
在全球化和数字化加速发展的背景下,法语作为全球29个国家的官方语言(如法国、加拿大、瑞士及部分非洲国家),其文本的数字化需求日益增长。传统的人工录入方式效率低、成本高,而中科逸视法语OCR(Optical Character Recognition,光学字符识别)技术能够快速、准确地将纸质或图像中的法语文本转换为可编辑、可搜索的电子数据,广泛应用于教育、法律、商业和公共服务等领域。

工作原理
法语OCR技术的核心流程主要包括以下几个步骤:
图像采集与预处理
通过扫描仪、相机或移动设备获取文本图像。
进行去噪、二值化、倾斜校正、对比度增强等优化,提高识别准确率。
文本检测与定位
使用深度学习模型(如CNN、YOLO、EAST)检测图像中的文本区域,区分文字、表格和背景。
字符识别
采用序列识别模型(如CRNN、LSTM)或端到端模型(如TrOCR、PaddleOCR)逐字符或逐行识别法语文本。
特别优化法语特殊字符(如 é, ç, œ, ù)和连字(如“攓œ”)的识别。
后处理与语义优化
结合法语词典、语法规则和NLP技术校正拼写错误,提高文本可读性。
输出结构化数据(如Excel表格)或可编辑文本(如Word、PDF)。
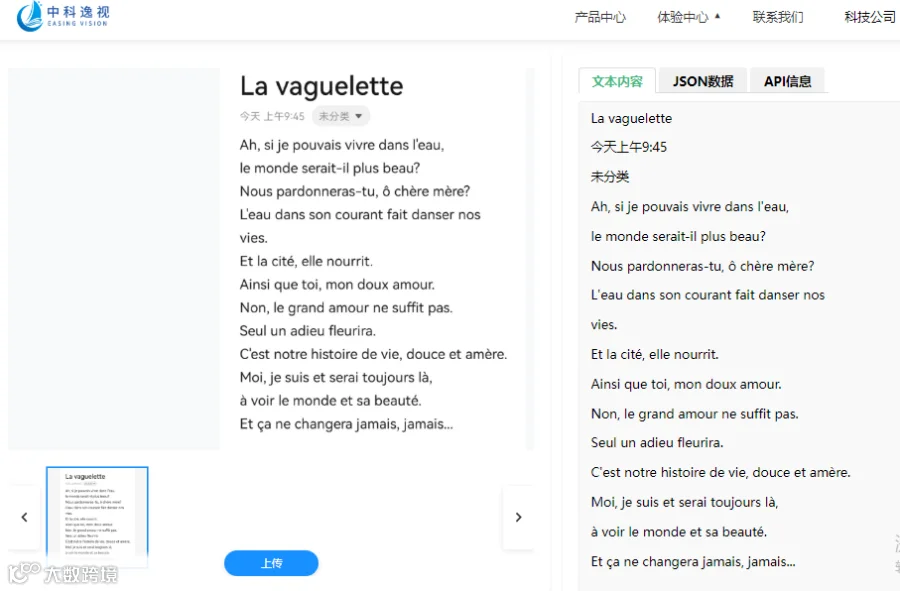
功能特点
高精度识别:
支持印刷体、手写体(需专项训练)及复杂版式(表格、多栏文本、中法文混排)。
语言适配:
针对法语特殊符号、连字(如“æ”)和重音符号优化,识别率可达95%以上。
多格式输出:
生成可编辑的文本(TXT、DOCX)、结构化数据(Excel)或搜索友好的PDF。
法语OCR的技术难点
复杂版式处理
法语文档可能包含多栏排版、表格、手写批注等,传统OCR难以精准分割。
特殊字符与多语言混合
法语常与英语、阿拉伯语等混排(如北非法语文件),需支持多语言切换识别。
低质量图像识别
老旧文档、模糊照片或低分辨率扫描件影响识别精度。
手写体识别
法语手写风格多样(如连笔字),需专门训练模型。
功能特点
高精度识别
对印刷体法语的识别率可达95%以上,部分系统支持手写体(需定制训练)。
多格式支持
支持PDF、JPG、PNG等输入,输出TXT、DOCX、Excel等可编辑格式。
多语言扩展
可切换英语、西班牙语等模式,适应双语文档需求。
应用领域
教育文化
数字化法语古籍、教材,助力语言研究和在线教育。
商业与法律
自动录入合同、发票,提升跨境业务效率;司法机构快速处理法语卷宗。
公共服务
机场、海关OCR识别护照、签证信息,加速出入境流程。