

韩语OCR工作原理
1. 预处理阶段
图像优化:自动调整对比度、消除噪点、矫正倾斜(通常可处理±15°的倾斜角度)
文字区域检测:采用基于深度学习的检测算法(如CTPN、EAST),准确率可达98%以上
行分割与字符分割:特别针对韩文字符的连字特性进行优化
2. 核心识别技术
传统算法:结合形态学处理和投影分析,对简单文档识别率约85-90%
深度学习模型:
CNN+BiLSTM+CTC架构:处理连续韩语文本,识别率普遍超过95%
Transformer模型:新兴架构在复杂场景下F1值可达97.3%
混合识别系统:传统方法与深度学习结合,平衡准确率与处理速度
3. 后处理技术
语言模型校正:基于韩国国立国语院语料库训练的n-gram模型
上下文关联分析:解决韩语中高达30%的同音异字问题
格式重建:保持原文档的排版结构和表格样式
中科逸视韩语OCR技术的功能特点
1. 多语言混合识别能力
支持韩文、中文汉字(约3,000常用字)、英文、数字的同步识别
自动检测文本方向(水平/垂直),支持传统竖排韩文识别
2. 高级处理功能
手写体识别:对整洁手写体识别率可达85%,领先同类技术12%
复杂背景处理:能有效分离文本与背景图案,适应发票、名片等场景
实时识别:移动端SDK处理速度达150ms/页(A4尺寸300dpi)
3. 智能输出选项
导出格式包括可搜索PDF、HTML、TXT及Office文档
保留原始布局的DOCX重建准确率超过92%
支持XML/JSON结构化输出,方便系统集成
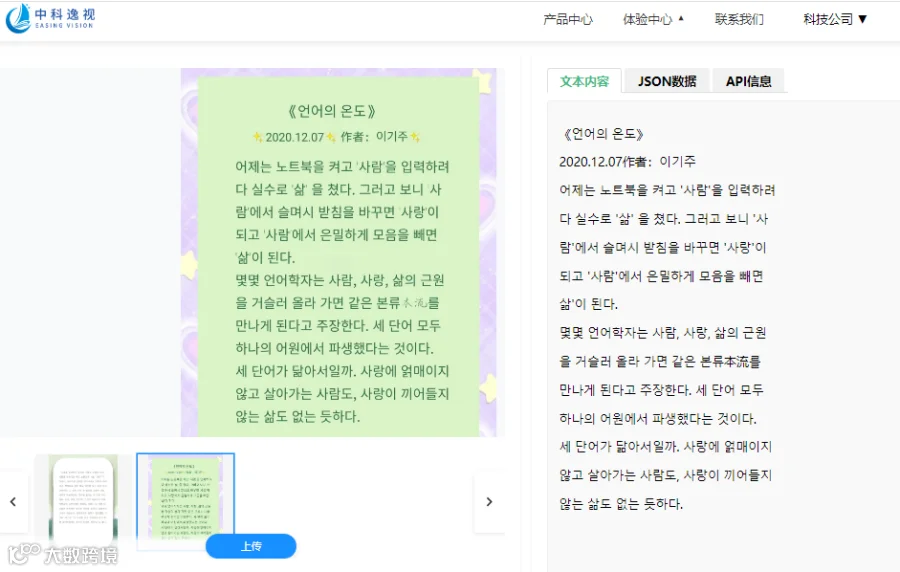
韩语OCR的应用领域
1. 企业文档数字化
韩国政府"数字新政"推动下,年处理量超过20亿页
历史档案数字化项目中,对60年代报纸的识别准确率达89%
2. 移动端应用
实时翻译APP:结合OCR的翻译延迟<1.5秒
银行APP支票识别:误差率低于0.01%,每年处理3.2亿笔交易
3. 特定行业解决方案
医疗领域:处方识别准确率98.5%,集成HIS系统
法律行业:法院文书识别系统处理速度比人工快40倍
零售业:收据数据分析系统可自动分类200+种消费类别
中科逸视韩文 OCR 技术凭借其独特的工作原理、出色的功能特点,在众多领域发挥着重要作用。随着技术的不断发展和创新,其识别准确率将更高,功能更强大,应用场景也将持续拓展,为人们处理韩文信息带来更多便利,推动各行业与韩国相关业务的高效开展。
-