

-
环境依赖性强:光线、角度、摄像头质量等因素会严重影响检测精度。 -
对抗样本攻击:随着AI生成技术(如Deepfake)的进步,伪造的图片和视频越来越难以被静态分析所甄别。 -
难以防御高精度3D攻击:高质量的硅胶面具或头套可以完美复刻人脸的三维结构,欺骗大多数仅依赖纹理分析的模型。
-
动作完整性验证:算法首先检测视频中的人脸,并追踪其关键点(如眼睛、嘴巴、头部姿态)的运动轨迹。判断用户是否准确、完整地执行了所有指令动作。 -
活体特征分析:在用户动作的过程中,系统会同步分析每一帧画面中的活体特征,例如:眨眼时眼球的细微移动、张嘴时牙齿和口腔内部的自然结构、头部转动时面部光影的连续自然变化等。这些特征是照片或视频无法同时、自然复现的。
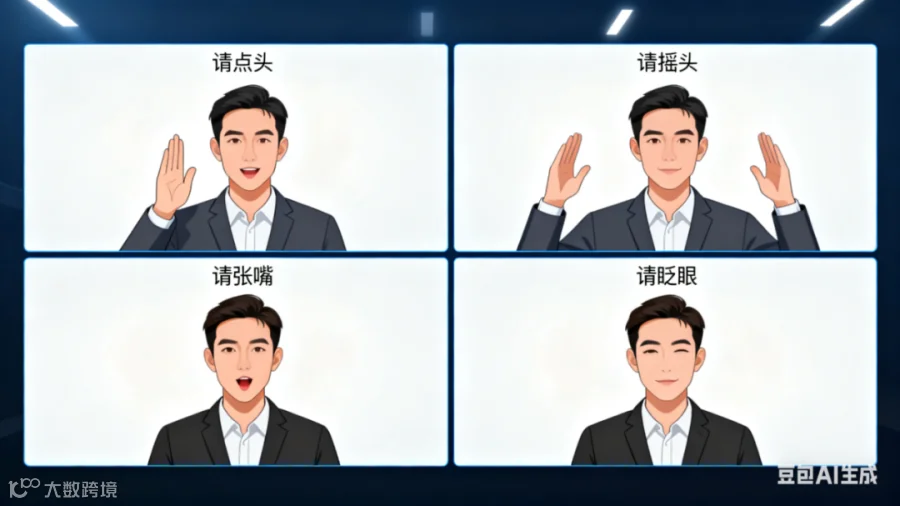
-
极高的防伪能力:该技术有效防御了所有形式的2D静态攻击(打印照片、电子屏幕照片)。因为一张静态图片无法完成动态指令。同时,它也极大地增加了3D面具攻击的难度,攻击者需要制作一个能精密模拟所有随机动作的高仿真面具,其成本和技术门槛极高,几乎不可行。 -
主动随机性,难以预测:每次认证的指令序列都是随机组合的(如“眨眼-点头-张嘴”或“左转-眨眼”),有效避免了攻击者通过录制用户视频进行重放攻击的可能。 -
用户体验与安全性的平衡:相较于虹膜、指纹等生物识别,人脸动作指令非常直观自然,用户学习成本几乎为零。整个过程通常在2-5秒内即可完成,在实现极高安全等级的同时,保证了流畅的用户体验。 -
多模态融合增强安全性:最新的技术趋势是将动作指令与其他活体检测技术相结合。例如,在用户执行动作时,同时进行微纹理分析、红外活体检测或3D结构光深度检测,形成多重安全验证,构建起坚不可摧的“护城河”。