

-
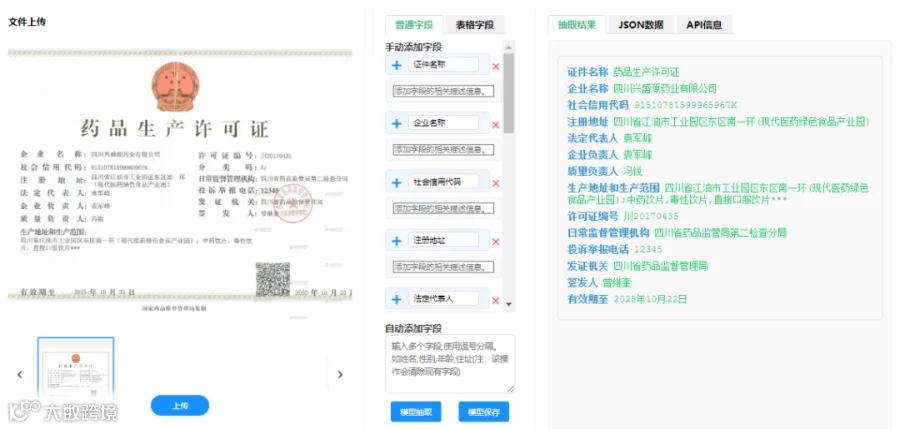
格式解析:首先,系统需要处理多种格式的文档,如PDF、Word、扫描图像等。对于扫描件,会先使用OCR技术将图像转换为可编辑的文本。对于原生电子文档,则直接提取文本和布局信息(如段落、表格、字体等)。 -
文本清理:对提取出的原始文本进行清理,包括去除无关字符、纠正OCR识别错误、统一编码格式等,为后续分析奠定基础。
-
人名/组织名:原告、被告、法官、律师、公司名称。 -
地点:合同履行地、侵权行为地。 -
时间:合同签署日期、诉讼时效、判决日期。 -
金额:合同标的额、赔偿金额、违约金。 -
法律条款:引用的具体法条,如“《合同法》第X条”。
-
仅仅识别实体是不够的,还需要理解实体之间的关系。例如,在合同中,需要明确“谁(甲方)向谁(乙方)支付多少金额(合同款)”。关系抽取模型会建立实体间的语义链接,形成“(甲方,支付,乙方,合同款)”这样的结构化三元组。
-
针对更复杂的场景,如从案情描述中提取关键事件。例如,从一段描述中抽取出“(被告,于XX时间,在XX地点,实施了XX侵权行为)”这样一个完整的事件框架。
-
将抽取出的信息进行标准化。例如,将“2023年十月一日”、“2023/10/01”等不同格式的日期统一为标准格式“2023-10-01”;将“人民币壹佰万元整”、“RMB 1,000,000元”统一为数字“1000000”。
-
基于机器学习/深度学习的方法:这是当前的主流。通过向模型(如BERT、RoBERTa等预训练模型)输入大量已标注的法律文本数据,让模型自动学习语言的规律和特征。这种方法泛化能力强,能处理更复杂的语言现象,但需要高质量的标注数据。
-
智能审阅:自动从海量合同中提取关键条款,如付款条件、违约责任、保密协议、管辖法院等,并与标准模板或风险清单进行比对,快速定位潜在风险点。 -
合同生成与归档:根据抽取的实体信息(如双方名称、标的额等)自动填充合同模板。完成后,将合同信息结构化存入数据库,实现基于内容的快速检索和分析(如“查找所有违约金超过100万的合同”)。
-
在并购、融资等项目中,律师需要审查目标公司的大量法律文件(如过往合同、产权证明、诉讼记录)。文档抽取技术可以批量自动化处理这些文件,快速生成关于公司义务、资产状况、潜在诉讼风险的综合报告,将数周的工作缩短至数天。
-
证据材料梳理:从大量的电子邮件、聊天记录、财务报告中快速提取与案件相关的人、事、时、地、物等关键信息,形成证据链索引。 -
案例研究与分析:自动从历史判决文书中抽取“案由”、“争议焦点”、“法院观点”、“判决结果”等核心要素。律师可以据此进行精准的类案检索,预测诉讼结果,制定更优的辩护策略。
-
法规追踪与解读:自动从新颁布的法律法规中提取适用范围、核心义务、处罚措施等要点,并及时通知相关企业。 -
内部合规审查:检查公司内部文件(如宣传材料、员工手册)是否符合最新监管要求,避免合规风险。
-
自动化处理替代了大量重复、繁琐的人工阅读和录入工作,将律师从文书工作中解放出来,使其能专注于更高价值的战略分析、法庭辩论和客户沟通。这直接降低了人力成本,并大幅缩短了项目周期。
-
人类在长时间阅读大量文档时难免会出现疏漏和疲劳错误。AI系统则能保持稳定的“注意力”,确保不放过任何一个关键条款或数据点,审查覆盖率达100%,显著降低了因人为疏忽导致的风险。
-
通过将海量非结构化文档转化为结构化数据,律所和企业得以构建自己的“法律知识图谱”。这使得基于数据的深度分析成为可能,例如:分析特定法官的判决倾向、总结某类合同的高发风险点、评估诉讼策略的成功率等,从而实现真正的数据驱动决策。
-
通过前置的风险自动识别和预警,企业法务和律师能够在签署合同或开展业务前就发现潜在的法律陷阱,实现从“事后补救”到“事前预防”的转变,从根本上提升了企业的风险抵御能力。