

维吾尔文是我国新疆维吾尔自治区的主要文字之一,属于阿拉伯字母体系的拼音文字,广泛应用于行政、教育、新闻出版、文化传承等领域。随着数字化时代的到来,维吾尔文文档的电子化需求日益增长,例如:政府公文数字化、教育资料电子化、古籍保护、移动应用。
然而,由于维吾尔文的连写特性、多变字体、复杂上下文依赖,传统OCR技术对其识别准确率较低。近年来,随着深度学习和多语言OCR技术的发展,维吾尔文OCR的识别能力显著提升。
中科逸视维吾尔文OCR产品是一款基于人工智能和深度学习技术的维吾尔文光学字符识别工具,能够快速、准确地将印刷体或手写体维吾尔文转换为可编辑、可搜索的数字化文本。该产品适用于政府、教育、出版、金融等多个行业,助力维吾尔文信息的高效处理与智能化管理。

技术原理
1. 维吾尔文OCR的核心流程
维吾尔文OCR的识别过程主要包括以下几个关键步骤:
(1)图像预处理
去噪与二值化:去除扫描或拍摄时产生的背景干扰,转换为黑白图像以提高对比度。
倾斜校正:检测文本行的倾斜角度并自动旋转校正(如基于Hough变换或深度学习的方法)。
光照均衡化:解决因拍摄光线不均导致的识别困难(如CLAHE算法)。
(2)文本检测(Text Detection)
传统方法:使用滑动窗口、连通域分析(如MSER)定位文本区域。
深度学习方法:
CTPN(Connectionist Text Proposal Network):适用于水平文本检测。
EAST(Efficient and Accurate Scene Text Detector):可检测多方向文本。
DBNet(Differentiable Binarization Network):基于分割的文本检测,适合复杂背景。
(3)字符识别(Text Recognition)
传统方法:特征提取(如HOG、LBP)+ 分类器(SVM、KNN),但泛化能力较差。
深度学习方法:
CNN(卷积神经网络):提取字符的局部特征(如ResNet、MobileNet)。
RNN/LSTM(循环神经网络):处理维吾尔文的连写序列依赖(一个字母在不同位置可能呈现不同形态)。
Transformer OCR:基于自注意力机制(如TrOCR、PARSeq),提升长文本识别能力。
端到端模型:CRNN(CNN+RNN+CTC)或Attention OCR,直接输出识别结果。
(4)后处理优化
拼写校正:基于维吾尔语语法规则或N-gram语言模型修正错误(如混淆"ﺱ"和"ﺵ")。
上下文建模:利用BERT-like预训练模型(如UyghurBERT)提升语义准确性。
-
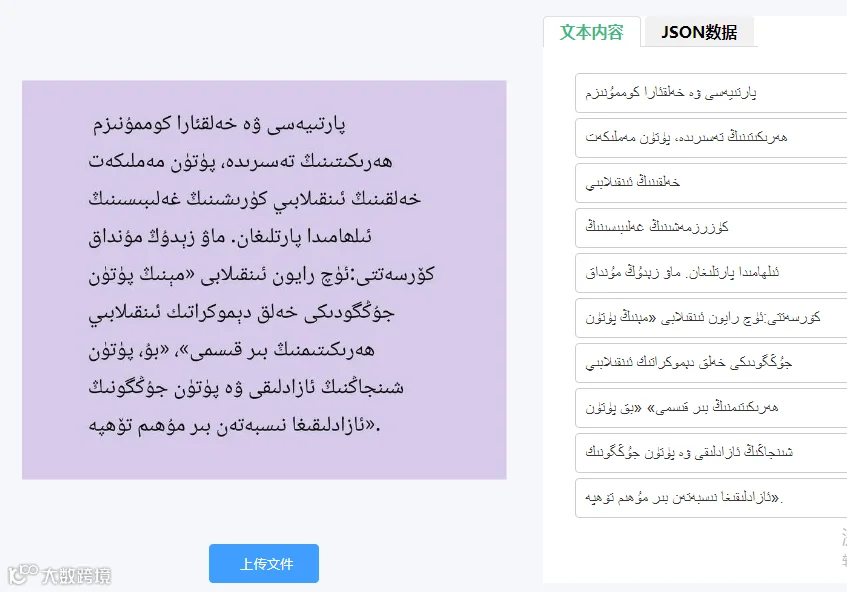
功能特点
1. 高精度识别
对印刷体维吾尔文的识别准确率可达95%以上。
支持多语言混合识别(维吾尔文+中文)。
2. 多场景适配
文档识别:支持扫描件、PDF、图片(JPG/PNG)输入,自动矫正扭曲文本。
古籍识别:针对老维吾尔文(如察合台文)优化,结合超分辨率技术提升清晰度。
3. 跨平台支持
提供Windows、Android、iOS、Web端、国产化平台应用,支持API接口集成。
- 支持离线模式,保障数据安全。
应用场景
政务办公:公文扫描、档案电子化管理。
教育领域:教材数字化、试卷自动批改。
新闻出版:报纸、书籍的快速录入与电子化。
金融法律:身份证、合同等文档的自动化处理。
文化遗产保护:察合台文古籍的数字化存档。
体验地址:ai.casai.cn
关注公众号,了解更多OCR知识