


我一直听到人工智能(AI)是个烧钱的行业,尤其是在推理(inference)方面。虽然表面上看起来合理,但我对这类说法一直持怀疑态度,因此决定深入研究一下。
目前还没有人真正尝试拆解大规模推理的成本,而这背后的经济问题让我非常感兴趣。
这篇文章是基于粗略估算(napkin math)完成的。我没有运行前沿模型的经验,但对在云端运行高吞吐量服务的成本和经济性有深入了解,也知道超大规模云服务商与裸机(bare metal)相比的惊人利润率。欢迎指正我的错误。
01
一些假设
我将仅考虑原始计算成本。这显然是过于简化的,但考虑到当前模型的实用性——即使假设没有进一步改进——我想测试“推理成本高到完全不可持续”这一观点是否站得住脚。
我假设单个H100 GPU的成本为每小时2美元。这实际上高于当前按需租赁的零售价格,我希望大型AI公司能以更低的价格获取这些资源。
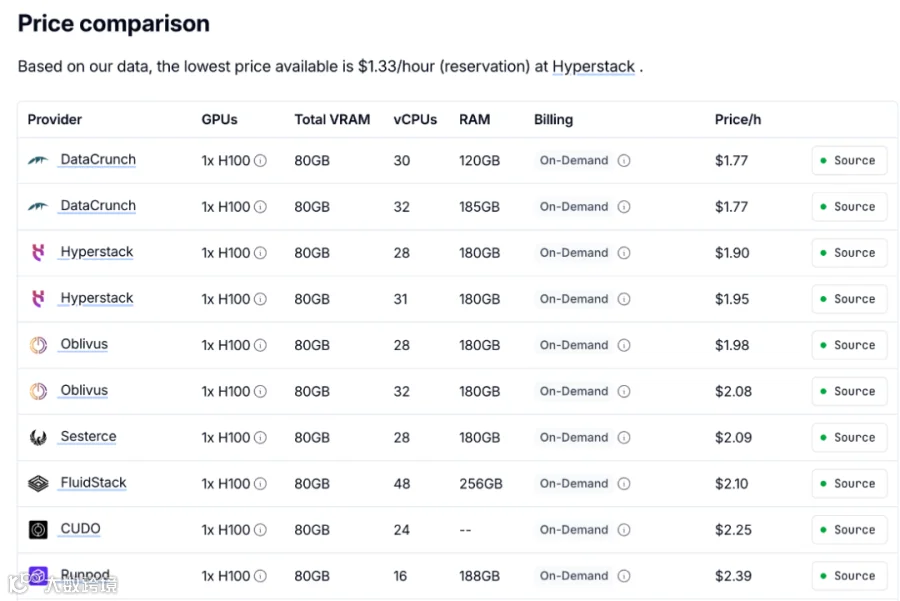
H100租赁价格比较
其次,我将以DeepSeek R1的架构作为基准:总计6710亿参数,通过专家混合(MoE)激活370亿参数。考虑到其性能与Claude Sonnet 4和GPT-5相当,我认为这是一个合理的假设。
02
从第一性原理推导:H100的计算成本
生产环境设置
让我们从一个现实的生产环境开始。假设一个包含72个H100 GPU的集群,每个GPU每小时2美元,总成本为每小时144美元。
为了满足生产环境的延迟要求,我假设每个模型实例的批量大小为32个并发请求,这比基准测试中可能使用的大批量更现实。通过在8个GPU上进行张量并行(tensor parallelism),我们可以在72个GPU上同时运行9个模型实例。
预填充阶段(输入处理)
H100的HBM内存带宽约为每GPU 3.35TB/s,这是大多数工作负载的限制因素。对于370亿活跃参数,在FP16精度下需要74GB内存,我们可以计算出每秒大约能处理3,350GB/s ÷ 74GB = 45次前向传播(forward passes)。
关键点在于:每次前向传播会同时处理所有序列中的所有token。
假设我们的32个序列批次平均每个序列包含1000个token,即每次前向传播处理32,000个token。这意味着每个实例每秒可处理45次传播 × 32,000token = 144万个输入token。在9个实例上,这相当于每秒1300万个输入token,或每小时468亿个输入token。
在MoE架构中,批次中不同token可能需要加载不同的专家组合,这可能导致吞吐量降低2-3倍,尤其当token路由到不同专家时。然而,实际中路由模式通常会集中在热门专家上,且现代实现使用专家并行(expert parallelism)和容量因子(capacity factors)等技术来保持效率,因此实际影响可能仅为30-50%的吞吐量降低,而非最坏情况。
解码阶段(输出生成)
输出生成的场景完全不同。这里我们是按顺序生成token——每次前向传播每个序列生成一个token。因此,45次前向传播每秒仅生成45 × 32 = 1,440个输出token。9个实例总计每秒12,960个输出token,或每小时4670万个输出token。
每token的原始成本
输入和输出的成本差异非常明显:144美元 ÷ 468亿 = 每百万输入token0.003美元,而144美元 ÷ 4670万 = 每百万输出token3.08美元。这是一个千倍的差距!
当计算成为瓶颈
我们的计算假设内存带宽是限制因素,这在典型工作负载中是正确的。但在某些场景下,计算能力会成为瓶颈。对于长上下文序列,注意力机制的计算量随序列长度呈平方增长。大批量大小和更多并行注意力头也可能使系统从内存受限转为计算受限。
当上下文长度达到128k以上时,注意力矩阵变得非常庞大,系统从内存受限转为计算受限。这可能使成本增加2-10倍,尤其是在超长上下文场景下。
这解释了一些有趣的产品决策。例如,Claude Code将上下文限制在200ktoken,不仅是为了性能,也是为了保持在成本较低的内存受限模式,避免昂贵的计算受限长上下文场景。
这也是为什么服务商对200k+上下文窗口额外收费——经济模型发生了根本变化。
03
现实世界的用户经济
根据我对成本的逆向推算(再次提醒,这是基于H100的零售租赁价格),我推测情况如下:
- 输入处理
几乎免费(约每百万token0.001美元)
- 输出生成
有显著成本(约每百万token3美元)
这些成本与DeepInfra对R1托管的收费相符,只是输入token的加价更高。
DeepInfra R1定价,见下图:
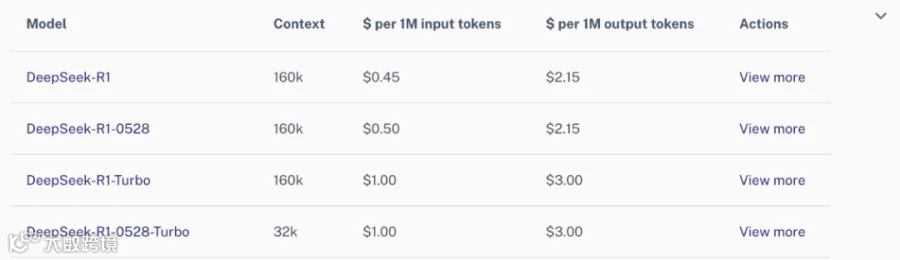
A. 消费者计划
ChatGPT Pro用户(每月20美元):重度日常使用,但受token限制
-
每天10万token -
假设70%输入/30%输出:实际成本约每月3美元 -
OpenAI的加价为5-6倍
这是典型的重度用户,每天使用模型进行写作、编码和常规查询。这里的经济性很强。
B. 开发者使用
Claude Code Max 5用户(每月100美元):每天2小时重度编码
-
约200万输入token,3万输出token/天 -
大量输入token(便宜的并行处理)+少量输出 -
实际成本:约每月4.92美元 → 20.3倍加价
Claude Code Max 10用户(每月200美元):每天6小时极重度使用
-
约1000万输入token,10万输出token/天 -
大量输入token,但生成token相对较少 -
实际成本:约每月16.89美元 → 11.8倍加价
开发者用例的经济性尤为突出。像Claude Code这样的编码助手天然具有高度不对称的使用模式——输入整个代码库、文档、堆栈跟踪、多个文件和广泛上下文(廉价输入token),但只需要相对较小的输出,如代码片段或解释。这完美契合了输入几乎免费而输出昂贵的成本结构。
C. API利润率
-
当前API定价:每百万token3美元/15美元 vs 实际成本约0.01美元/3美元 -
毛利率:80-95%+
API业务几乎是印钞机。这里的毛利率更像是软件而非基础设施。
04
结论
我们的分析基于许多假设,有些可能不准确。
但即使假设我们高估了3倍,经济性仍然看起来非常有利可图。即使按H100的零售价格计算,原始计算成本表明,AI推理并非许多人宣称的不可持续的烧钱坑。
最关键的洞察是,输入处理的成本比输出生成低得多——大约千倍的差距:输入token约每百万0.005美元,而输出token超过每百万3美元。
这种成本不对称解释了为什么某些用应用其有利可图,而其他应用可能面临挑战:
重度阅读类应用——消耗大量上下文但生成少量输出的场景——几乎在计算成本上处于免费层。像对话代理、处理整个代码库的编码助手、文档分析工具和研究应用都极大地受益于这种动态。
视频生成则完全相反——一个视频模型可能只输入50个token的简单文本提示,但需要生成数百万token来表示每个帧。当从极少输入生成大量输出时,经济性变得非常苛刻,这解释了为什么视频生成仍然昂贵,服务商要么收取高价,要么严格限制使用。
“AI成本不可持续”的说法可能更多服务于现有大公司的利益,而非反映经济现实。当行业巨头强调巨额成本和技术复杂性时,会阻碍竞争和对替代方案的投资。但如果我们的计算哪怕有一点准确,尤其是在输入密集型工作负载上,盈利性AI推理的门槛可能远低于普遍认为的水平。
让我们不要过分夸大成本,以至于人们忽视了原始经济性。十多年前,大家对超大规模云服务商的云计算成本信以为真,让它们变成了印钞机。如果我们“不小心”,AI推理可能会重蹈覆辙。(作者:Martin Alderson)
请添加微信:cutstill
添加微信请备注姓名公司与来意




