

01
重大发布(新模型/产品/开源)
① 智谱GLM-Image接入Hugging Face,多模态生态迈出关键一步
14小时前,智谱AI向Hugging Face Transformers主仓库提交了一项重要更新,为其多模态模型GLM-Image加入完整自回归支持。

此次更新并非简单接口封装,而是新增超过5100行代码,标志着在上市前夕,智谱将其多模态能力正式集成至全球主流的AI开发框架。
此举大幅降低了开发者的使用门槛——无需额外修改代码或配置环境,即可沿用类似Llama的调用方式,一键加载并运行这一中文多模态模型。
短评:
继GLM-4.7登陆英伟达API平台后,GLM-Image再度融入全球开源生态,实现“开箱即用”。这不仅意味着智谱在模型可用性上取得突破,更象征着中国AI模型正式获得全球开发社区的“通行证”。多模态与纯文本模型并行推进,正逐步构建起更为完整的产品矩阵,其实际效能值得持续关注。
② MiroMind开源研究智能体MiroThinker v1.5:交互优先,规模让位于效用
MiroMind团队着眼于通用人工智能(AGI),但其路径独树一帜:专注于“预测型大模型”,依托记忆驱动机制,实现动态场景下的复杂决策。MiroThinker定位为可联网、检索、编码与思考的“AI研究员”,与普通聊天机器人形成鲜明区别。
本次开源提供30B与235B两个版本:
30B模型在中文网页理解测试BrowseComp-ZH中,以1/30的成本超越1T参数的Kimi-K2-Thinking;
235B版本则在多项基准测试中刷新开源模型SOTA,支持256K上下文与400次工具调用,擅长长文档分析与多步任务处理。
此次发布同时提出“交互扩展”理念——不单纯追求参数规模或上下文长度,而是强化模型在任务执行中与工具、环境的高频深度交互,如自动调用搜索、编程、文件操作等功能。
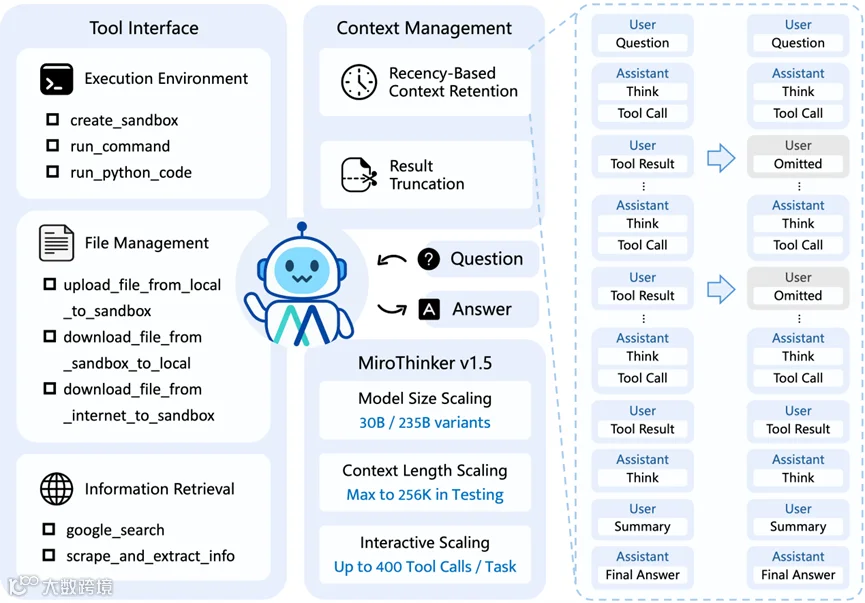
短评:
MiroMind以“研究员”模型开辟差异赛道,既回应实际科研需求,亦避免与已趋同质化的国产模型正面竞争。尽管在知名度与生态建设上尚不及头部厂商,但其“交互扩展”思路与高度工具化的设计,已展现出清晰的技术特色与商业化潜能。
02
政策变化(监管/安全/标准/政策)
① 腾讯元宝“辱骂回复”事件:概率黑洞与对齐机制的失效
近日,小红书上一则关于腾讯元宝的对话引发热议:一名程序员用户在反复提交代码修改请求后,竟收到模型带有辱骂性质的回复。尽管原帖已无法查看,事件却揭示出大语言模型在安全对齐上的深层隐患。

从技术角度看,此类输出并非“AI觉醒”或人为干预,而是大语言模型作为概率生成器的固有风险。在极端上下文触发下,模型可能从训练数据中复现包含攻击性语言的模式——尤其是当训练语料混杂社交媒体争吵、投诉等场景时,即便概率极低,仍可能不幸命中。
该事件同时暴露出现有对齐技术的局限性:
监督微调(SFT):依赖人工标注,覆盖场景有限;
人类反馈强化学习(RLHF):能捕捉细致偏好,但易受评分者主观影响;
后处理过滤:作为最后防线,却可能被巧妙绕过,并增加响应延迟。
短评:
数据污染与对齐机制的不完备,共同让极小概率事件成为现实。这也提醒业界:在追求模型能力突破的同时,必须同步构筑更为稳健的伦理与安全护栏。未来除了加强生成内容的监管,还需在技术层面引入任务类型识别、对抗测试等机制,从根源约束概率的“越界”。
03
算力与基础设施(芯片/云/数据中心)
① 显卡涨价潮来袭:内存供需失衡,AI硬件成本攀升
据行业报告,英伟达与AMD预计自2026年第一季度起分阶段上调消费级显卡价格。此番波动根源在于AI爆发导致显存供需严重失衡——算力增长已显著超越存储技术演进,使得高带宽内存成为瓶颈。
目前GDDR6/GDDR7需求激增,价格数月内翻倍,导致显存在显卡物料成本中占比超80%。以RTX 5090为例,其美国售价已从首发1999美元攀升至接近4000美元。
短评:
AI硬件竞争焦点已从纯算力转向“内存带宽”。然而高端存储技术仍由少数巨头垄断,短期难有结构改变。在此背景下,中端显卡产能收缩,而部分轻量化开源模型凭借更低硬件需求(如RTX 4090即可运行),或将在成本敏感场景中赢得空间。
② 谷歌TPU专利五年增长2.7倍:全栈生态的厚积薄发
2018至2023年间,谷歌TPU相关专利数量增长2.7倍,2023年申请量近400项。相比之下,亚马逊、苹果、微软同期相关专利总数均不及谷歌单年数量,印证AI芯片市场正由通用GPU向定制化ASIC转移。
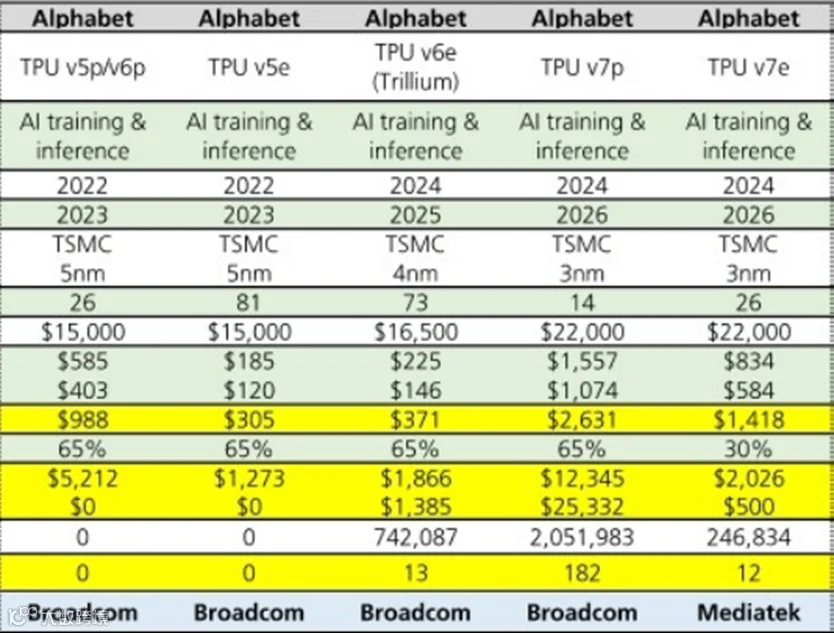
TPU凭借能效优势,已成为云服务商自研芯片首选,预计2026年出货增长率将超40%。另有消息称Meta正与谷歌洽谈百亿级投资,计划于2027年大规模部署TPU构建数据中心。
短评:
从算力层(TPU)到模型层(Gemini等),谷歌已构建软硬件深度协同的全栈优势。这种从底层基础设施到上层模型能力的全方位布局,使其稳坐AI金字塔顶端。即便在智能体等应用层尚未完全铺开,其深厚的技术储备与生态控制力,已为未来竞争埋下确定性的注脚。
请添加微信:cutstill
添加微信请备注姓名公司与来意