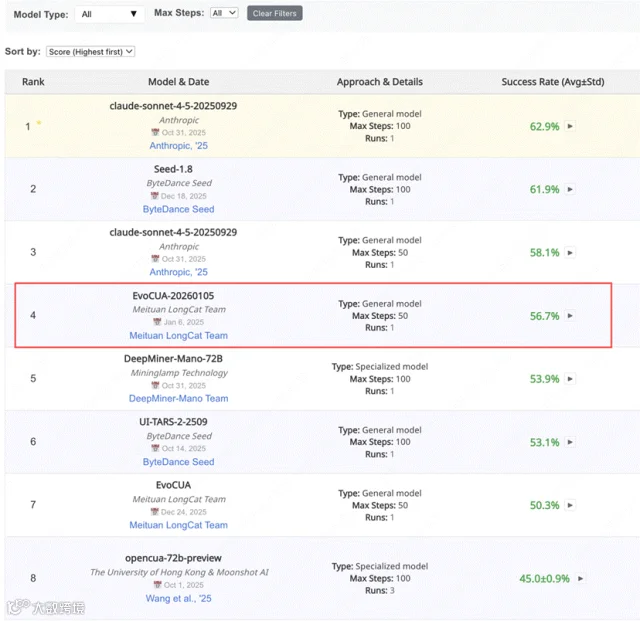
该模型仅需50步即可实现较高性能表现,且所用参数量更少、任务执行效率更高。在适用场景上,该模型支持端到端自动化操作,仅凭屏幕截图+自然语言指令即可流畅操控常用软件,如Chrome、Excel、PPT和VSCode等主流软件,进而完成多轮复杂任务。
根据项目介绍,该模型的创新点在于独特的数据合成与训练范式,在保持通用多模态理解力的基础之上强化了计算机使用能力。
短评:
这个模型的本质就是Manus,说是模型,请倾向于多智能体应用。
EvoCUA在参数更少、步数减半的情况下实现性能的显著提升证明其训练方法是有效的,这是开源模型在自动化操作方向上前进的重要一步。
不过,56.7%的任务完成率仍然局限于“实验室中的好用”,而非“用户手里的好用”。
值得肯定的是,EvoCUA与占据榜单前三的Anthropic的claude-sonnet-4.5和字节跳动的Seed-1.8得分差距只在毫厘之间,尽管无法掌握场景定义,但也可以抢占一部分开源生态中“计算机使用”场景的话语权。
美团未必指望EvoCUA短期内的商用,但该模型的开源能够提升技术影响力,同时为集团内部的办公、运维等流程实现优化,一举两得。
②Anthropic推出Claude for Healthcare,布局AI医疗行业
随着OpenAI和阿里接连推出AI医疗领域相关产品,Anthropic也紧随其后开始进行布局。1月12日,Anthropic正式推出Claude for Healthcare,并同步扩展Claude for Life Sciences的能力,AI医疗场景再添一巨头。
Claude for Healthcare的客户群体分为三类:医疗机构、保险公司和患者,并提供HIPAA合规的AI套件,核心包括以下三点:
一是直连三大官方数据库:CMS覆盖政策库、ICD-10编码系统、国家医疗服务提供者标识符注册库,支持医保预授权审核、理赔申诉、编码校验等高价值任务;
二是新增Agent技能:FHIR(医疗信息交换国际标准)开发支持(提升医疗系统互操作性)、预授权审查模板(可定制化对接机构流程);
三是个人健康数据整合:用户可授权接入Apple Health、Android Health Connect、实验室检测报告等数据源,Claude可生成简明解读、识别健康趋势,并协助准备问诊问题。所有数据均不会用于模型训练,用户全程具有控制权。
Claude 新增了对Medidata(临床试验平台)、ClinicalTrials.gov、ChEMBL(药物数据库)、Open Targets、Owkin(病理图像分析)等关键平台的连接,并推出临床试验方案自动生成、监管文件辅助撰写、试验进度监控等新技能。
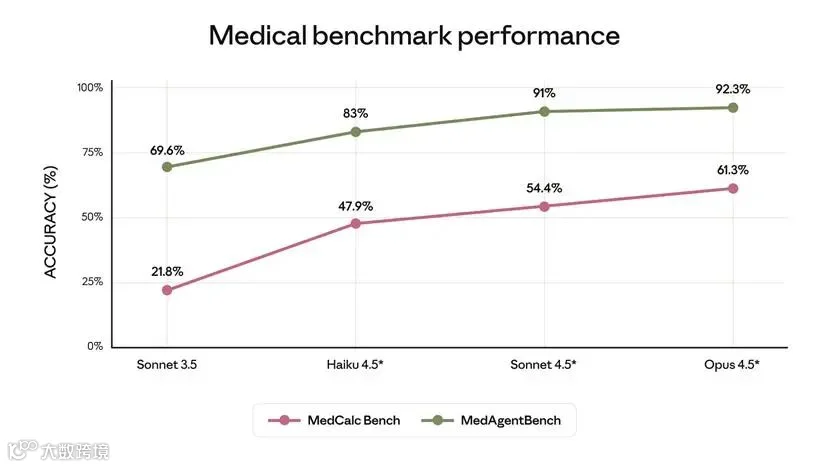
根据测试结果,Anthropic最新的产品 Claude Opus 4.5 在 MedAgentBench(斯坦福医疗智能体评测)和 MedCalc(医学计算)等仿真任务中显著领先,同时在“事实诚实性”评估中有效减少了幻觉,更贴近临床可靠性要求。
短评:
OpenAI、Anthropic和阿里短期内同时将目光放到AI医疗上,说明AI应用的落地场景正在逐步明确。先是AI编程,后是AI医疗,从Chatbot到Agent的应用范式已经成功转移。
相比先前推出AI医疗产品的OpenAI,Anthropic涉足的领域要更加深入,切入了多个高价值的工作流,但落地仍然高度依赖机构IT系统集成,同时也面临着责任边界模糊等问题,风险不容小觑。
02
①Google新发现:重复输入提示词即可提升主流LLMs准确率
近日Google Research发表了一篇名为《Prompt Repetition Improves Non-Reasoning LLMs》的论文,篇幅虽然不长,却揭示了一个出乎意料的现象:
只要将用户输入的提示词(prompt)重复一次,就能在不启用推理、不增加生成长度、不延长响应时间的前提下显著提升大模型在多项任务中的表现。
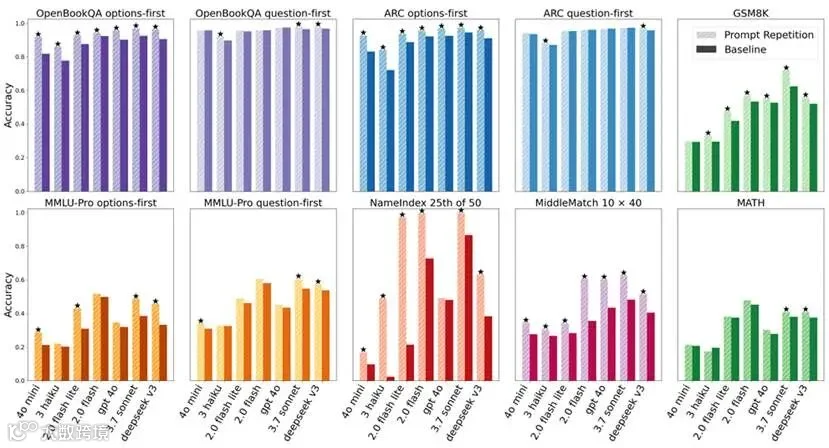
研究团队将这一方法应用在Gemini 2.0 Flash、Gemini 2.0 Flash Lite、GPT-4o-mini、GPT-4o、Claude 3 Haiku、Claude 3.7 Sonnet、Deepseek-V3共7款主流模型上进行了测试,覆盖了7项基准测试。结果显示:
1.在70组实验中,重复输入提示词在47组测试中为模型带来了正向提升,且并未导致性能下降;
2.在NameIndex等特定结构的任务中,准确率从21%跃升至97%;
3.对于“选项前置”或“问题后置”的不利结构,效果会更加明显。
研究团队认为,这一现象源自于模型在预填充(prefill)阶段对上下文注意力的重新分配。重复输入提示词可以让模型在token处理的早期阶段获得更强的语义锚定,从而减少因位置偏移导致的理解偏差。而当模型被要求“逐步推理”时,内部已经隐式完成类似的信息强化,因此重复提示的效果将趋于中性。
简单来说,大模型在生成答案前的准备阶段只能从左到右看一遍输入,不能回头。如果问题和关键信息离得太远,就可能导致“记不住”或者“理解错误”等问题。重复输入提示词可以让大模型多看一遍题目,所有词之间也能通过注意力机制“看到”彼此,从而减少词序问题导致的误判。不过,当模型被要求“一步一步思考”时,用户就可以在“思考部分”中看到大模型复述和整理问题的过程,手动重复提示也就用处不大了。
短评:
当前的大模型对于提示词的输入顺序依然高度敏感。这一简单但高效的技巧巧妙地绕过了模型架构的天然缺陷,将输入转变为全连接的语义网络,人工修复了信息流的不对称性,从向量的空间视角来看十分合理。或许,不是没人想过“多说一遍”,只是没人把它当作一个通用、可量化的技术手段来验证。
不过,需要注意的是,该论文测试的模型如今看来已经略显过时,该技术能否在当下最先进的模型上发挥作用有待考察。
03
算力与基础设施(芯片/云/数据中心)
①Google紧急下架部分医疗类AI Overviews
近日,英国《卫报》在一项调查中发现,Google的AI Overviews(基于Gemini大模型生成结构化答案的功能)在肝功能检测等健康查询功能中提供了缺少个体化参考范围的误导性数据。目前,谷歌已经悄然移除相关关键词的AI摘要功能。
根据《卫报》的测试结果,当用户搜索肝功能检查的正常范围时,AI Overviews给出的数值是一个固定区间,但并未提示该范围可能会因为年龄、性别、种族甚至检测设备的差异而发生显著变化。这种“一刀切”的回答可能导致患者误判自身情况。
目前,有关“肝功能查询”及类似的表述已经不再触发AI摘要,仅显示相关搜索结果。谷歌随后对此做出了回应:其内部临床团队在复核后认为该功能提供的“多数信息并非错误,且有高质量网站支持”,表示会持续进行改进,但拒绝对下线该功能的行为进行评论。英国肝脏信托基金会表示:临时关闭个别查询只是“治标不治本”,AI Overviews在医疗领域面对的问题仍然未能解决。
短评:
在缺乏严格的医学知识图谱、临床审核流程和强大推理能力的前提下,将通用大模型直接用于健康信息的分发仍然存在重大的安全隐患。
Google的AI Overviews在2024年就给出过“用胶水往披萨上粘芝士”、“吃石头补充营养”等幻觉度极高的离谱答案,如今随着Google的影响力与日俱增,以“权威摘要”形式输出健康建议所带来的风险也在激增。反观OpenAI选择聚焦日常健康陪伴而非诊疗场景,现阶段AI医疗首先要做到的不是专业,而是避险。
请添加微信:cutstill
添加微信请备注姓名公司与来意