


01
重大发布(新模型/产品/开源)
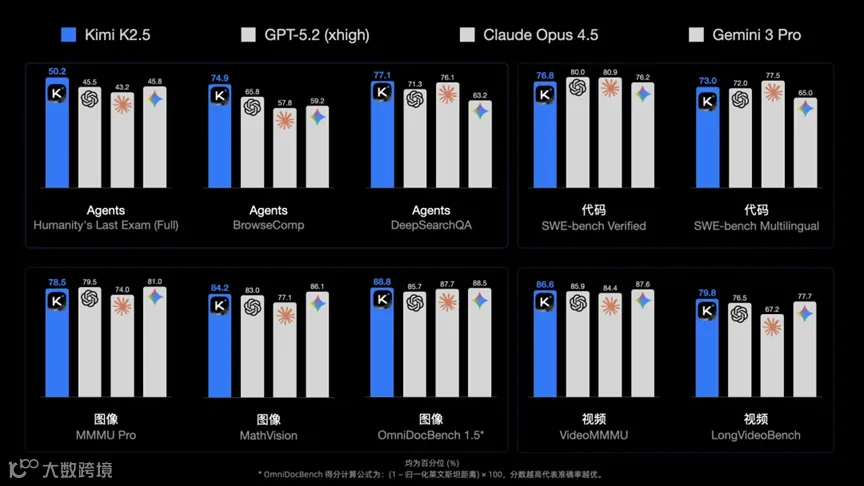
① 月之暗面开源Kimi K2.5,集成视觉、代码与多智能体集群能力
月之暗面于今日正式发布并全面开源 Kimi K2.5 模型。此次更新此前已在官网悄然上线,用户通过特定提示词可调用体验,现已发布官方公告。同步推出的还有基于Python构建的专用编程智能体 Kimi Code。
能力升级
原生多模态理解:模型采用统一架构,可同时接收文本与图像输入,进行深度的视觉理解与上下文推理,显著降低了跨模态交互门槛。
办公自动化增强:针对实用性进行优化,模型已掌握对Word、Excel、PPT及PDF等主流办公软件的中高阶操作技能,能依据自然语言指令生成格式规范、内容完整的文档。
智能体集群协作:本次最核心的突破在于引入了“Agent集群”机制。在执行复杂任务时,模型可自主创建多个功能各异的智能体角色,通过模拟人类团队的分工与协作方式并行处理子任务。团队称,该机制能将复杂任务的处理效率提升10-100倍。
月之暗面宣布,Kimi K2.5的模型权重及相关工具链已全部开源,支持研究者和开发者在本地或云端进行部署与推理,旨在推动前沿AI技术的普及。
短评
Kimi K2.5的多模态能力目前聚焦于视觉理解与分析,与国内已支持图像生成、编辑的同类模型相比,其生成式视觉及音视频处理能力仍是生态短板。然而,在特定视觉任务上的深度优化形成了差异化优势。
智能体集群协作已成为主流方向,但真正的挑战在于如何让Agent能力无缝融入用户的数字工作流,而非局限于独立的API或网页应用。Kimi K2.5需向操作系统与生产力工具的深度集成迈进,才能实现“随时随地”的智能体体验。
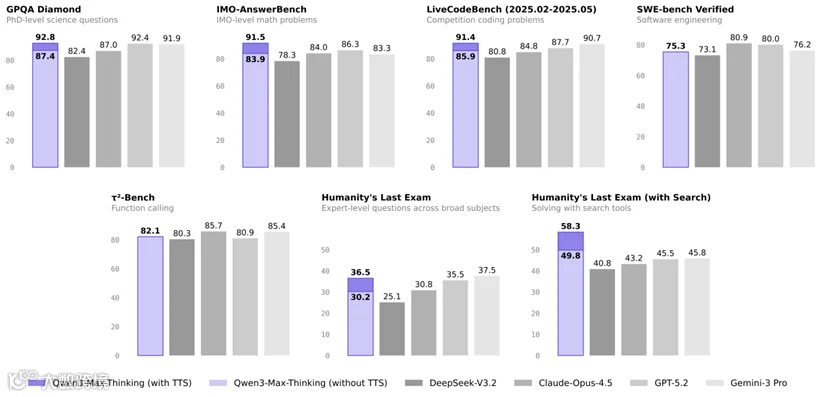
② 通义千问推出 Qwen3-Max-Thinking,推理能力对标国际顶尖模型
阿里通义团队昨日正式上线旗舰推理模型 Qwen3-Max-Thinking。该模型在19项主流基准测试中达到国际领先水平,平均评测得分已接近 Gemini 3 Pro、GPT‑5.2 Thinking、Claude‑Opus‑4.5,部分任务实现超越。
核心创新
自适应工具调用:可根据对话内容自主判断并调用搜索引擎、代码解释器等工具,无需手动指定。
经验驱动的测试时扩展:通过迭代式自我反思提炼“经验摘要”,指导后续推理,在几乎不增加token消耗的情况下提升效率。
模型已在 Qwen Chat(仍显示为Qwen3‑Max)上线,开发者可通过百炼平台调用API,接口兼容 OpenAI 与 Anthropic 协议。
短评
测试时扩展本质是算力调度方式的转变,将推理质量与计算资源分配解耦,更适合移动端、边缘设备等高并发场景。自适应工具调用是智能体能力的深化,但强制联网搜索可能引入不可靠信息,需注意风险控制。
02
技术进展(论文/SOTA/算法)
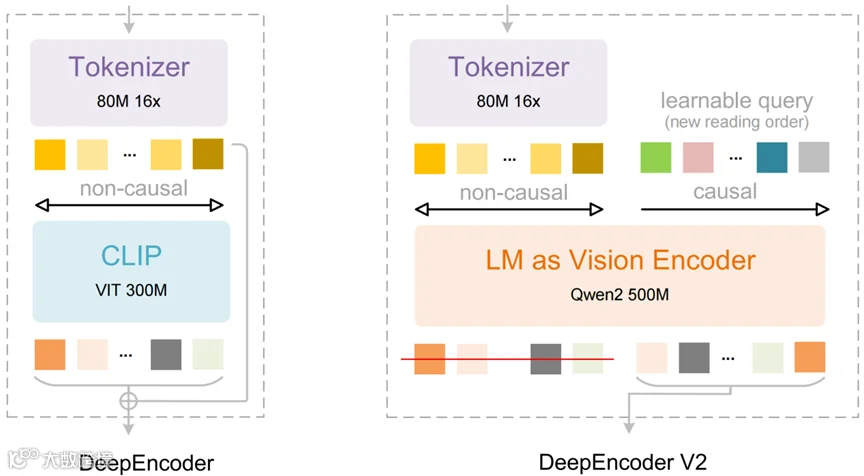
① DeepSeek 发布 OCR 2,重构视觉编码范式
DeepSeek AI 今日推出新一代光学字符识别模型 DeepSeek‑OCR 2,提出基于大语言模型架构的视觉编码器 DeepEncoder V2,可根据图像语义动态调整“阅读顺序”,更贴近人类理解复杂文档的认知方式。
方法创新
使用 Qwen2‑0.5B 架构的视觉编码器替代传统 ViT,通过“因果流查询”机制对视觉 token 进行语义重排序。
在 OmniDocBench v1.5 基准中取得 91.09% 准确率,阅读顺序指标显著提升。
模型权重与代码已开源。团队指出,该范式可通过更换不同模态的查询向量,统一处理文本、图像、语音,为原生多模态大模型提供新方向。
短评
本次发布更像技术验证Demo,社区反馈存在一定幻觉与漏识别问题。OCR 作为基础能力,仍需优先保障字符识别可靠性;过早引入LLM的“创造性”,可能影响其根本使命。
03
政策变化(监管/安全/标准/政策)
① ClawdBot 大量实例暴露无鉴权端口,安全风险凸显
近期安全研究人员发现,数百台运行 ClawdBot 的服务器将其管理端口(18789)无鉴权对外开放,攻击者可直连执行远程命令、窃取密钥等操作。

原因分析:
ClawdBot 设计用于本地或受控环境,但部分用户将其部署于公网VPS时,手动关闭了安全配置,且未设置身份验证。
短评
问题源于用户部署疏漏,非软件漏洞。AI工具低门槛普及伴随认知陷阱:许多教程为追求简便省略安全环节,用户常将“能运行”等同于“已完成”,忽视公网暴露与数据泄露风险。
② 豆包手机助手发布隐私声明:承诺不存储、不训练用户数据
字节跳动旗下 豆包手机助手 昨日发布隐私声明,强调仅在用户授权下调用必要能力,承诺云端不存储数据、不用于训练,并对传输全程加密。

短评
声明仍停留在原则层面,未披露可验证的技术机制。个性化智能与数据隐私在当前技术路径下存在天然张力——完全放弃用户数据,模型在推荐、上下文理解等能力上的提升将受限。
04
算力与基础设施
① 国星宇航启动“星算”计划,构建太空算力网络
商业航天企业 国星宇航 在“星算·智联”研讨会上公布,将部署由 2800颗卫星 组成的低轨太空算力网络,为自动驾驶、机器人等智能体提供在轨实时训练与推理能力。
进展与规划
2025年11月已完成 Qwen3 在轨端到端推理验证,响应时间不足2分钟。
已获国际电联批准的频率轨道资源,计划2030年前规模组网,2035年全面建成,提供十万P级推理算力与百万P级训练算力。
短评
该计划有助于在太空算力赛道维护数据主权与安全,并为移动智能体提供低延迟通信支持。商业化前景仍待验证——自动驾驶等企业是否愿为太空算力支付溢价,取决于成本与收益的匹配度。